 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-Level BERT and Multi-Task Learning of Age and Gender in Social Media
Nov 02, 2019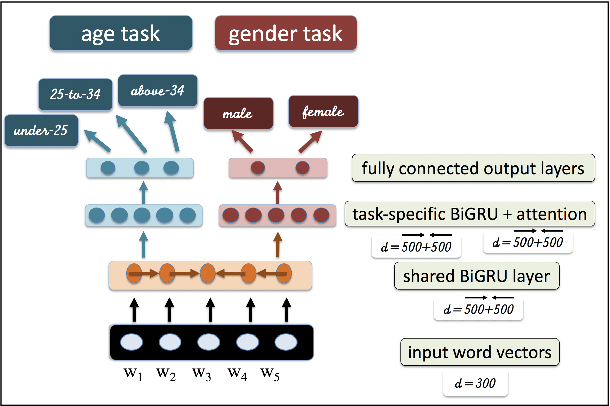
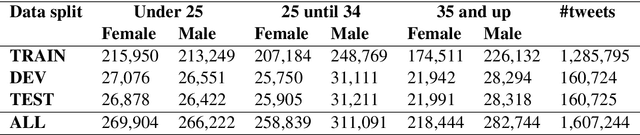
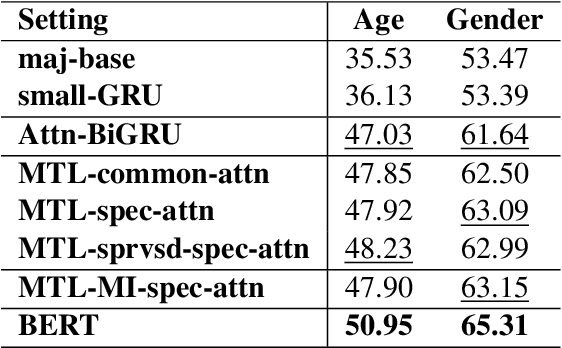
Social media currently provide a window on our lives, making it possible to learn how people from different places, with different backgrounds, ages, and genders use language. In this work we exploit a newly-created Arabic dataset with ground truth age and gender labels to learn these attributes both individually and in a multi-task setting at the sentence level. Our models are based on variations of deep bidirectional neural networks. More specifically, we build models with gated recurrent units and bidirectional encoder representations from transformers (BERT). We show the utility of multi-task learning (MTL) on the two tasks and identify task-specific attention as a superior choice in this context. We also find that a single-task BERT model outperform our best MTL models on the two tasks. We report tweet-level accuracy of 51.43% for the age task (three-way) and 65.30% on the gender task (binary), both of which outperforms our baselines with a large margin. Our models are language-agnostic, and so can be applied to other languages.
DiaNet: BERT and Hierarchical Attention Multi-Task Learning of Fine-Grained Dialect
Oct 31, 2019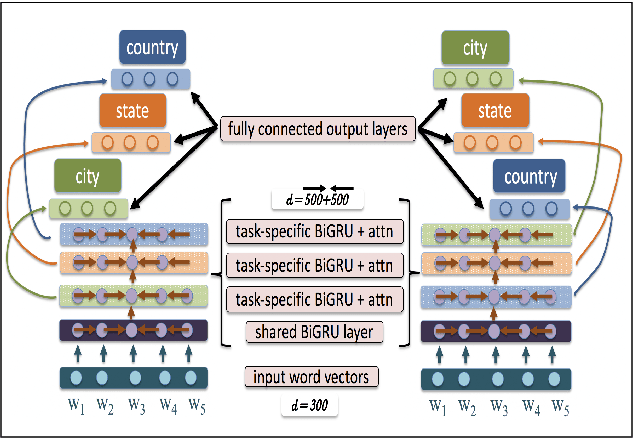

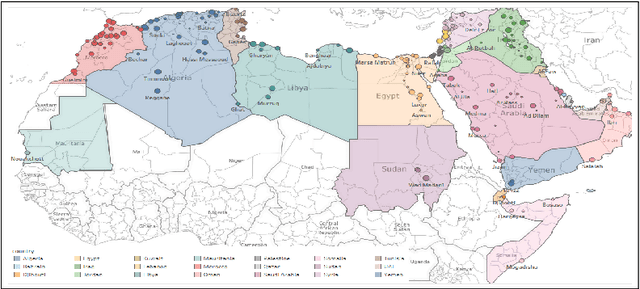

Prediction of language varieties and dialects is an important language processing task, with a wide range of applications. For Arabic, the native tongue of ~ 300 million people, most varieties remain unsupported. To ease this bottleneck, we present a very large scale dataset covering 319 cities from all 21 Arab countries. We introduce a hierarchical attention multi-task learning (HA-MTL) approach for dialect identification exploiting our data at the city, state, and country levels. We also evaluate use of BERT on the three tasks, comparing it to the MTL approach. We benchmark and release our data and models.
UBC-NLP at SemEval-2019 Task 6:Ensemble Learning of Offensive Content With Enhanced Training Data
Jun 09, 2019



We examine learning offensive content on Twitter with limited, imbalanced data. For the purpose, we investigate the utility of using various data enhancement methods with a host of classical ensemble classifiers. Among the 75 participating teams in SemEval-2019 sub-task B, our system ranks 6th (with 0.706 macro F1-score). For sub-task C, among the 65 participating teams, our system ranks 9th (with 0.587 macro F1-score).
Happy Together: Learning and Understanding Appraisal From Natural Language
Jun 09, 2019



In this paper, we explore various approaches for learning two types of appraisal components from happy language. We focus on 'agency' of the author and the 'sociality' involved in happy moments based on the HappyDB dataset. We develop models based on deep neural networks for the task, including uni- and bi-directional long short-term memory networks, with and without attention. We also experiment with a number of novel embedding methods, such as embedding from neural machine translation (as in CoVe) and embedding from language models (as in ELMo). We compare our results to those acquired by several traditional machine learning methods. Our best models achieve 87.97% accuracy on agency and 93.13% accuracy on sociality, both of which are significantly higher than our baselines.