Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiaNet: BERT and Hierarchical Attention Multi-Task Learning of Fine-Grained Dialect
Paper and Code
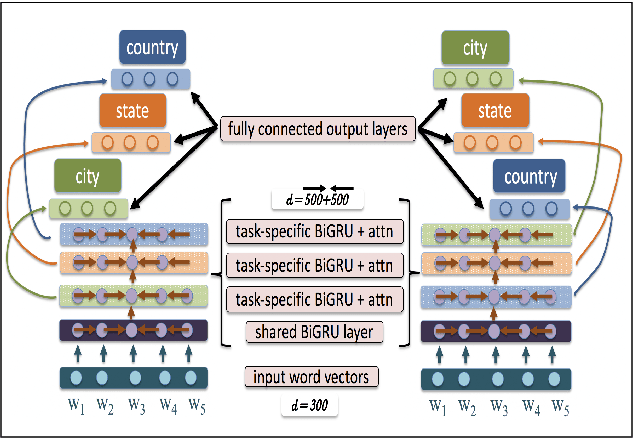

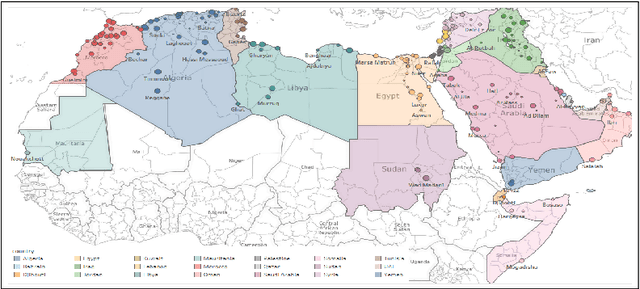

Prediction of language varieties and dialects is an important language processing task, with a wide range of applications. For Arabic, the native tongue of ~ 300 million people, most varieties remain unsupported. To ease this bottleneck, we present a very large scale dataset covering 319 cities from all 21 Arab countries. We introduce a hierarchical attention multi-task learning (HA-MTL) approach for dialect identification exploiting our data at the city, state, and country levels. We also evaluate use of BERT on the three tasks, comparing it to the MTL approach. We benchmark and release our data and models.
View paper on