 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Filter: Improving Performance in Asynchronous On-Policy RL
Mar 02, 2026Distributed training and increasing the gradient update frequency are practical strategies to accelerate learning and improve performance, but both exacerbate a central challenge: \textit{policy lag}, which is the mismatch between the behavior policy generating data and the learning policy being updated. Policy lag can hinder the scaling of on-policy learning algorithms to larger problems. In this paper, we identify the sources of policy lag caused by distributed learning and high update frequency. We use the findings to propose \textit{total Variation-based Advantage aligned Constrained policy Optimization (\methodacronym)} as a practical approach to mitigate policy lag. We empirically validate our method and show that it offers better robustness to policy lag in classic RL tasks and a modern RL for LLM math reasoning task.
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024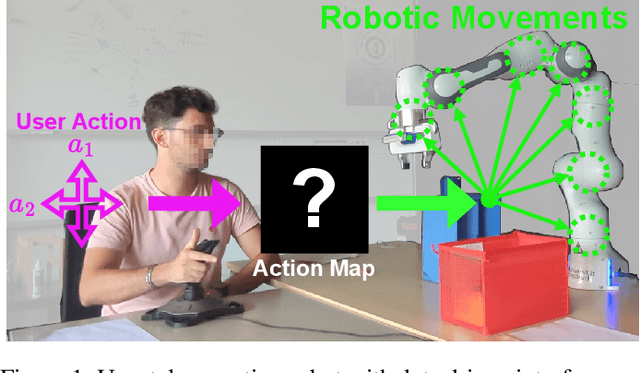

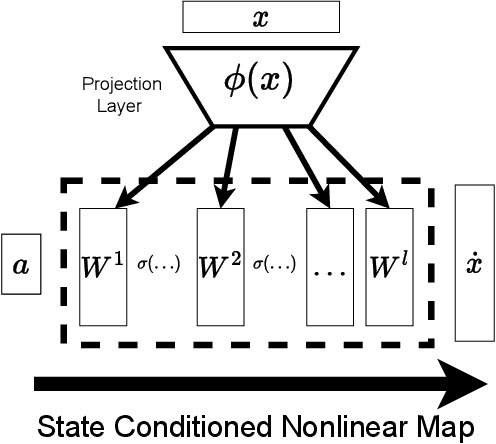

As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
Learning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Deep Probabilistic Movement Primitives with a Bayesian Aggregator
Jul 11, 2023



Movement primitives are trainable parametric models that reproduce robotic movements starting from a limited set of demonstrations. Previous works proposed simple linear models that exhibited high sample efficiency and generalization power by allowing temporal modulation of movements (reproducing movements faster or slower), blending (merging two movements into one), via-point conditioning (constraining a movement to meet some particular via-points) and context conditioning (generation of movements based on an observed variable, e.g., position of an object). Previous works have proposed neural network-based motor primitive models, having demonstrated their capacity to perform tasks with some forms of input conditioning or time-modulation representations. However, there has not been a single unified deep motor primitive's model proposed that is capable of all previous operations, limiting neural motor primitive's potential applications. This paper proposes a deep movement primitive architecture that encodes all the operations above and uses a Bayesian context aggregator that allows a more sound context conditioning and blending. Our results demonstrate our approach can scale to reproduce complex motions on a larger variety of input choices compared to baselines while maintaining operations of linear movement primitives provide.
Analyzing Neural Jacobian Methods in Applications of Visual Servoing and Kinematic Control
Jun 10, 2021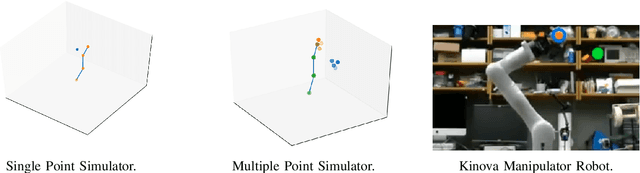
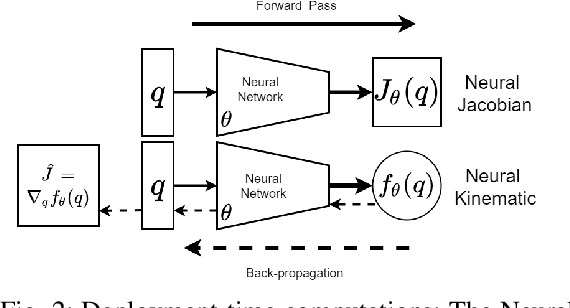
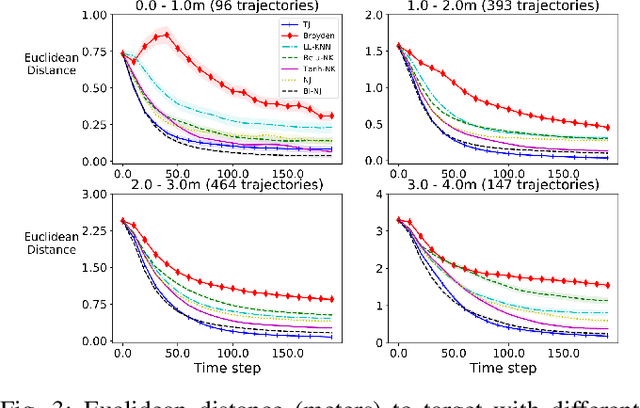
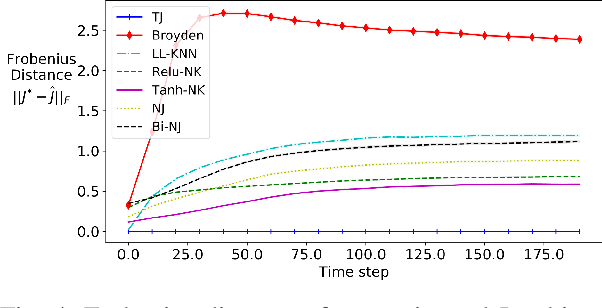
Designing adaptable control laws that can transfer between different robots is a challenge because of kinematic and dynamic differences, as well as in scenarios where external sensors are used. In this work, we empirically investigate a neural networks ability to approximate the Jacobian matrix for an application in Cartesian control schemes. Specifically, we are interested in approximating the kinematic Jacobian, which arises from kinematic equations mapping a manipulator's joint angles to the end-effector's location. We propose two different approaches to learn the kinematic Jacobian. The first method arises from visual servoing where we learn the kinematic Jacobian as an approximate linear system of equations from the k-nearest neighbors for a desired joint configuration. The second, motivated by forward models in machine learning, learns the kinematic behavior directly and calculates the Jacobian by differentiating the learned neural kinematics model. Simulation experimental results show that both methods achieve better performance than alternative data-driven methods for control, provide closer approximations to the proper kinematics Jacobian matrix, and on average produce better-conditioned Jacobian matrices. Real-world experiments were conducted on a Kinova Gen-3 lightweight robotic manipulator, which includes an uncalibrated visual servoing experiment, a practical application of our methods, as well as a 7-DOF point-to-point task highlighting that our methods are applicable on real robotic manipulators.
Sentence-Level BERT and Multi-Task Learning of Age and Gender in Social Media
Nov 02, 2019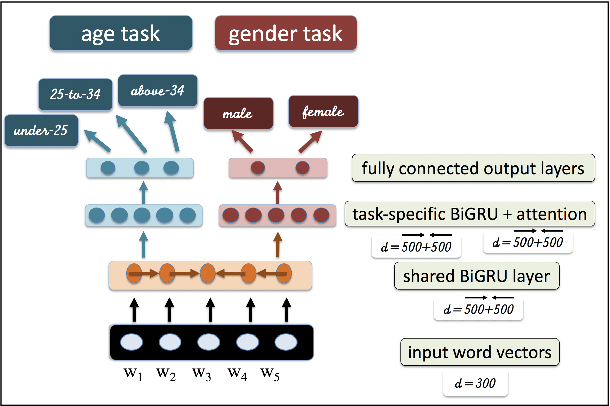
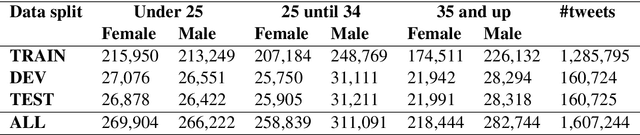
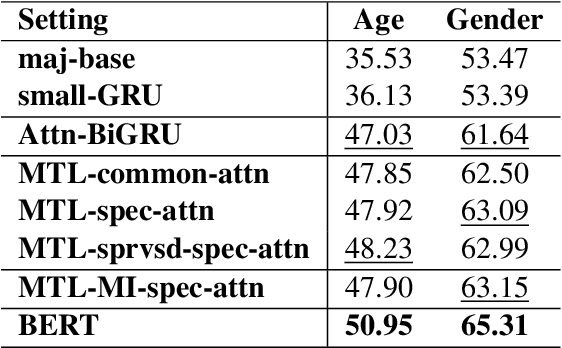
Social media currently provide a window on our lives, making it possible to learn how people from different places, with different backgrounds, ages, and genders use language. In this work we exploit a newly-created Arabic dataset with ground truth age and gender labels to learn these attributes both individually and in a multi-task setting at the sentence level. Our models are based on variations of deep bidirectional neural networks. More specifically, we build models with gated recurrent units and bidirectional encoder representations from transformers (BERT). We show the utility of multi-task learning (MTL) on the two tasks and identify task-specific attention as a superior choice in this context. We also find that a single-task BERT model outperform our best MTL models on the two tasks. We report tweet-level accuracy of 51.43% for the age task (three-way) and 65.30% on the gender task (binary), both of which outperforms our baselines with a large margin. Our models are language-agnostic, and so can be applied to other languages.
Iroko: A Framework to Prototype Reinforcement Learning for Data Center Traffic Control
Dec 24, 2018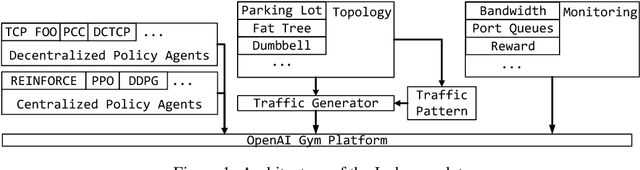
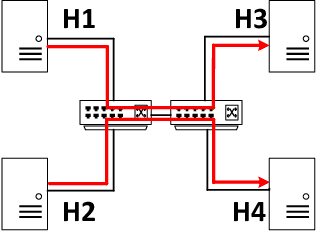
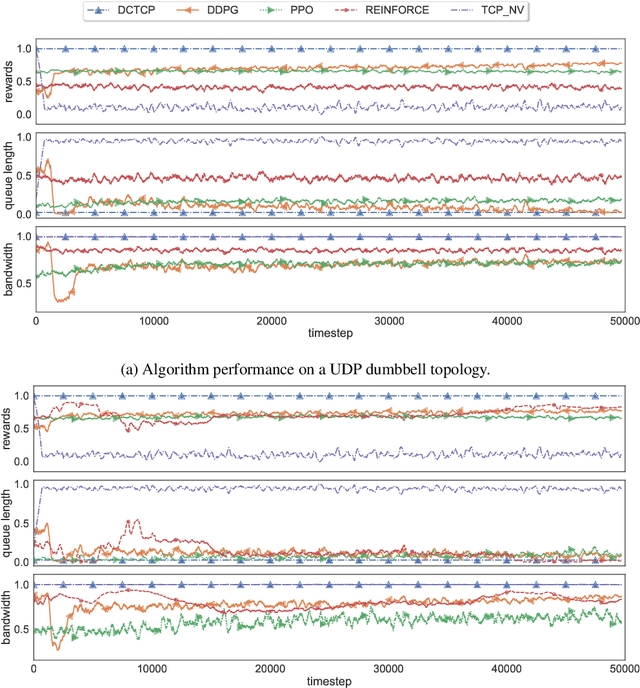
Recent networking research has identified that data-driven congestion control (CC) can be more efficient than traditional CC in TCP. Deep reinforcement learning (RL), in particular, has the potential to learn optimal network policies. However, RL suffers from instability and over-fitting, deficiencies which so far render it unacceptable for use in datacenter networks. In this paper, we analyze the requirements for RL to succeed in the datacenter context. We present a new emulator, Iroko, which we developed to support different network topologies, congestion control algorithms, and deployment scenarios. Iroko interfaces with the OpenAI gym toolkit, which allows for fast and fair evaluation of different RL and traditional CC algorithms under the same conditions. We present initial benchmarks on three deep RL algorithms compared to TCP New Vegas and DCTCP. Our results show that these algorithms are able to learn a CC policy which exceeds the performance of TCP New Vegas on a dumbbell and fat-tree topology. We make our emulator open-source and publicly available: https://github.com/dcgym/iroko