 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative, Deep Synthetic Aperture Sonar Image Segmentation
Mar 28, 2022
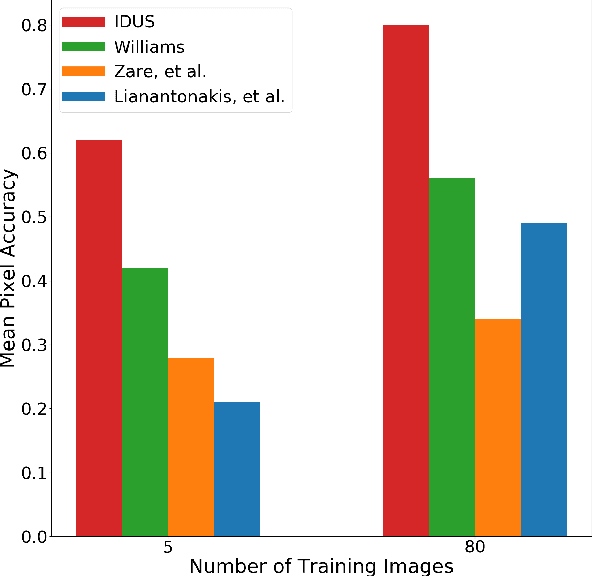
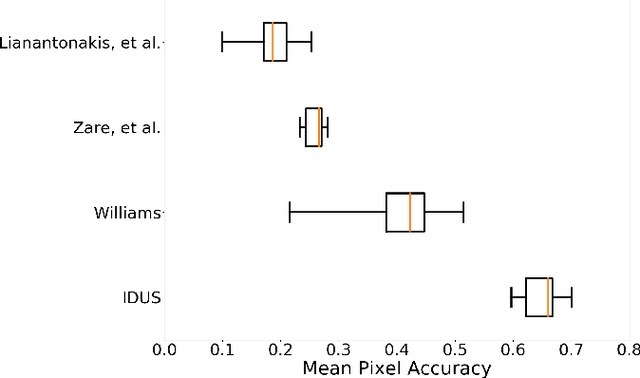
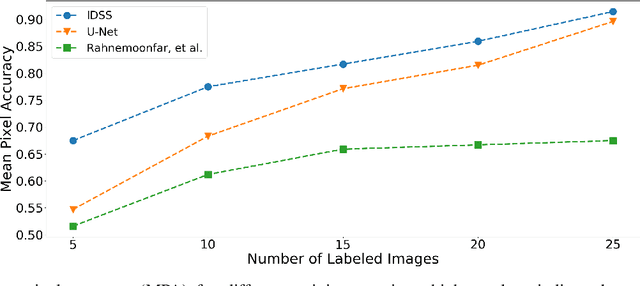
Synthetic aperture sonar (SAS) systems produce high-resolution images of the seabed environment. Moreover, deep learning has demonstrated superior ability in finding robust features for automating imagery analysis. However, the success of deep learning is conditioned on having lots of labeled training data, but obtaining generous pixel-level annotations of SAS imagery is often practically infeasible. This challenge has thus far limited the adoption of deep learning methods for SAS segmentation. Algorithms exist to segment SAS imagery in an unsupervised manner, but they lack the benefit of state-of-the-art learning methods and the results present significant room for improvement. In view of the above, we propose a new iterative algorithm for unsupervised SAS image segmentation combining superpixel formation, deep learning, and traditional clustering methods. We call our method Iterative Deep Unsupervised Segmentation (IDUS). IDUS is an unsupervised learning framework that can be divided into four main steps: 1) A deep network estimates class assignments. 2) Low-level image features from the deep network are clustered into superpixels. 3) Superpixels are clustered into class assignments (which we call pseudo-labels) using $k$-means. 4) Resulting pseudo-labels are used for loss backpropagation of the deep network prediction. These four steps are performed iteratively until convergence. A comparison of IDUS to current state-of-the-art methods on a realistic benchmark dataset for SAS image segmentation demonstrates the benefits of our proposal even as the IDUS incurs a much lower computational burden during inference (actual labeling of a test image). Finally, we also develop a semi-supervised (SS) extension of IDUS called IDSS and demonstrate experimentally that it can further enhance performance while outperforming supervised alternatives that exploit the same labeled training imagery.
Iterative, Deep, and Unsupervised Synthetic Aperture Sonar Image Segmentation
Jul 30, 2021
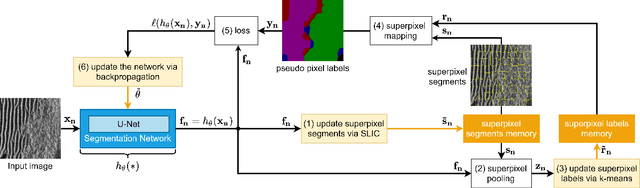

Deep learning has not been routinely employed for semantic segmentation of seabed environment for synthetic aperture sonar (SAS) imagery due to the implicit need of abundant training data such methods necessitate. Abundant training data, specifically pixel-level labels for all images, is usually not available for SAS imagery due to the complex logistics (e.g., diver survey, chase boat, precision position information) needed for obtaining accurate ground-truth. Many hand-crafted feature based algorithms have been proposed to segment SAS in an unsupervised fashion. However, there is still room for improvement as the feature extraction step of these methods is fixed. In this work, we present a new iterative unsupervised algorithm for learning deep features for SAS image segmentation. Our proposed algorithm alternates between clustering superpixels and updating the parameters of a convolutional neural network (CNN) so that the feature extraction for image segmentation can be optimized. We demonstrate the efficacy of our method on a realistic benchmark dataset. Our results show that the performance of our proposed method is considerably better than current state-of-the-art methods in SAS image segmentation.
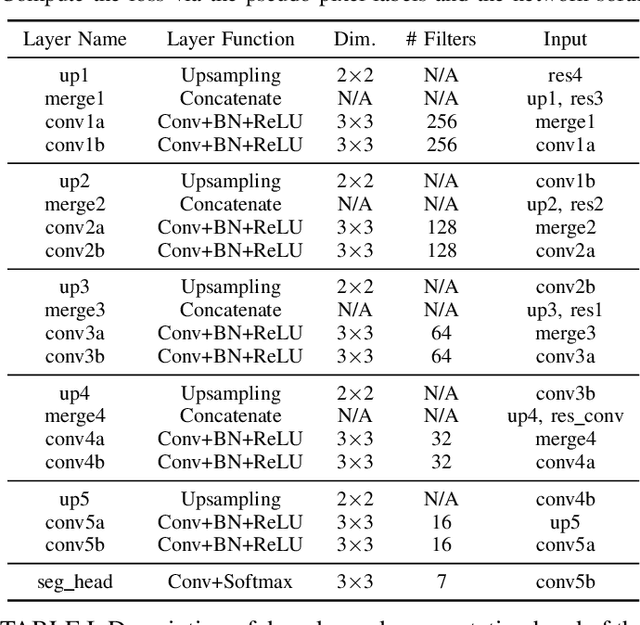
Multi-Class Micro-CT Image Segmentation Using Sparse Regularized Deep Networks
Apr 21, 2021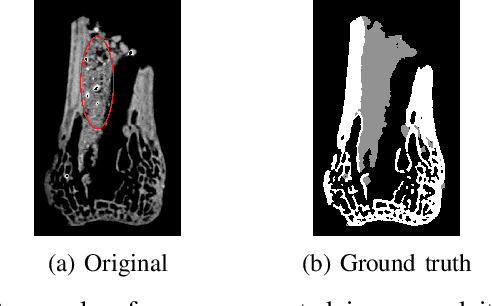

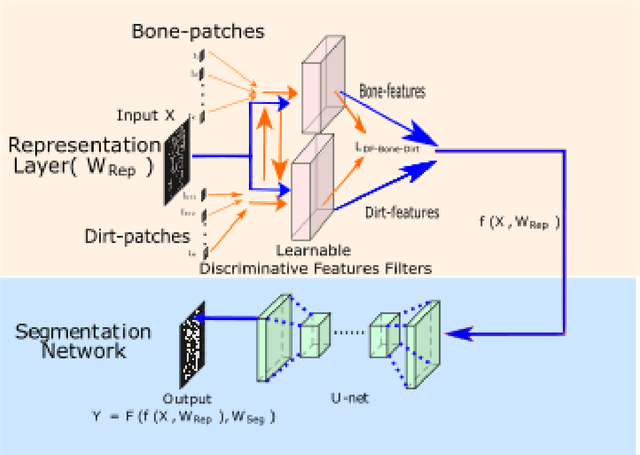
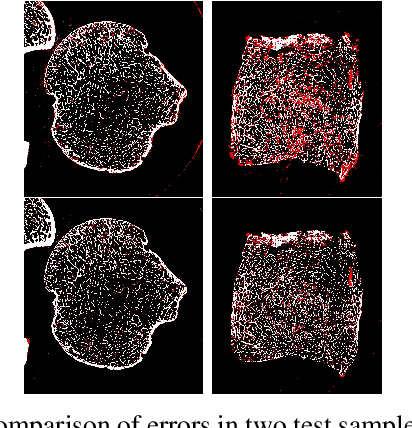
It is common in anthropology and paleontology to address questions about extant and extinct species through the quantification of osteological features observable in micro-computed tomographic (micro-CT) scans. In cases where remains were buried, the grey values present in these scans may be classified as belonging to air, dirt, or bone. While various intensity-based methods have been proposed to segment scans into these classes, it is often the case that intensity values for dirt and bone are nearly indistinguishable. In these instances, scientists resort to laborious manual segmentation, which does not scale well in practice when a large number of scans are to be analyzed. Here we present a new domain-enriched network for three-class image segmentation, which utilizes the domain knowledge of experts familiar with manually segmenting bone and dirt structures. More precisely, our novel structure consists of two components: 1) a representation network trained on special samples based on newly designed custom loss terms, which extracts discriminative bone and dirt features, 2) and a segmentation network that leverages these extracted discriminative features. These two parts are jointly trained in order to optimize the segmentation performance. A comparison of our network to that of the current state-of-the-art U-NETs demonstrates the benefits of our proposal, particularly when the number of labeled training images are limited, which is invariably the case for micro-CT segmentation.