 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Online simulator-based experimental design for cognitive model selection
Mar 03, 2023The problem of model selection with a limited number of experimental trials has received considerable attention in cognitive science, where the role of experiments is to discriminate between theories expressed as computational models. Research on this subject has mostly been restricted to optimal experiment design with analytically tractable models. However, cognitive models of increasing complexity, with intractable likelihoods, are becoming more commonplace. In this paper, we propose BOSMOS: an approach to experimental design that can select between computational models without tractable likelihoods. It does so in a data-efficient manner, by sequentially and adaptively generating informative experiments. In contrast to previous approaches, we introduce a novel simulator-based utility objective for design selection, and a new approximation of the model likelihood for model selection. In simulated experiments, we demonstrate that the proposed BOSMOS technique can accurately select models in up to 2 orders of magnitude less time than existing LFI alternatives for three cognitive science tasks: memory retention, sequential signal detection and risky choice.
Interactive Causal Structure Discovery in Earth System Sciences
Jul 01, 2021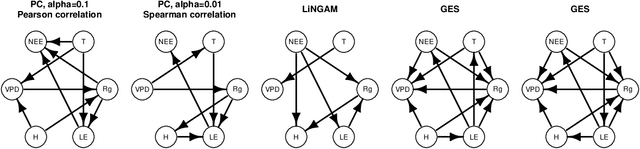
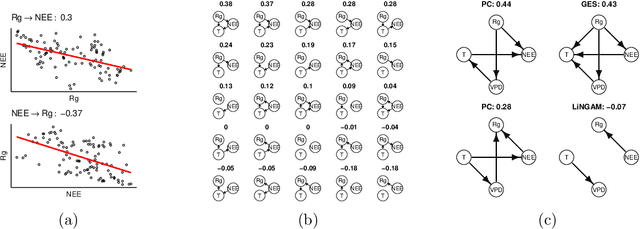
Causal structure discovery (CSD) models are making inroads into several domains, including Earth system sciences. Their widespread adaptation is however hampered by the fact that the resulting models often do not take into account the domain knowledge of the experts and that it is often necessary to modify the resulting models iteratively. We present a workflow that is required to take this knowledge into account and to apply CSD algorithms in Earth system sciences. At the same time, we describe open research questions that still need to be addressed. We present a way to interactively modify the outputs of the CSD algorithms and argue that the user interaction can be modelled as a greedy finding of the local maximum-a-posteriori solution of the likelihood function, which is composed of the likelihood of the causal model and the prior distribution representing the knowledge of the expert user. We use a real-world data set for examples constructed in collaboration with our co-authors, who are the domain area experts. We show that finding maximally usable causal models in the Earth system sciences or other similar domains is a difficult task which contains many interesting open research questions. We argue that taking the domain knowledge into account has a substantial effect on the final causal models discovered.