 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaturity-Aware Active Learning for Semantic Segmentation with Hierarchically-Adaptive Sample Assessment
Aug 28, 2023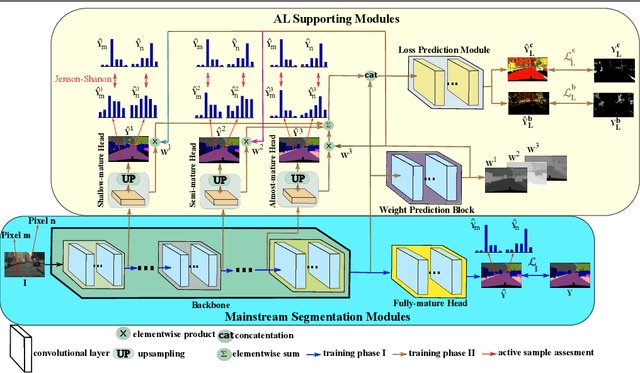
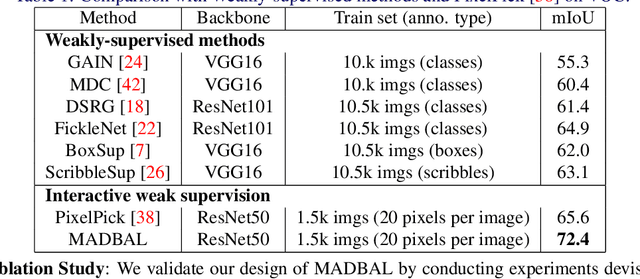
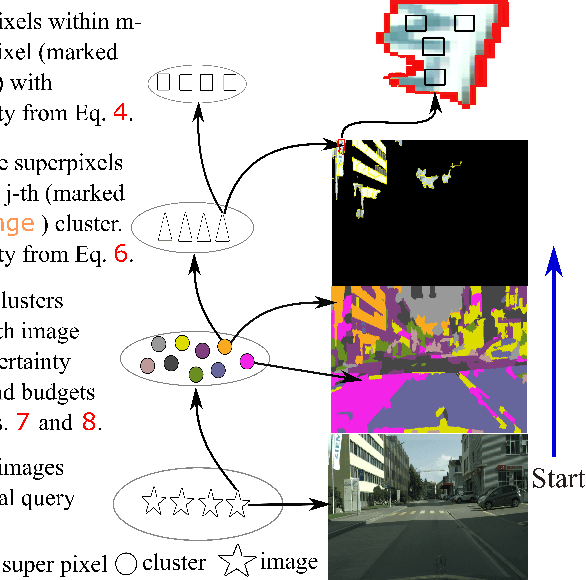
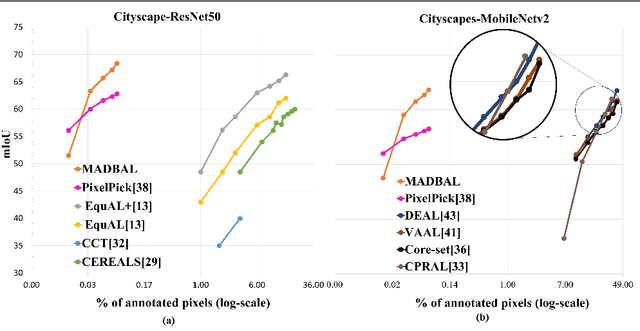
Active Learning (AL) for semantic segmentation is challenging due to heavy class imbalance and different ways of defining "sample" (pixels, areas, etc.), leaving the interpretation of the data distribution ambiguous. We propose "Maturity-Aware Distribution Breakdown-based Active Learning'' (MADBAL), an AL method that benefits from a hierarchical approach to define a multiview data distribution, which takes into account the different "sample" definitions jointly, hence able to select the most impactful segmentation pixels with comprehensive understanding. MADBAL also features a novel uncertainty formulation, where AL supporting modules are included to sense the features' maturity whose weighted influence continuously contributes to the uncertainty detection. In this way, MADBAL makes significant performance leaps even in the early AL stage, hence reducing the training burden significantly. It outperforms state-of-the-art methods on Cityscapes and PASCAL VOC datasets as verified in our extensive experiments.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Physically Inspired Dense Fusion Networks for Relighting
May 05, 2021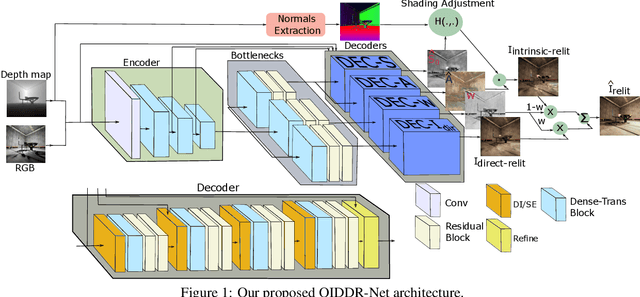

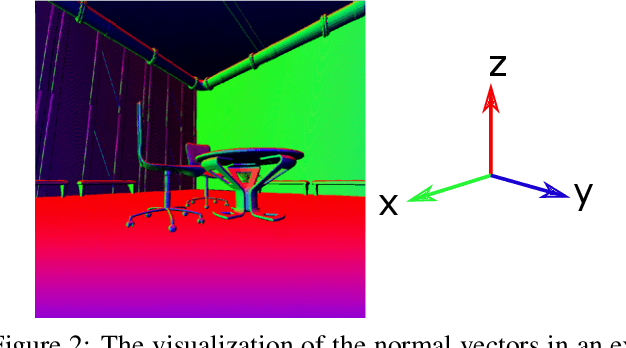

Image relighting has emerged as a problem of significant research interest inspired by augmented reality applications. Physics-based traditional methods, as well as black box deep learning models, have been developed. The existing deep networks have exploited training to achieve a new state of the art; however, they may perform poorly when training is limited or does not represent problem phenomenology, such as the addition or removal of dense shadows. We propose a model which enriches neural networks with physical insight. More precisely, our method generates the relighted image with new illumination settings via two different strategies and subsequently fuses them using a weight map (w). In the first strategy, our model predicts the material reflectance parameters (albedo) and illumination/geometry parameters of the scene (shading) for the relit image (we refer to this strategy as intrinsic image decomposition (IID)). The second strategy is solely based on the black box approach, where the model optimizes its weights based on the ground-truth images and the loss terms in the training stage and generates the relit output directly (we refer to this strategy as direct). While our proposed method applies to both one-to-one and any-to-any relighting problems, for each case we introduce problem-specific components that enrich the model performance: 1) For one-to-one relighting we incorporate normal vectors of the surfaces in the scene to adjust gloss and shadows accordingly in the image. 2) For any-to-any relighting, we propose an additional multiscale block to the architecture to enhance feature extraction. Experimental results on the VIDIT 2020 and the VIDIT 2021 dataset (used in the NTIRE 2021 relighting challenge) reveals that our proposal can outperform many state-of-the-art methods in terms of well-known fidelity metrics and perceptual loss.
Simultaneous Denoising and Localization Network for Photoacoustic Target Localization
Apr 30, 2021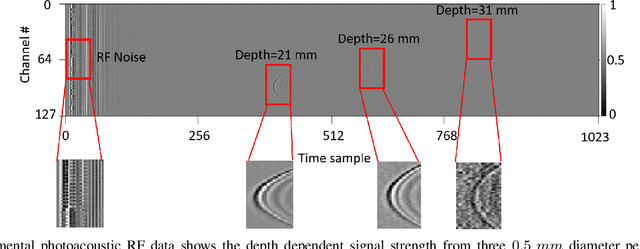
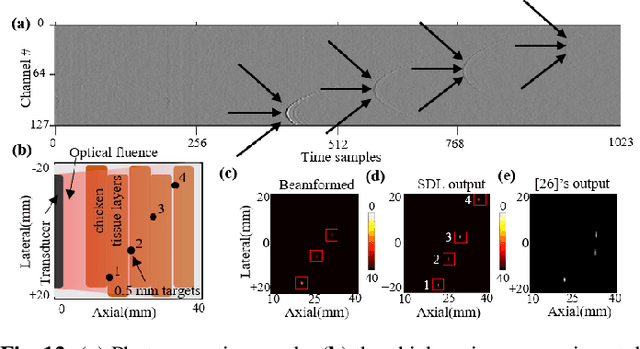
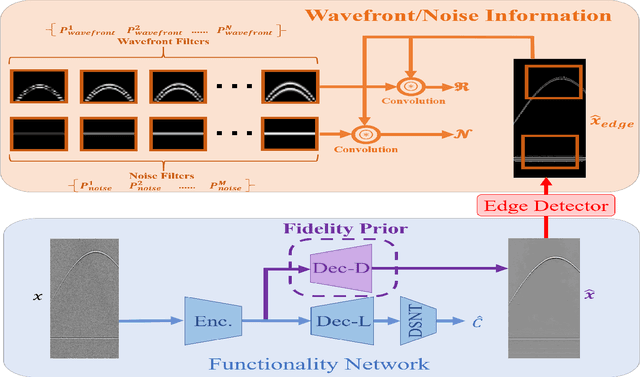
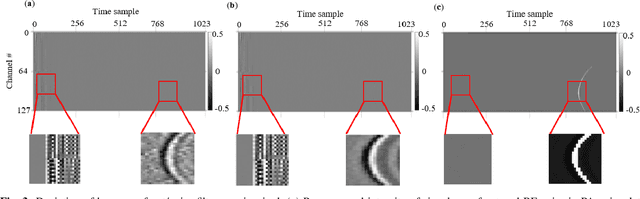
A significant research problem of recent interest is the localization of targets like vessels, surgical needles, and tumors in photoacoustic (PA) images. To achieve accurate localization, a high photoacoustic signal-to-noise ratio (SNR) is required. However, this is not guaranteed for deep targets, as optical scattering causes an exponential decay in optical fluence with respect to tissue depth. To address this, we develop a novel deep learning method designed to explicitly exhibit robustness to noise present in photoacoustic radio-frequency (RF) data. More precisely, we describe and evaluate a deep neural network architecture consisting of a shared encoder and two parallel decoders. One decoder extracts the target coordinates from the input RF data while the other boosts the SNR and estimates clean RF data. The joint optimization of the shared encoder and dual decoders lends significant noise robustness to the features extracted by the encoder, which in turn enables the network to contain detailed information about deep targets that may be obscured by noise. Additional custom layers and newly proposed regularizers in the training loss function (designed based on observed RF data signal and noise behavior) serve to increase the SNR in the cleaned RF output and improve model performance. To account for depth-dependent strong optical scattering, our network was trained with simulated photoacoustic datasets of targets embedded at different depths inside tissue media of different scattering levels. The network trained on this novel dataset accurately locates targets in experimental PA data that is clinically relevant with respect to the localization of vessels, needles, or brachytherapy seeds. We verify the merits of the proposed architecture by outperforming the state of the art on both simulated and experimental datasets.
Multi-Class Micro-CT Image Segmentation Using Sparse Regularized Deep Networks
Apr 21, 2021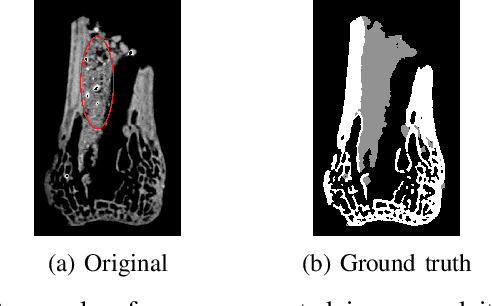

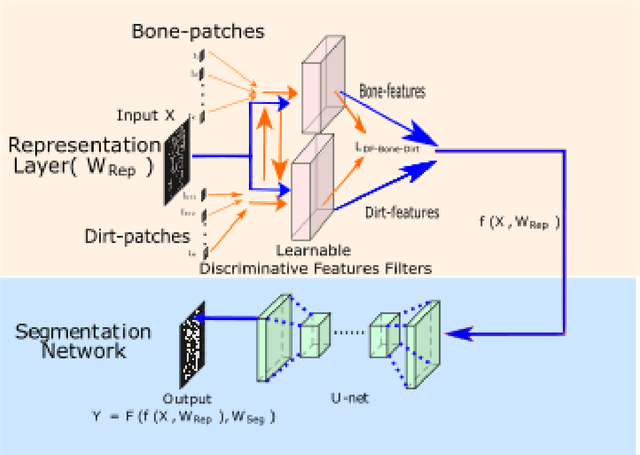
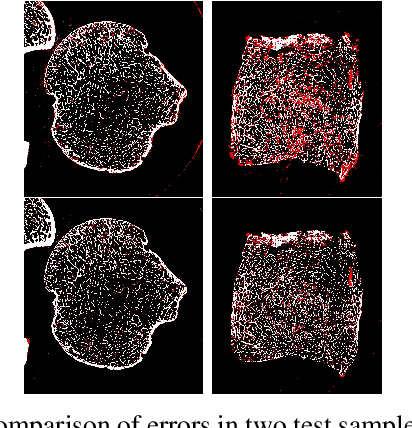
It is common in anthropology and paleontology to address questions about extant and extinct species through the quantification of osteological features observable in micro-computed tomographic (micro-CT) scans. In cases where remains were buried, the grey values present in these scans may be classified as belonging to air, dirt, or bone. While various intensity-based methods have been proposed to segment scans into these classes, it is often the case that intensity values for dirt and bone are nearly indistinguishable. In these instances, scientists resort to laborious manual segmentation, which does not scale well in practice when a large number of scans are to be analyzed. Here we present a new domain-enriched network for three-class image segmentation, which utilizes the domain knowledge of experts familiar with manually segmenting bone and dirt structures. More precisely, our novel structure consists of two components: 1) a representation network trained on special samples based on newly designed custom loss terms, which extracts discriminative bone and dirt features, 2) and a segmentation network that leverages these extracted discriminative features. These two parts are jointly trained in order to optimize the segmentation performance. A comparison of our network to that of the current state-of-the-art U-NETs demonstrates the benefits of our proposal, particularly when the number of labeled training images are limited, which is invariably the case for micro-CT segmentation.