 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Recommendation Meets Large Language Models
Nov 29, 2024



Cross-domain recommendation (CDR) has emerged as a promising solution to the cold-start problem, faced by single-domain recommender systems. However, existing CDR models rely on complex neural architectures, large datasets, and significant computational resources, making them less effective in data-scarce scenarios or when simplicity is crucial. In this work, we leverage the reasoning capabilities of large language models (LLMs) and explore their performance in the CDR domain across multiple domain pairs. We introduce two novel prompt designs tailored for CDR and demonstrate that LLMs, when prompted effectively, outperform state-of-the-art CDR baselines across various metrics and domain combinations in the rating prediction and ranking tasks. This work bridges the gap between LLMs and recommendation systems, showcasing their potential as effective cross-domain recommenders.
Generalizing Neural Networks by Reflecting Deviating Data in Production
Oct 06, 2021
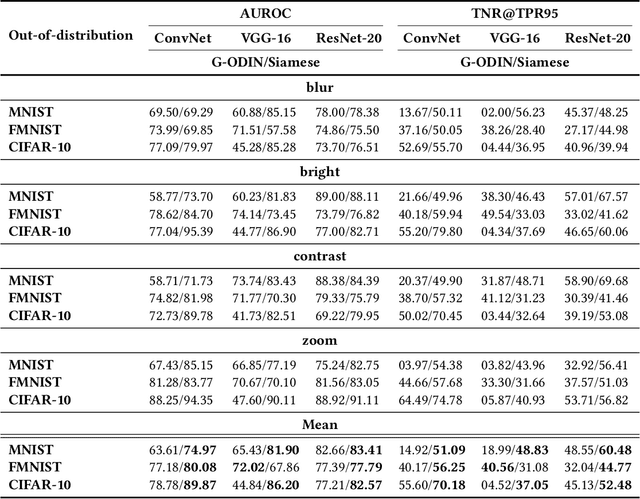
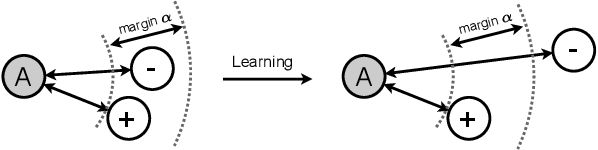
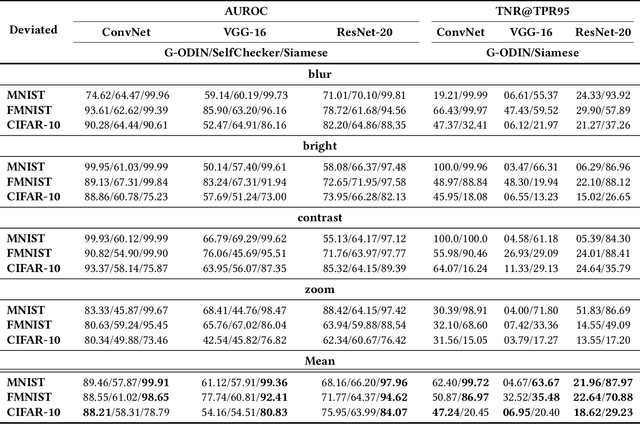
Trained with a sufficiently large training and testing dataset, Deep Neural Networks (DNNs) are expected to generalize. However, inputs may deviate from the training dataset distribution in real deployments. This is a fundamental issue with using a finite dataset. Even worse, real inputs may change over time from the expected distribution. Taken together, these issues may lead deployed DNNs to mis-predict in production. In this work, we present a runtime approach that mitigates DNN mis-predictions caused by the unexpected runtime inputs to the DNN. In contrast to previous work that considers the structure and parameters of the DNN itself, our approach treats the DNN as a blackbox and focuses on the inputs to the DNN. Our approach has two steps. First, it recognizes and distinguishes "unseen" semantically-preserving inputs. For this we use a distribution analyzer based on the distance metric learned by a Siamese network. Second, our approach transforms those unexpected inputs into inputs from the training set that are identified as having similar semantics. We call this process input reflection and formulate it as a search problem over the embedding space on the training set. This embedding space is learned by a Quadruplet network as an auxiliary model for the subject model to improve the generalization. We implemented a tool called InputReflector based on the above two-step approach and evaluated it with experiments on three DNN models trained on CIFAR-10, MNIST, and FMINST image datasets. The results show that InputReflector can effectively distinguish inputs that retain semantics of the distribution (e.g., blurred, brightened, contrasted, and zoomed images) and out-of-distribution inputs from normal inputs.
Directed Graph Convolutional Network
Apr 29, 2020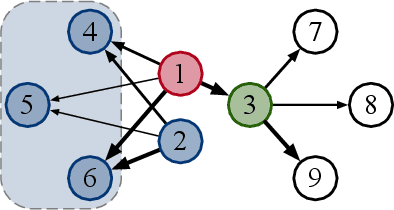
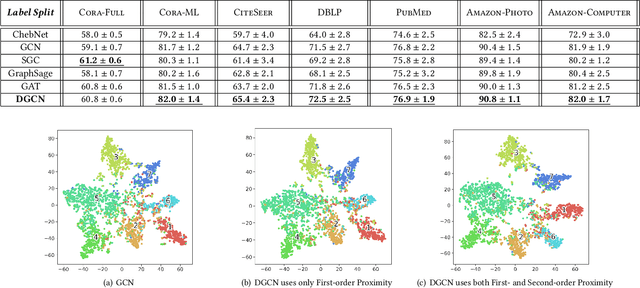
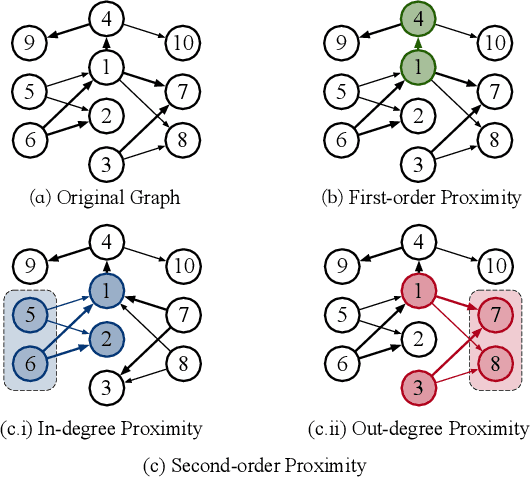
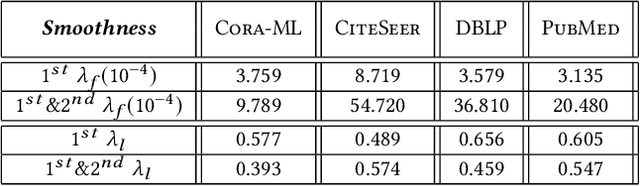
Graph Convolutional Networks (GCNs) have been widely used due to their outstanding performance in processing graph-structured data. However, the undirected graphs limit their application scope. In this paper, we extend spectral-based graph convolution to directed graphs by using first- and second-order proximity, which can not only retain the connection properties of the directed graph, but also expand the receptive field of the convolution operation. A new GCN model, called DGCN, is then designed to learn representations on the directed graph, leveraging both the first- and second-order proximity information. We empirically show the fact that GCNs working only with DGCNs can encode more useful information from graph and help achieve better performance when generalized to other models. Moreover, extensive experiments on citation networks and co-purchase datasets demonstrate the superiority of our model against the state-of-the-art methods.
Revisiting Convolutional Neural Networks for Urban Flow Analytics
Feb 28, 2020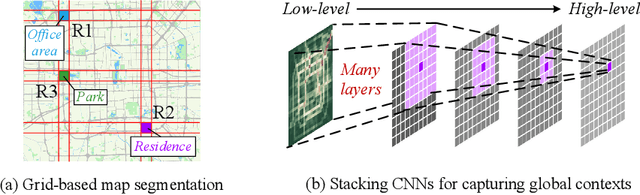
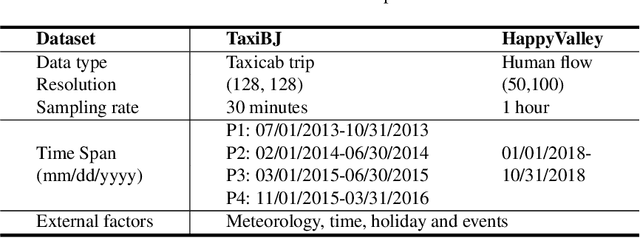
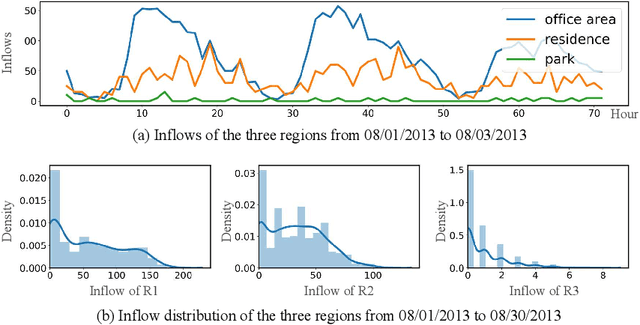
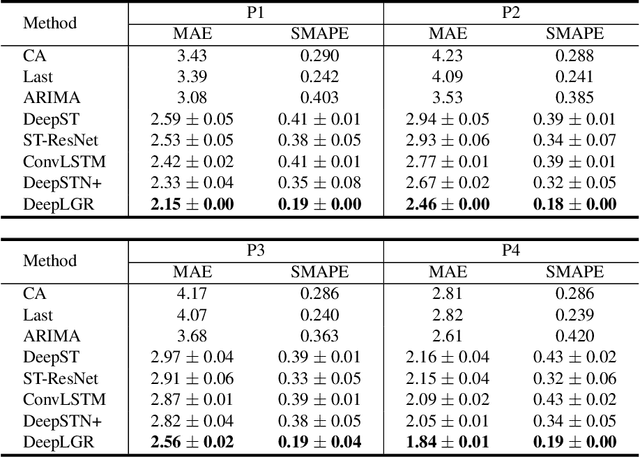
Convolutional Neural Networks (CNNs) have been widely adopted in raster-based urban flow analytics by virtue of their capability in capturing nearby spatial context. By revisiting CNN-based methods for different analytics tasks, we expose two common critical drawbacks in the existing uses: 1) inefficiency in learning global context, and 2) overlooking latent region functions. To tackle these challenges, in this paper we present a novel framework entitled DeepLGR that can be easily generalized to address various urban flow analytics problems. This framework consists of three major parts: 1) a local context module to learn local representations of each region; 2) a global context module to extract global contextual priors and upsample them to generate the global features; and 3) a region-specific predictor based on tensor decomposition to provide customized predictions for each region, which is very parameter-efficient compared to previous methods. Extensive experiments on two typical urban analytics tasks demonstrate the effectiveness, stability, and generality of our framework.
Fine-Grained Urban Flow Inference
Feb 05, 2020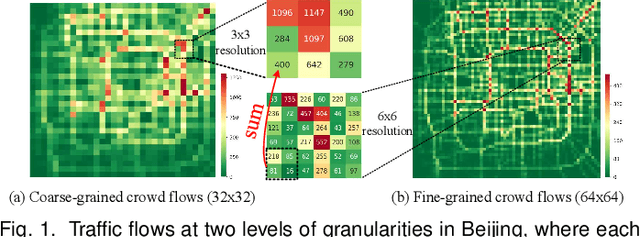
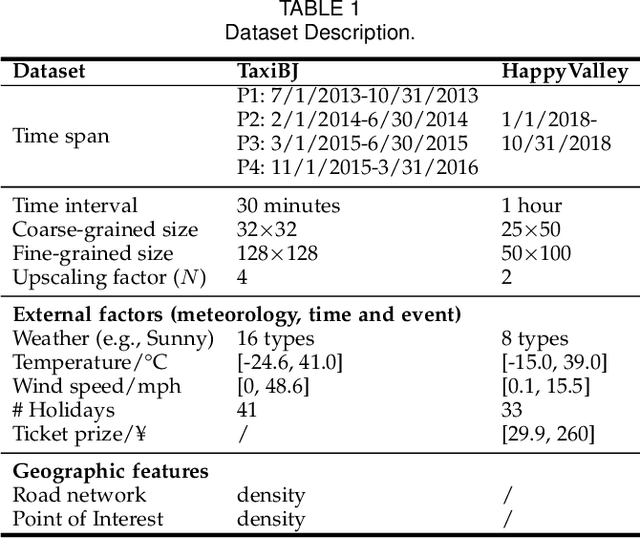
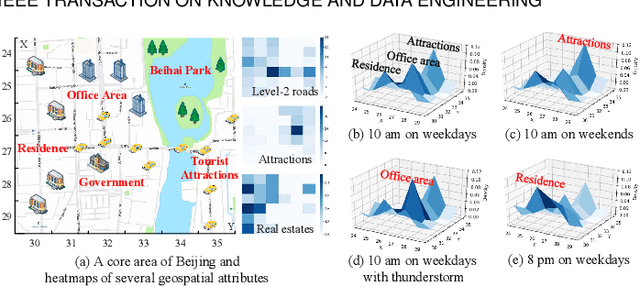
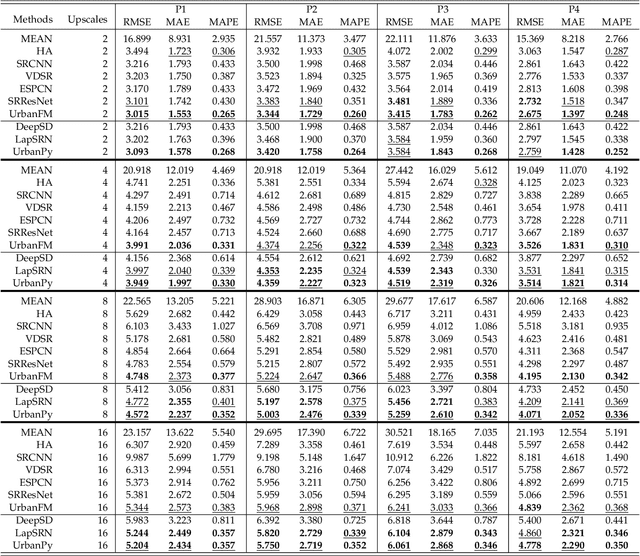
The ubiquitous deployment of monitoring devices in urban flow monitoring systems induces a significant cost for maintenance and operation. A technique is required to reduce the number of deployed devices, while preventing the degeneration of data accuracy and granularity. In this paper, we present an approach for inferring the real-time and fine-grained crowd flows throughout a city based on coarse-grained observations. This task exhibits two challenges: the spatial correlations between coarse- and fine-grained urban flows, and the complexities of external impacts. To tackle these issues, we develop a model entitled UrbanFM which consists of two major parts: 1) an inference network to generate fine-grained flow distributions from coarse-grained inputs that uses a feature extraction module and a novel distributional upsampling module; 2) a general fusion subnet to further boost the performance by considering the influence of different external factors. This structure provides outstanding effectiveness and efficiency for small scale upsampling. However, the single-pass upsampling used by UrbanFM is insufficient at higher upscaling rates. Therefore, we further present UrbanPy, a cascading model for progressive inference of fine-grained urban flows by decomposing the original tasks into multiple subtasks. Compared to UrbanFM, such an enhanced structure demonstrates favorable performance for larger-scale inference tasks.
MMKG: Multi-Modal Knowledge Graphs
Mar 13, 2019


We present MMKG, a collection of three knowledge graphs that contain both numerical features and (links to) images for all entities as well as entity alignments between pairs of KGs. Therefore, multi-relational link prediction and entity matching communities can benefit from this resource. We believe this data set has the potential to facilitate the development of novel multi-modal learning approaches for knowledge graphs.We validate the utility ofMMKG in the sameAs link prediction task with an extensive set of experiments. These experiments show that the task at hand benefits from learning of multiple feature types.
UrbanFM: Inferring Fine-Grained Urban Flows
Feb 06, 2019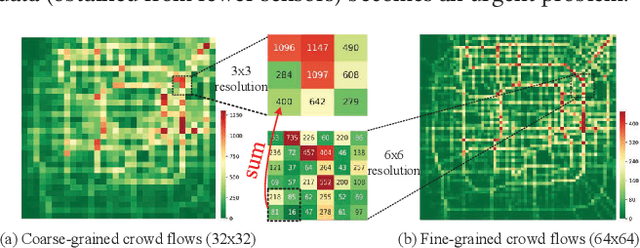
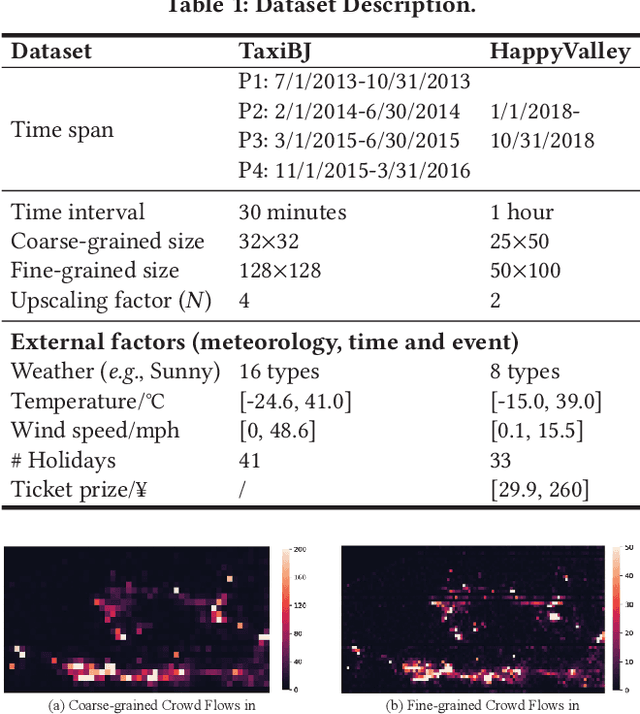
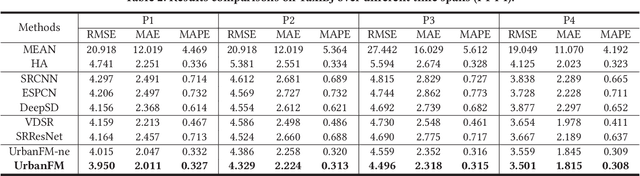
Urban flow monitoring systems play important roles in smart city efforts around the world. However, the ubiquitous deployment of monitoring devices, such as CCTVs, induces a long-lasting and enormous cost for maintenance and operation. This suggests the need for a technology that can reduce the number of deployed devices, while preventing the degeneration of data accuracy and granularity. In this paper, we aim to infer the real-time and fine-grained crowd flows throughout a city based on coarse-grained observations. This task is challenging due to two reasons: the spatial correlations between coarse- and fine-grained urban flows, and the complexities of external impacts. To tackle these issues, we develop a method entitled UrbanFM based on deep neural networks. Our model consists of two major parts: 1) an inference network to generate fine-grained flow distributions from coarse-grained inputs by using a feature extraction module and a novel distributional upsampling module; 2) a general fusion subnet to further boost the performance by considering the influences of different external factors. Extensive experiments on two real-world datasets, namely TaxiBJ and HappyValley, validate the effectiveness and efficiency of our method compared to seven baselines, demonstrating the state-of-the-art performance of our approach on the fine-grained urban flow inference problem.
An Interval-Based Bayesian Generative Model for Human Complex Activity Recognition
Jan 04, 2017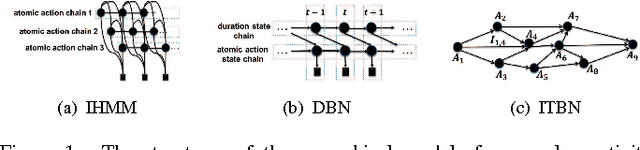
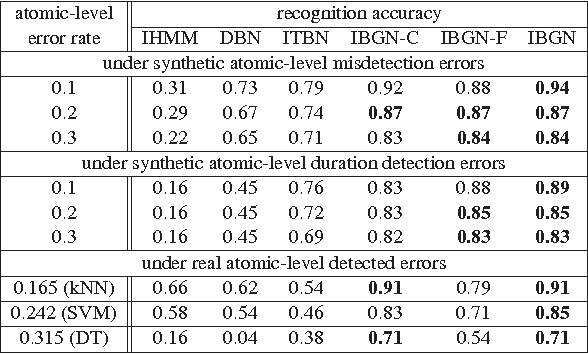
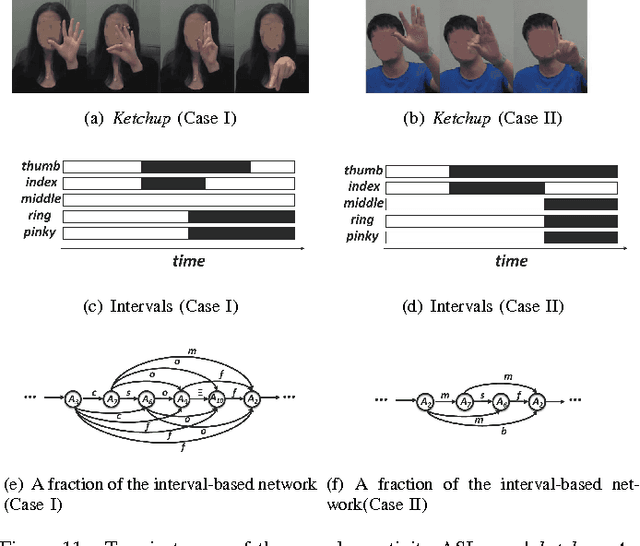
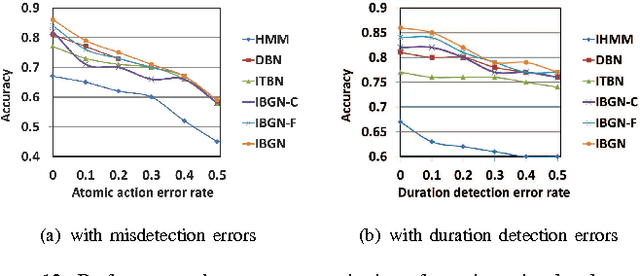
Complex activity recognition is challenging due to the inherent uncertainty and diversity of performing a complex activity. Normally, each instance of a complex activity has its own configuration of atomic actions and their temporal dependencies. We propose in this paper an atomic action-based Bayesian model that constructs Allen's interval relation networks to characterize complex activities with structural varieties in a probabilistic generative way: By introducing latent variables from the Chinese restaurant process, our approach is able to capture all possible styles of a particular complex activity as a unique set of distributions over atomic actions and relations. We also show that local temporal dependencies can be retained and are globally consistent in the resulting interval network. Moreover, network structure can be learned from empirical data. A new dataset of complex hand activities has been constructed and made publicly available, which is much larger in size than any existing datasets. Empirical evaluations on benchmark datasets as well as our in-house dataset demonstrate the competitiveness of our approach.