 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKG: Multi-Modal Knowledge Graphs
Mar 13, 2019


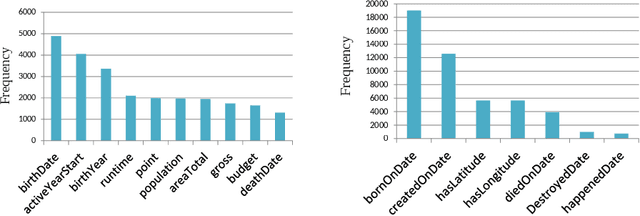
We present MMKG, a collection of three knowledge graphs that contain both numerical features and (links to) images for all entities as well as entity alignments between pairs of KGs. Therefore, multi-relational link prediction and entity matching communities can benefit from this resource. We believe this data set has the potential to facilitate the development of novel multi-modal learning approaches for knowledge graphs.We validate the utility ofMMKG in the sameAs link prediction task with an extensive set of experiments. These experiments show that the task at hand benefits from learning of multiple feature types.
TransRev: Modeling Reviews as Translations from Users to Items
Apr 18, 2018
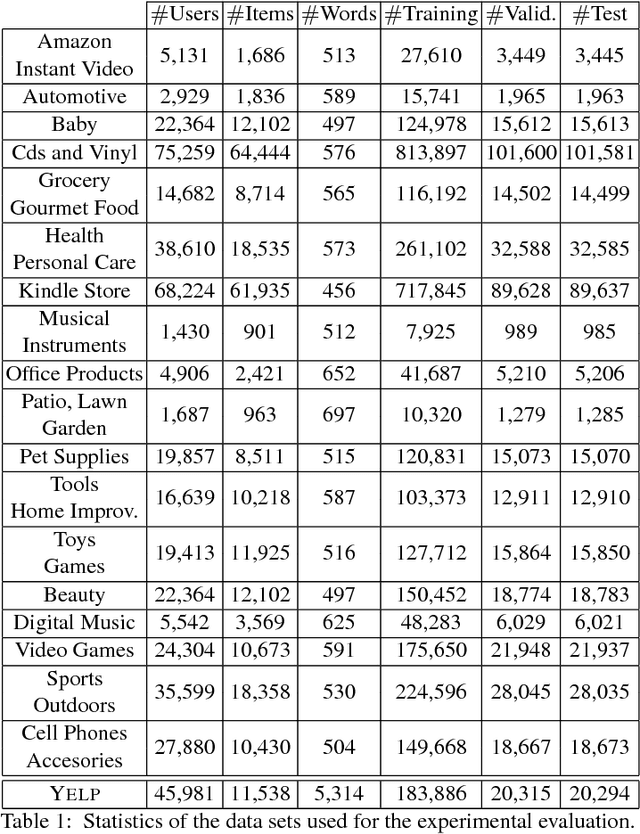
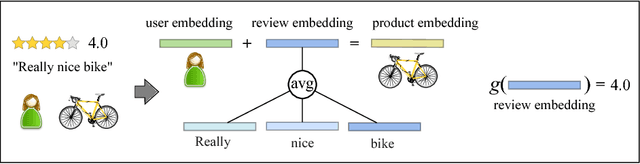
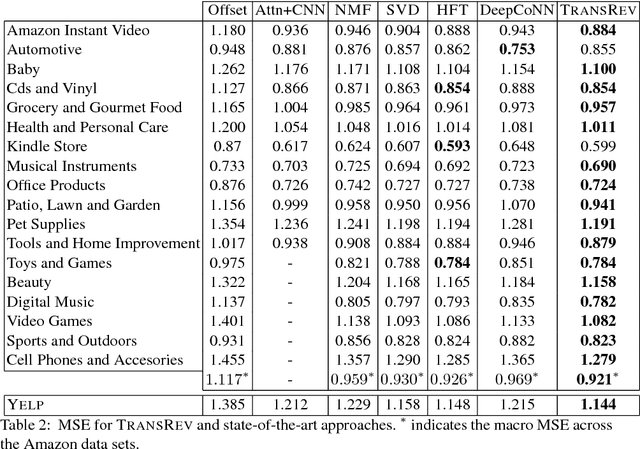
The text of a review expresses the sentiment a customer has towards a particular product. This is exploited in sentiment analysis where machine learning models are used to predict the review score from the text of the review. Furthermore, the products costumers have purchased in the past are indicative of the products they will purchase in the future. This is what recommender systems exploit by learning models from purchase information to predict the items a customer might be interested in. We propose TransRev, an approach to the product recommendation problem that integrates ideas from recommender systems, sentiment analysis, and multi-relational learning into a joint learning objective. TransRev learns vector representations for users, items, and reviews. The embedding of a review is learned such that (a) it performs well as input feature of a regression model for sentiment prediction; and (b) it always translates the reviewer embedding to the embedding of the reviewed items. This allows TransRev to approximate a review embedding at test time as the difference of the embedding of each item and the user embedding. The approximated review embedding is then used with the regression model to predict the review score for each item. TransRev outperforms state of the art recommender systems on a large number of benchmark data sets. Moreover, it is able to retrieve, for each user and item, the review text from the training set whose embedding is most similar to the approximated review embedding.