 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Subspaces for Unsupervised Entity Linking
Apr 18, 2021
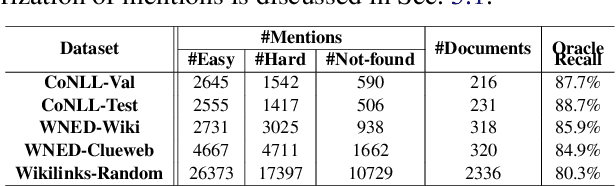
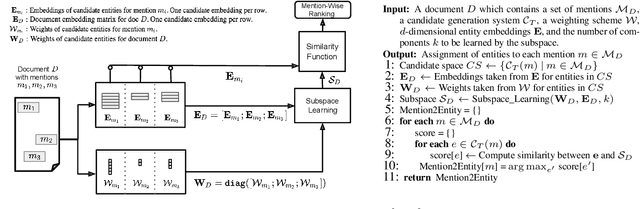
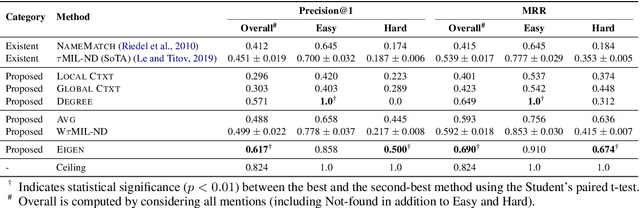
Entity linking is an important problem with many applications. Most previous solutions were designed for settings where annotated training data is available, which is, however, not the case in numerous domains. We propose a light-weight and scalable entity linking method, Eigenthemes, that relies solely on the availability of entity names and a referent knowledge base. Eigenthemes exploits the fact that the entities that are truly mentioned in a document (the "gold entities") tend to form a semantically dense subset of the set of all candidate entities in the document. Geometrically speaking, when representing entities as vectors via some given embedding, the gold entities tend to lie in a low-rank subspace of the full embedding space. Eigenthemes identifies this subspace using the singular value decomposition and scores candidate entities according to their proximity to the subspace. On the empirical front, we introduce multiple strong baselines that compare favorably to the existing state of the art. Extensive experiments on benchmark datasets from a variety of real-world domains showcase the effectiveness of our approach.
Node Attribute Completion in Knowledge Graphs with Multi-Relational Propagation
Nov 10, 2020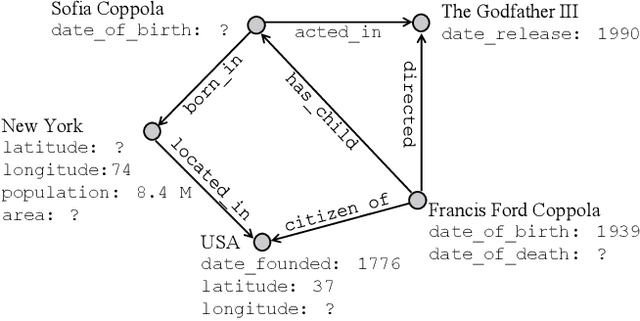
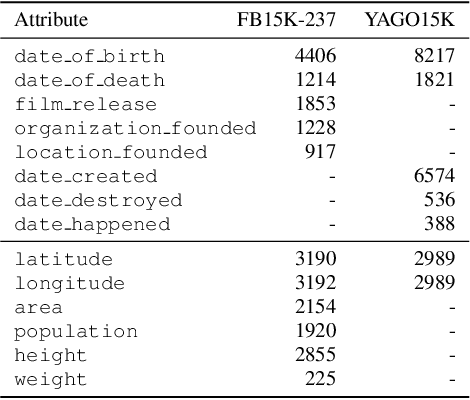
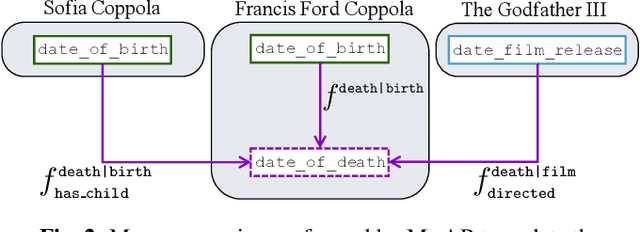
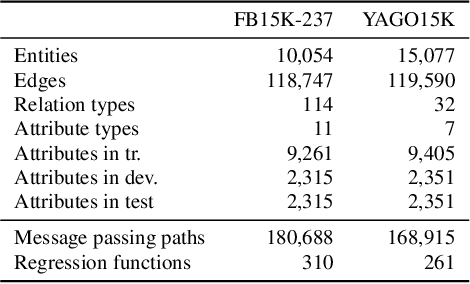
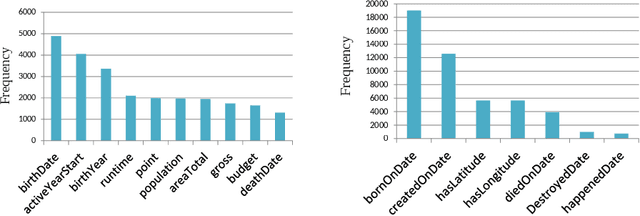
The existing literature on knowledge graph completion mostly focuses on the link prediction task. However, knowledge graphs have an additional incompleteness problem: their nodes possess numerical attributes, whose values are often missing. Our approach, denoted as MrAP, imputes the values of missing attributes by propagating information across the multi-relational structure of a knowledge graph. It employs regression functions for predicting one node attribute from another depending on the relationship between the nodes and the type of the attributes. The propagation mechanism operates iteratively in a message passing scheme that collects the predictions at every iteration and updates the value of the node attributes. Experiments over two benchmark datasets show the effectiveness of our approach.
MMKG: Multi-Modal Knowledge Graphs
Mar 13, 2019


We present MMKG, a collection of three knowledge graphs that contain both numerical features and (links to) images for all entities as well as entity alignments between pairs of KGs. Therefore, multi-relational link prediction and entity matching communities can benefit from this resource. We believe this data set has the potential to facilitate the development of novel multi-modal learning approaches for knowledge graphs.We validate the utility ofMMKG in the sameAs link prediction task with an extensive set of experiments. These experiments show that the task at hand benefits from learning of multiple feature types.
Learning Representations of Missing Data for Predicting Patient Outcomes
Nov 12, 2018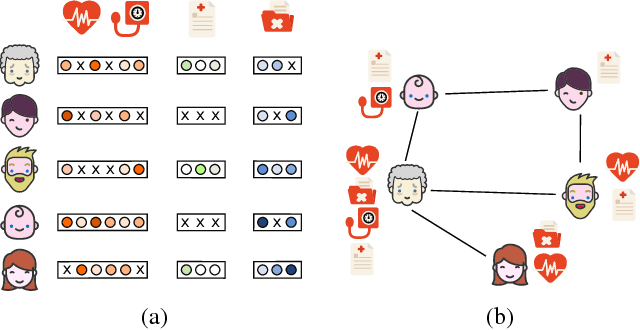
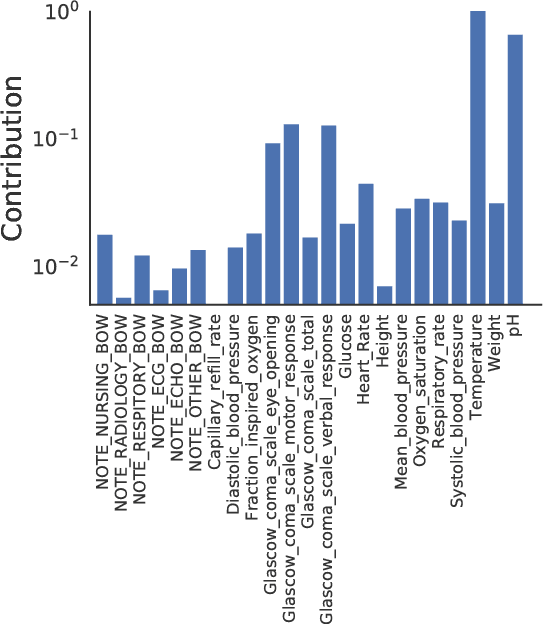
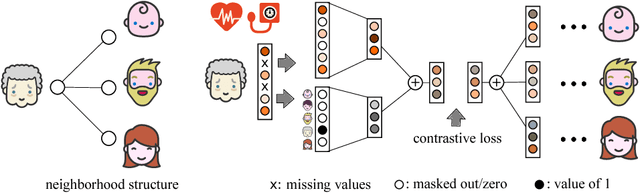
Extracting actionable insight from Electronic Health Records (EHRs) poses several challenges for traditional machine learning approaches. Patients are often missing data relative to each other; the data comes in a variety of modalities, such as multivariate time series, free text, and categorical demographic information; important relationships among patients can be difficult to detect; and many others. In this work, we propose a novel approach to address these first three challenges using a representation learning scheme based on message passing. We show that our proposed approach is competitive with or outperforms the state of the art for predicting in-hospital mortality (binary classification), the length of hospital visits (regression) and the discharge destination (multiclass classification).
On embeddings as an alternative paradigm for relational learning
Jul 02, 2018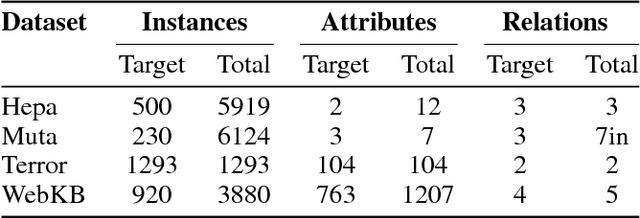
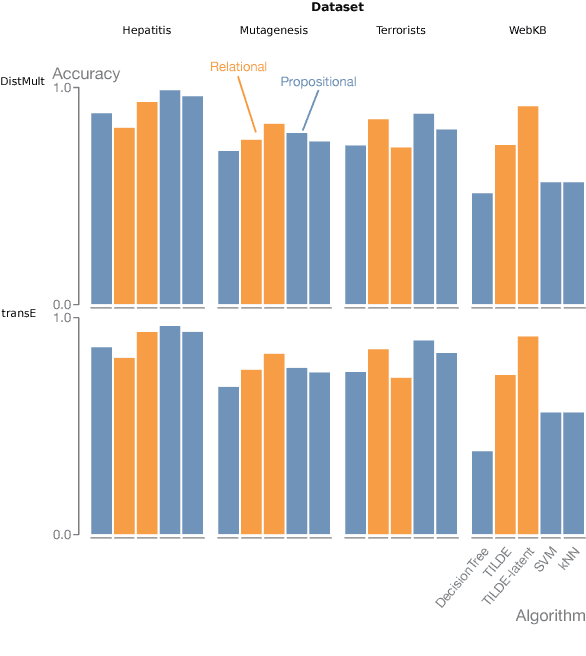
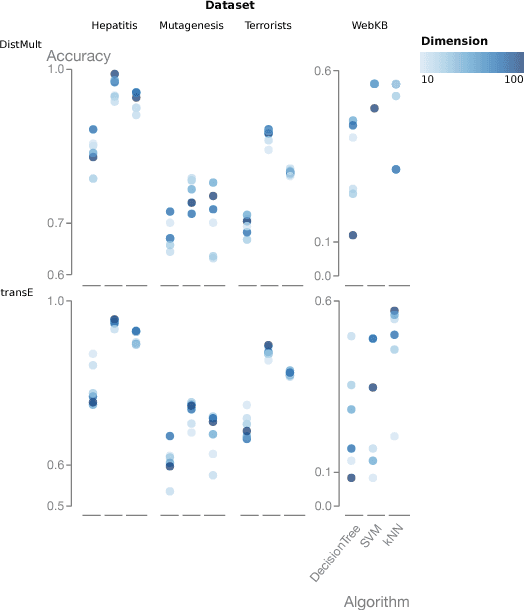

Many real-world domains can be expressed as graphs and, more generally, as multi-relational knowledge graphs. Though reasoning and learning with knowledge graphs has traditionally been addressed by symbolic approaches, recent methods in (deep) representation learning has shown promising results for specialized tasks such as knowledge base completion. These approaches abandon the traditional symbolic paradigm by replacing symbols with vectors in Euclidean space. With few exceptions, symbolic and distributional approaches are explored in different communities and little is known about their respective strengths and weaknesses. In this work, we compare representation learning and relational learning on various relational classification and clustering tasks and analyse the complexity of the rules used implicitly by these approaches. Preliminary results reveal possible indicators that could help in choosing one approach over the other for particular knowledge graphs.
KBLRN : End-to-End Learning of Knowledge Base Representations with Latent, Relational, and Numerical Features
Jun 11, 2018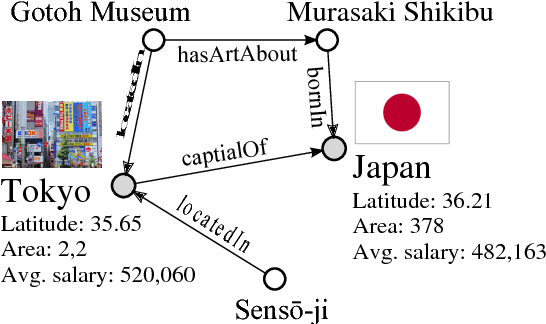

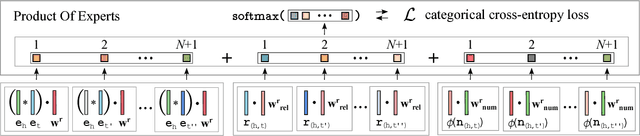
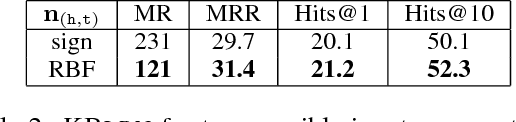
We present KBLRN, a framework for end-to-end learning of knowledge base representations from latent, relational, and numerical features. KBLRN integrates feature types with a novel combination of neural representation learning and probabilistic product of experts models. To the best of our knowledge, KBLRN is the first approach that learns representations of knowledge bases by integrating latent, relational, and numerical features. We show that instances of KBLRN outperform existing methods on a range of knowledge base completion tasks. We contribute a novel data sets enriching commonly used knowledge base completion benchmarks with numerical features. The data sets are available under a permissive BSD-3 license. We also investigate the impact numerical features have on the KB completion performance of KBLRN.
Towards a Spectrum of Graph Convolutional Networks
May 04, 2018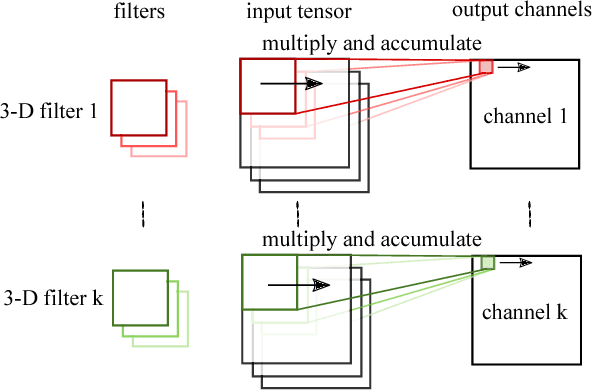
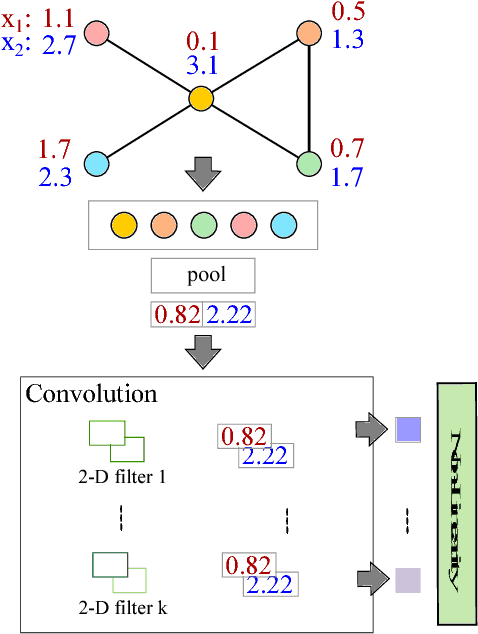
We present our ongoing work on understanding the limitations of graph convolutional networks (GCNs) as well as our work on generalizations of graph convolutions for representing more complex node attribute dependencies. Based on an analysis of GCNs with the help of the corresponding computation graphs, we propose a generalization of existing GCNs where the aggregation operations are (a) determined by structural properties of the local neighborhood graphs and (b) not restricted to weighted averages. We show that the proposed approach is strictly more expressive while requiring only a modest increase in the number of parameters and computations. We also show that the proposed generalization is identical to standard convolutional layers when applied to regular grid graphs.
TransRev: Modeling Reviews as Translations from Users to Items
Apr 18, 2018
The text of a review expresses the sentiment a customer has towards a particular product. This is exploited in sentiment analysis where machine learning models are used to predict the review score from the text of the review. Furthermore, the products costumers have purchased in the past are indicative of the products they will purchase in the future. This is what recommender systems exploit by learning models from purchase information to predict the items a customer might be interested in. We propose TransRev, an approach to the product recommendation problem that integrates ideas from recommender systems, sentiment analysis, and multi-relational learning into a joint learning objective. TransRev learns vector representations for users, items, and reviews. The embedding of a review is learned such that (a) it performs well as input feature of a regression model for sentiment prediction; and (b) it always translates the reviewer embedding to the embedding of the reviewed items. This allows TransRev to approximate a review embedding at test time as the difference of the embedding of each item and the user embedding. The approximated review embedding is then used with the regression model to predict the review score for each item. TransRev outperforms state of the art recommender systems on a large number of benchmark data sets. Moreover, it is able to retrieve, for each user and item, the review text from the training set whose embedding is most similar to the approximated review embedding.
Learning Graph Representations with Embedding Propagation
Oct 09, 2017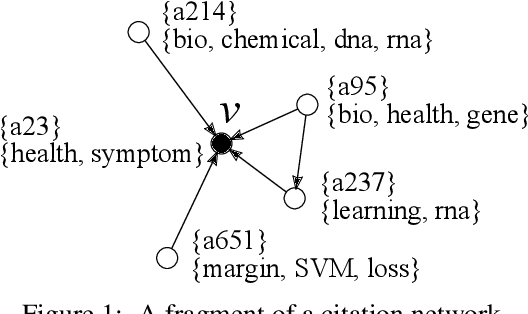
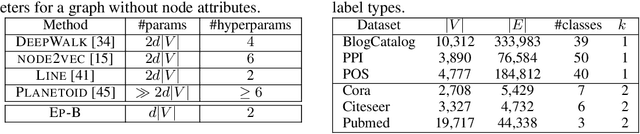
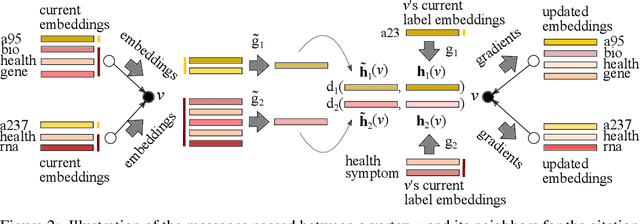
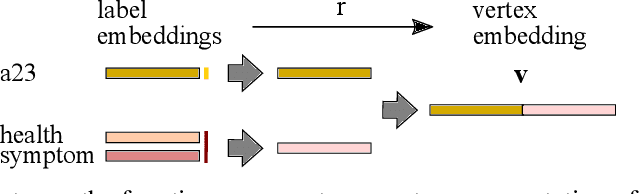
We propose Embedding Propagation (EP), an unsupervised learning framework for graph-structured data. EP learns vector representations of graphs by passing two types of messages between neighboring nodes. Forward messages consist of label representations such as representations of words and other attributes associated with the nodes. Backward messages consist of gradients that result from aggregating the label representations and applying a reconstruction loss. Node representations are finally computed from the representation of their labels. With significantly fewer parameters and hyperparameters an instance of EP is competitive with and often outperforms state of the art unsupervised and semi-supervised learning methods on a range of benchmark data sets.
Net2Vec: Deep Learning for the Network
May 10, 2017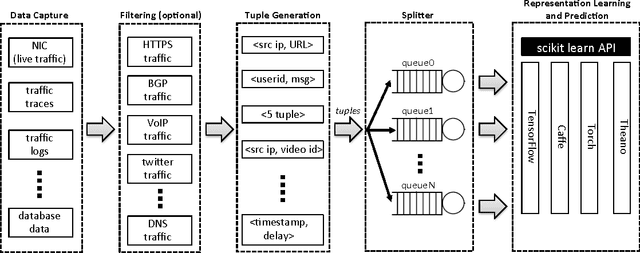
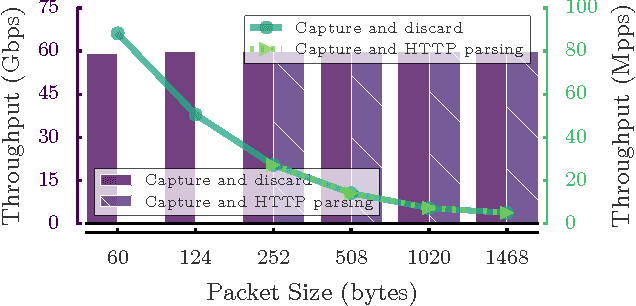
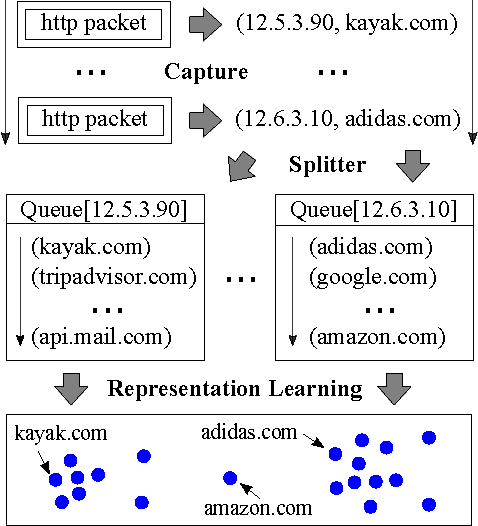
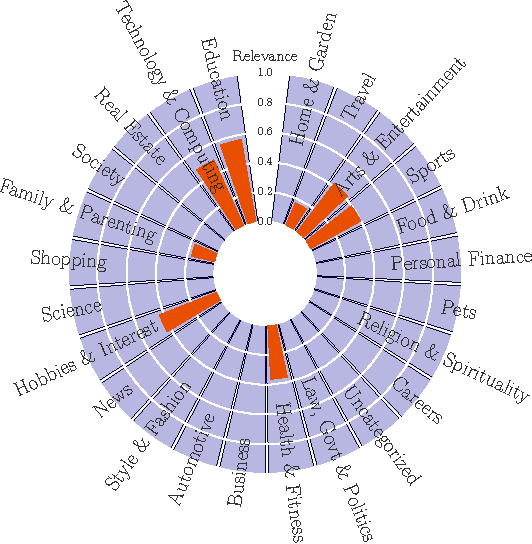
We present Net2Vec, a flexible high-performance platform that allows the execution of deep learning algorithms in the communication network. Net2Vec is able to capture data from the network at more than 60Gbps, transform it into meaningful tuples and apply predictions over the tuples in real time. This platform can be used for different purposes ranging from traffic classification to network performance analysis. Finally, we showcase the use of Net2Vec by implementing and testing a solution able to profile network users at line rate using traces coming from a real network. We show that the use of deep learning for this case outperforms the baseline method both in terms of accuracy and performance.