 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Learning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Simultaneous Denoising and Localization Network for Photoacoustic Target Localization
Apr 30, 2021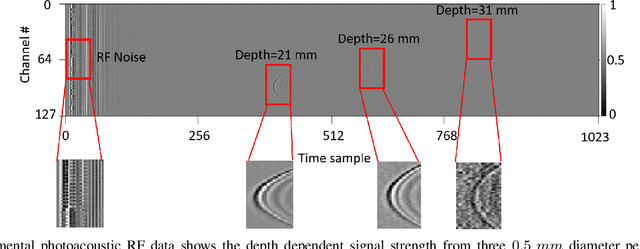
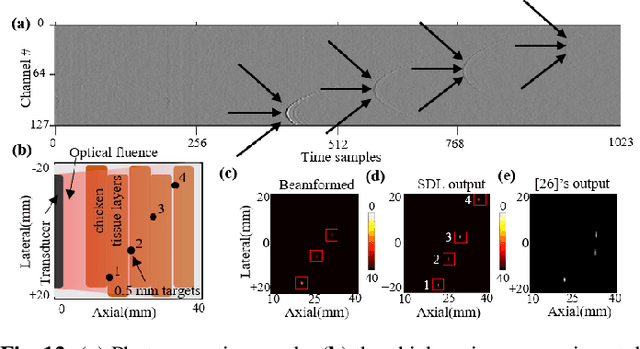
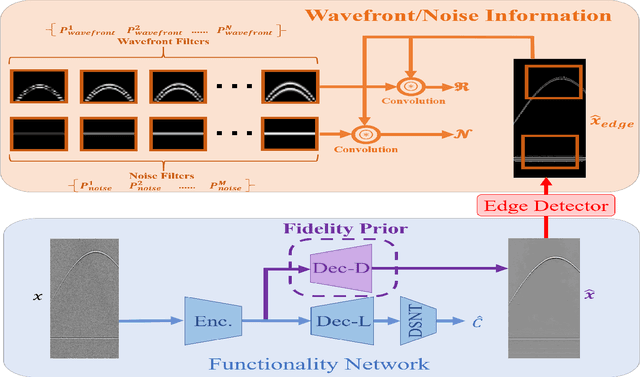
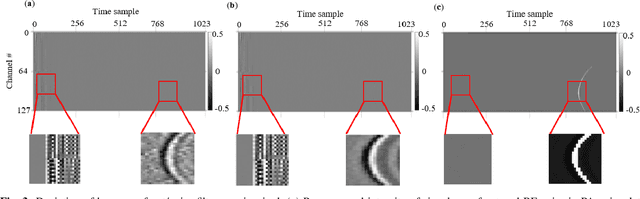
A significant research problem of recent interest is the localization of targets like vessels, surgical needles, and tumors in photoacoustic (PA) images. To achieve accurate localization, a high photoacoustic signal-to-noise ratio (SNR) is required. However, this is not guaranteed for deep targets, as optical scattering causes an exponential decay in optical fluence with respect to tissue depth. To address this, we develop a novel deep learning method designed to explicitly exhibit robustness to noise present in photoacoustic radio-frequency (RF) data. More precisely, we describe and evaluate a deep neural network architecture consisting of a shared encoder and two parallel decoders. One decoder extracts the target coordinates from the input RF data while the other boosts the SNR and estimates clean RF data. The joint optimization of the shared encoder and dual decoders lends significant noise robustness to the features extracted by the encoder, which in turn enables the network to contain detailed information about deep targets that may be obscured by noise. Additional custom layers and newly proposed regularizers in the training loss function (designed based on observed RF data signal and noise behavior) serve to increase the SNR in the cleaned RF output and improve model performance. To account for depth-dependent strong optical scattering, our network was trained with simulated photoacoustic datasets of targets embedded at different depths inside tissue media of different scattering levels. The network trained on this novel dataset accurately locates targets in experimental PA data that is clinically relevant with respect to the localization of vessels, needles, or brachytherapy seeds. We verify the merits of the proposed architecture by outperforming the state of the art on both simulated and experimental datasets.