 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedFetch: Faster Federated Learning with Adaptive Downstream Prefetching
Apr 21, 2025Federated learning (FL) is a machine learning paradigm that facilitates massively distributed model training with end-user data on edge devices directed by a central server. However, the large number of heterogeneous clients in FL deployments leads to a communication bottleneck between the server and the clients. This bottleneck is made worse by straggling clients, any one of which will further slow down training. To tackle these challenges, researchers have proposed techniques like client sampling and update compression. These techniques work well in isolation but combine poorly in the downstream, server-to-client direction. This is because unselected clients have outdated local model states and need to synchronize these states with the server first. We introduce FedFetch, a strategy to mitigate the download time overhead caused by combining client sampling and compression techniques. FedFetch achieves this with an efficient prefetch schedule for clients to prefetch model states multiple rounds before a stated training round. We empirically show that adding FedFetch to communication efficient FL techniques reduces end-to-end training time by 1.26$\times$ and download time by 4.49$\times$ across compression techniques with heterogeneous client settings. Our implementation is available at https://github.com/DistributedML/FedFetch
Scalable Data Point Valuation in Decentralized Learning
May 01, 2023Existing research on data valuation in federated and swarm learning focuses on valuing client contributions and works best when data across clients is independent and identically distributed (IID). In practice, data is rarely distributed IID. We develop an approach called DDVal for decentralized data valuation, capable of valuing individual data points in federated and swarm learning. DDVal is based on sharing deep features and approximating Shapley values through a k-nearest neighbor approximation method. This allows for novel applications, for example, to simultaneously reward institutions and individuals for providing data to a decentralized machine learning task. The valuation of data points through DDVal allows to also draw hierarchical conclusions on the contribution of institutions, and we empirically show that the accuracy of DDVal in estimating institutional contributions is higher than existing Shapley value approximation methods for federated learning. Specifically, it reaches a cosine similarity in approximating Shapley values of 99.969 % in both, IID and non-IID data distributions across institutions, compared with 99.301 % and 97.250 % for the best state of the art methods. DDVal scales with the number of data points instead of the number of clients, and has a loglinear complexity. This scales more favorably than existing approaches with an exponential complexity. We show that DDVal is especially efficient in data distribution scenarios with many clients that have few data points - for example, more than 16 clients with 8,000 data points each. By integrating DDVal into a decentralized system, we show that it is not only suitable for centralized federated learning, but also decentralized swarm learning, which aligns well with the research on emerging internet technologies such as web3 to reward users for providing data to algorithms.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022
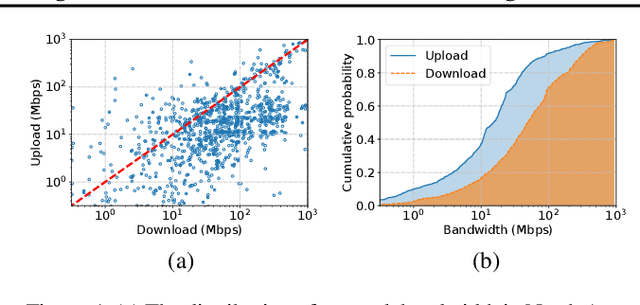
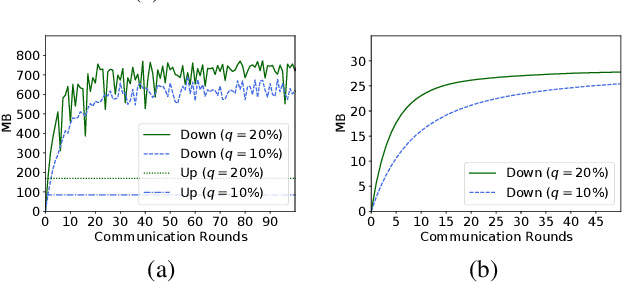
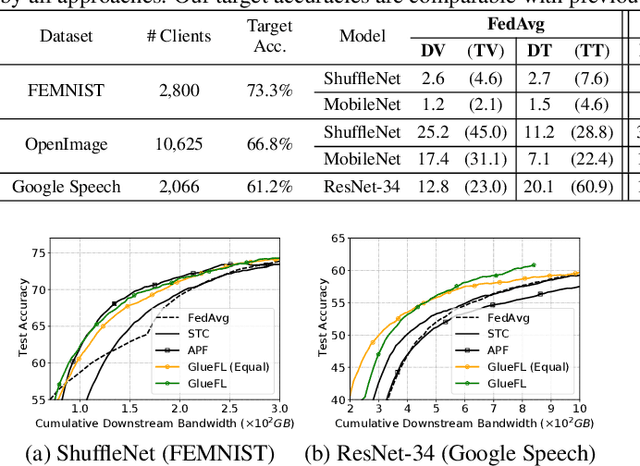
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Generalizing Neural Networks by Reflecting Deviating Data in Production
Oct 06, 2021
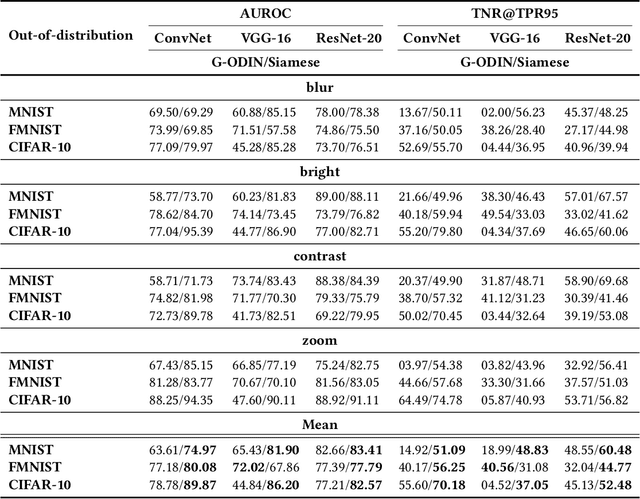
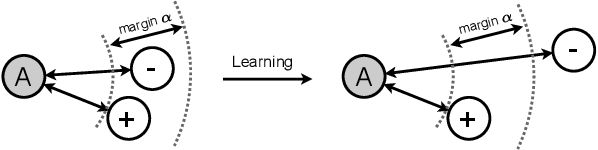
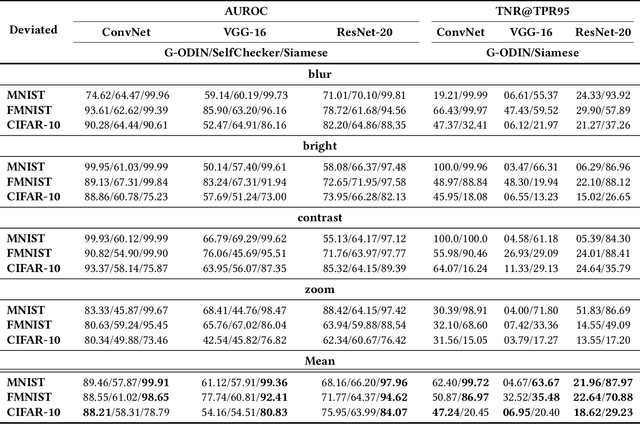
Trained with a sufficiently large training and testing dataset, Deep Neural Networks (DNNs) are expected to generalize. However, inputs may deviate from the training dataset distribution in real deployments. This is a fundamental issue with using a finite dataset. Even worse, real inputs may change over time from the expected distribution. Taken together, these issues may lead deployed DNNs to mis-predict in production. In this work, we present a runtime approach that mitigates DNN mis-predictions caused by the unexpected runtime inputs to the DNN. In contrast to previous work that considers the structure and parameters of the DNN itself, our approach treats the DNN as a blackbox and focuses on the inputs to the DNN. Our approach has two steps. First, it recognizes and distinguishes "unseen" semantically-preserving inputs. For this we use a distribution analyzer based on the distance metric learned by a Siamese network. Second, our approach transforms those unexpected inputs into inputs from the training set that are identified as having similar semantics. We call this process input reflection and formulate it as a search problem over the embedding space on the training set. This embedding space is learned by a Quadruplet network as an auxiliary model for the subject model to improve the generalization. We implemented a tool called InputReflector based on the above two-step approach and evaluated it with experiments on three DNN models trained on CIFAR-10, MNIST, and FMINST image datasets. The results show that InputReflector can effectively distinguish inputs that retain semantics of the distribution (e.g., blurred, brightened, contrasted, and zoomed images) and out-of-distribution inputs from normal inputs.
Fairness-guided SMT-based Rectification of Decision Trees and Random Forests
Nov 22, 2020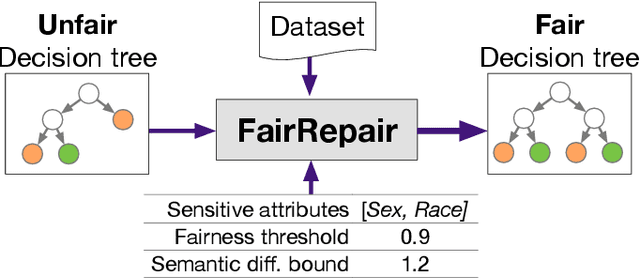
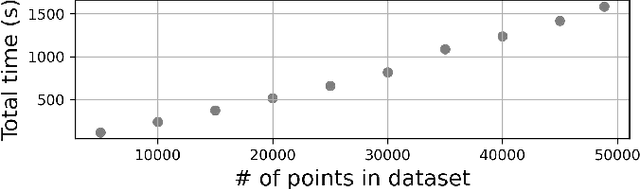
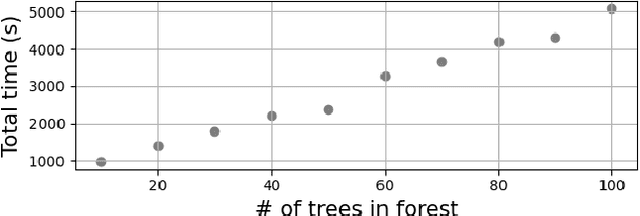
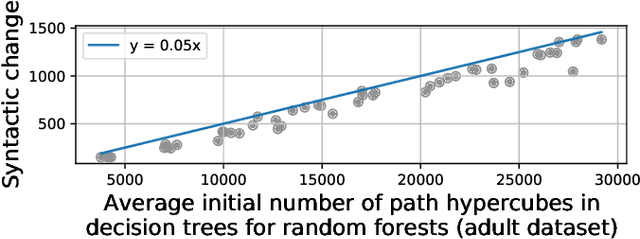
Data-driven decision making is gaining prominence with the popularity of various machine learning models. Unfortunately, real-life data used in machine learning training may capture human biases, and as a result the learned models may lead to unfair decision making. In this paper, we provide a solution to this problem for decision trees and random forests. Our approach converts any decision tree or random forest into a fair one with respect to a specific data set, fairness criteria, and sensitive attributes. The \emph{FairRepair} tool, built based on our approach, is inspired by automated program repair techniques for traditional programs. It uses an SMT solver to decide which paths in the decision tree could have their outcomes flipped to improve the fairness of the model. Our experiments on the well-known adult dataset from UC Irvine demonstrate that FairRepair scales to realistic decision trees and random forests. Furthermore, FairRepair provides formal guarantees about soundness and completeness of finding a repair. Since our fairness-guided repair technique repairs decision trees and random forests obtained from a given (unfair) data-set, it can help to identify and rectify biases in decision-making in an organisation.
Iroko: A Framework to Prototype Reinforcement Learning for Data Center Traffic Control
Dec 24, 2018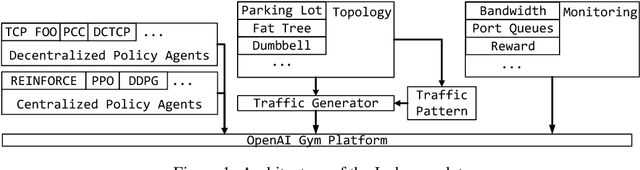
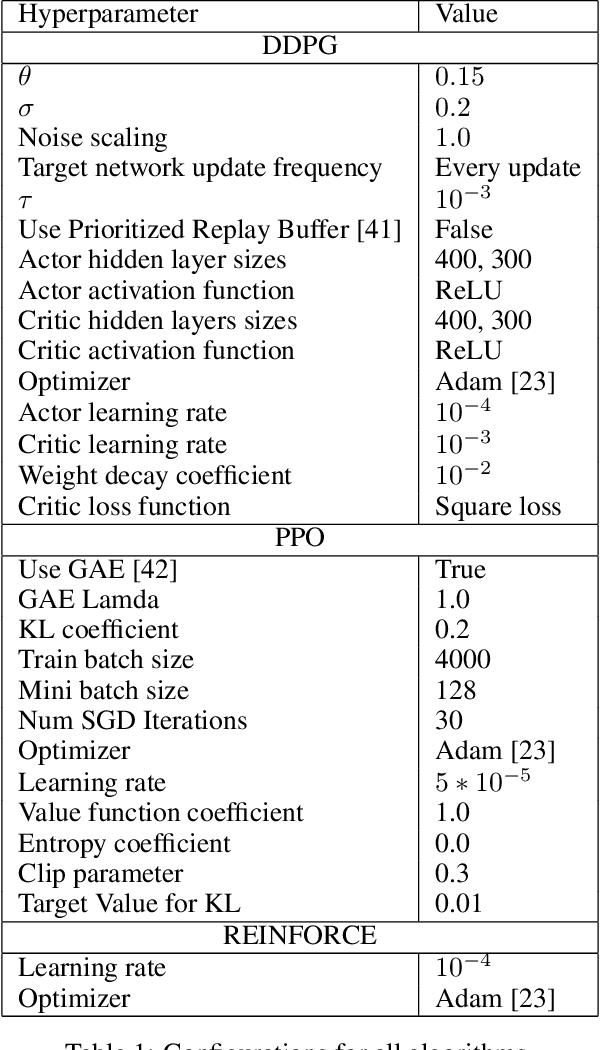
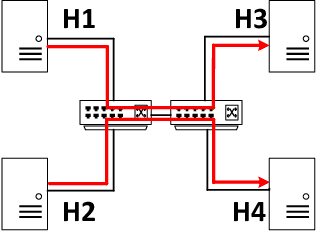
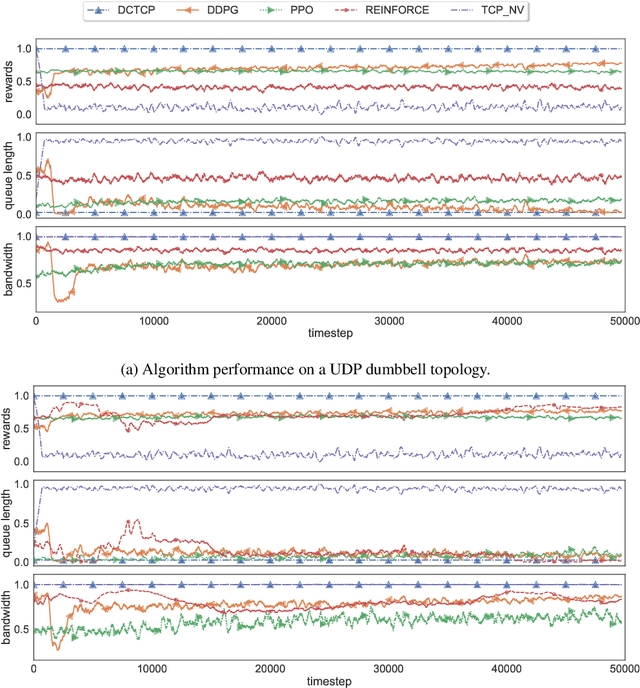
Recent networking research has identified that data-driven congestion control (CC) can be more efficient than traditional CC in TCP. Deep reinforcement learning (RL), in particular, has the potential to learn optimal network policies. However, RL suffers from instability and over-fitting, deficiencies which so far render it unacceptable for use in datacenter networks. In this paper, we analyze the requirements for RL to succeed in the datacenter context. We present a new emulator, Iroko, which we developed to support different network topologies, congestion control algorithms, and deployment scenarios. Iroko interfaces with the OpenAI gym toolkit, which allows for fast and fair evaluation of different RL and traditional CC algorithms under the same conditions. We present initial benchmarks on three deep RL algorithms compared to TCP New Vegas and DCTCP. Our results show that these algorithms are able to learn a CC policy which exceeds the performance of TCP New Vegas on a dumbbell and fat-tree topology. We make our emulator open-source and publicly available: https://github.com/dcgym/iroko
Biscotti: A Ledger for Private and Secure Peer-to-Peer Machine Learning
Nov 27, 2018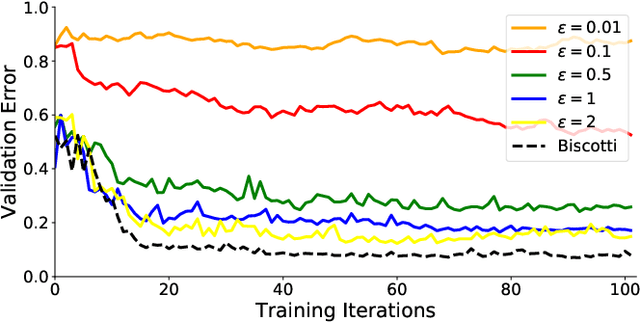

Centralized solutions for privacy-preserving multi-party ML are becoming increasingly infeasible: a variety of attacks have demonstrated their weaknesses. Federated Learning is the current state of the art in supporting secure multi-party ML:data is maintained on the owner's device and is aggregated through a secure protocol. However, this process assumes a trusted centralized infrastructure for coordination and clients must trust that the central service does not maliciously use the byproducts of client data. As a response, we propose Biscotti: a fully decentralized P2P approach to multi-party ML, which leverages blockchain primitives to coordinate a privacy-preserving ML process between peering clients. Our evaluation demonstrates that Biscotti is scalable, fault tolerant, and defends against known attacks. Biscotti is able to protect the performance of the global model at scale even when 48 percent of the adversaries are malicious, and at the same time provides privacy while preventing poisoning attacks.
Dancing in the Dark: Private Multi-Party Machine Learning in an Untrusted Setting
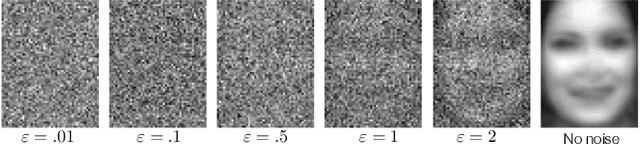
Nov 23, 2018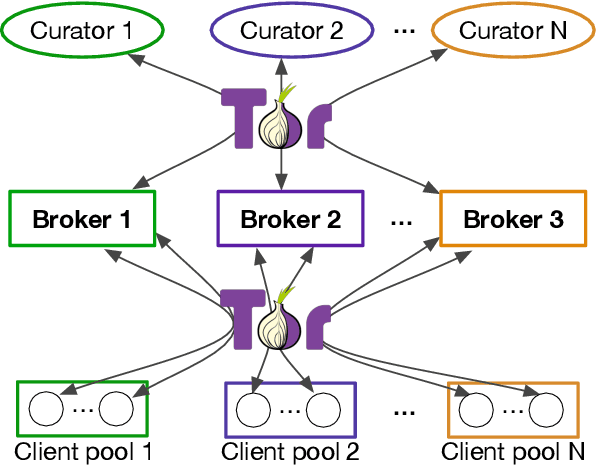

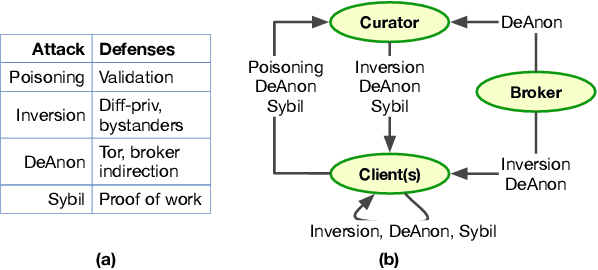
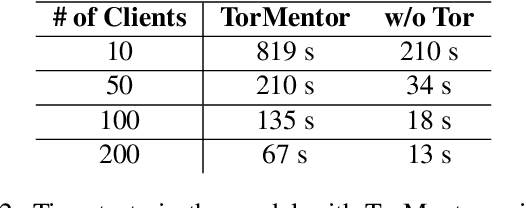
Distributed machine learning (ML) systems today use an unsophisticated threat model: data sources must trust a central ML process. We propose a brokered learning abstraction that allows data sources to contribute towards a globally-shared model with provable privacy guarantees in an untrusted setting. We realize this abstraction by building on federated learning, the state of the art in multi-party ML, to construct TorMentor: an anonymous hidden service that supports private multi-party ML. We define a new threat model by characterizing, developing and evaluating new attacks in the brokered learning setting, along with new defenses for these attacks. We show that TorMentor effectively protects data providers against known ML attacks while providing them with a tunable trade-off between model accuracy and privacy. We evaluate TorMentor with local and geo-distributed deployments on Azure/Tor. In an experiment with 200 clients and 14 MB of data per client, our prototype trained a logistic regression model using stochastic gradient descent in 65s.
Mitigating Sybils in Federated Learning Poisoning
Aug 14, 2018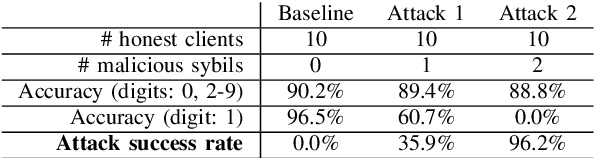
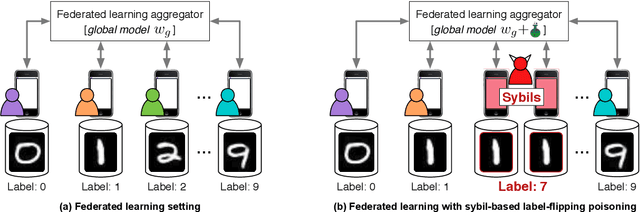
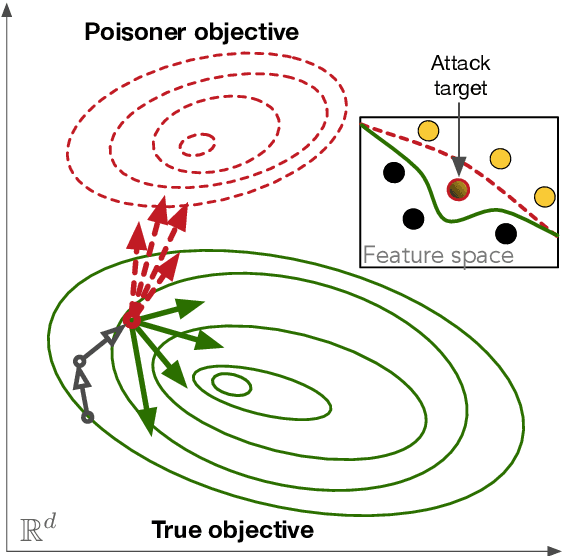
Machine learning (ML) over distributed data is relevant to a variety of domains. Existing approaches, such as federated learning, compose the outputs computed by a group of devices at a central aggregator and run multi-round algorithms to generate a globally shared model. Unfortunately, such approaches are susceptible to a variety of attacks, including model poisoning, which is made substantially worse in the presence of sybils. In this paper we first evaluate the vulnerability of federated learning to sybil-based poisoning attacks. We then describe FoolsGold, a novel defense to this problem that identifies poisoning sybils based on the diversity of client contributions in the distributed learning process. Unlike prior work, our system does not assume that the attackers are in the minority, requires no auxiliary information outside of the learning process, and makes fewer assumptions about clients and their data. In our evaluation we show that FoolsGold exceeds the capabilities of existing state of the art approaches to countering ML poisoning attacks. Our results hold for a variety of conditions, including different distributions of data, varying poisoning targets, and various attack strategies.