 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOL: Effortless Device Support for AI Frameworks without Source Code Changes
Mar 24, 2020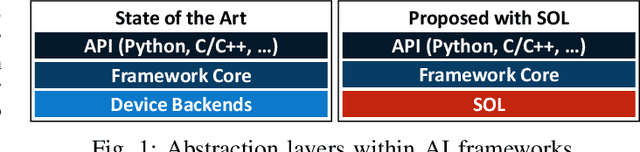
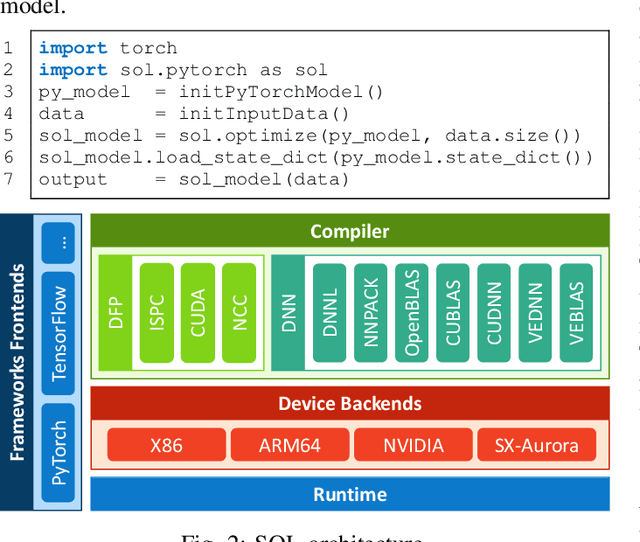
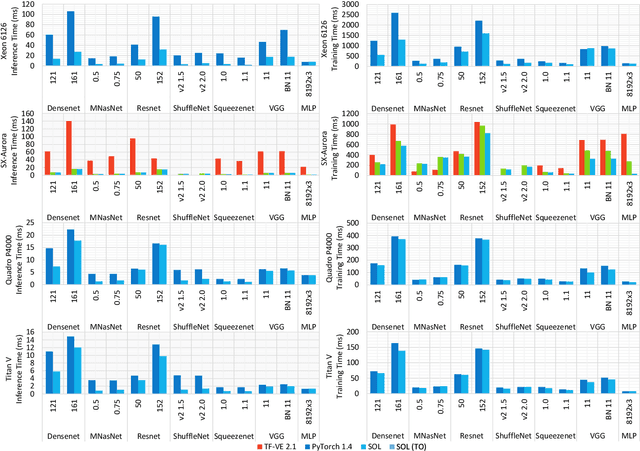
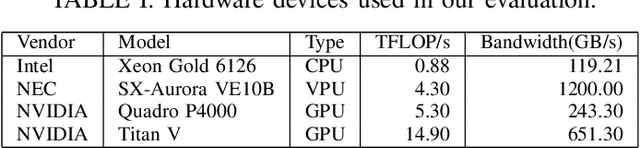
Modern high performance computing clusters heavily rely on accelerators to overcome the limited compute power of CPUs. These supercomputers run various applications from different domains such as simulations, numerical applications or artificial intelligence (AI). As a result, vendors need to be able to efficiently run a wide variety of workloads on their hardware. In the AI domain this is in particular exacerbated by the existence of a number of popular frameworks (e.g, PyTorch, TensorFlow, etc.) that have no common code base, and can vary in functionality. The code of these frameworks evolves quickly, making it expensive to keep up with all changes and potentially forcing developers to go through constant rounds of upstreaming. In this paper we explore how to provide hardware support in AI frameworks without changing the framework's source code in order to minimize maintenance overhead. We introduce SOL, an AI acceleration middleware that provides a hardware abstraction layer that allows us to transparently support heterogeneous hardware. As a proof of concept, we implemented SOL for PyTorch with three backends: CPUs, GPUs and vector processors.
BrainSlug: Transparent Acceleration of Deep Learning Through Depth-First Parallelism
Apr 23, 2018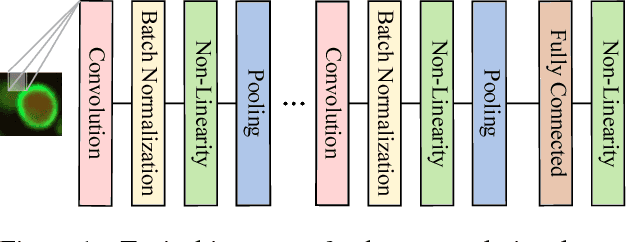
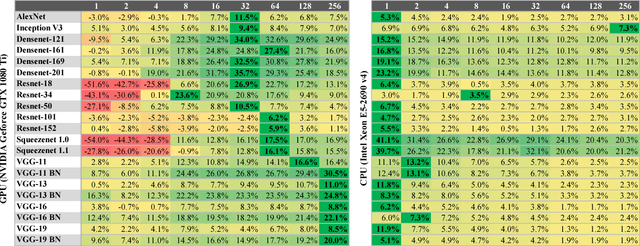
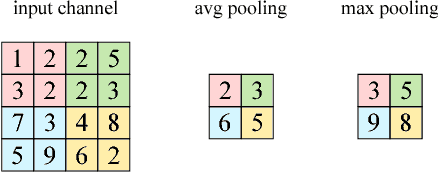
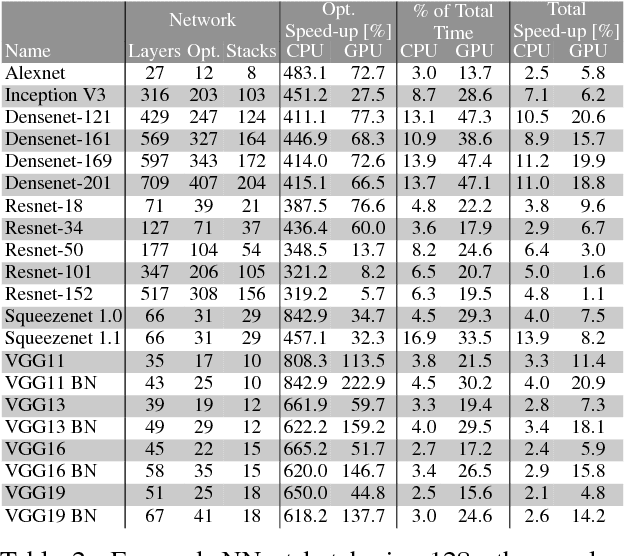
Neural network frameworks such as PyTorch and TensorFlow are the workhorses of numerous machine learning applications ranging from object recognition to machine translation. While these frameworks are versatile and straightforward to use, the training of and inference in deep neural networks is resource (energy, compute, and memory) intensive. In contrast to recent works focusing on algorithmic enhancements, we introduce BrainSlug, a framework that transparently accelerates neural network workloads by changing the default layer-by-layer processing to a depth-first approach, reducing the amount of data required by the computations and thus improving the performance of the available hardware caches. BrainSlug achieves performance improvements of up to 41.1% on CPUs and 35.7% on GPUs. These optimizations come at zero cost to the user as they do not require hardware changes and only need tiny adjustments to the software.
Representation Learning for Resource Usage Prediction
Feb 02, 2018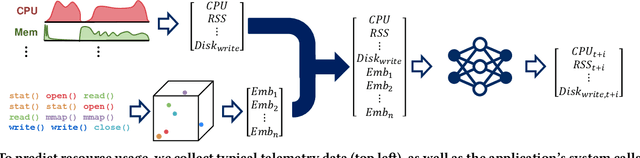

Creating a model of a computer system that can be used for tasks such as predicting future resource usage and detecting anomalies is a challenging problem. Most current systems rely on heuristics and overly simplistic assumptions about the workloads and system statistics. These heuristics are typically a one-size-fits-all solution so as to be applicable in a wide range of applications and systems environments. With this paper, we present our ongoing work of integrating systems telemetry ranging from standard resource usage statistics to kernel and library calls of applications into a machine learning model. Intuitively, such a ML model approximates, at any point in time, the state of a system and allows us to solve tasks such as resource usage prediction and anomaly detection. To achieve this goal, we leverage readily-available information that does not require any changes to the applications run on the system. We train recurrent neural networks to learn a model of the system under consideration. As a proof of concept, we train models specifically to predict future resource usage of running applications.
Net2Vec: Deep Learning for the Network
May 10, 2017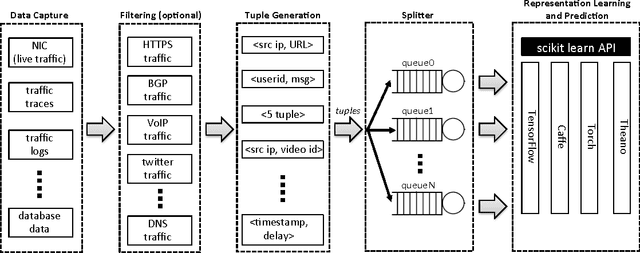
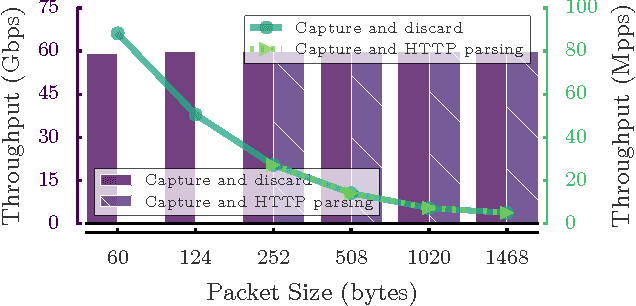
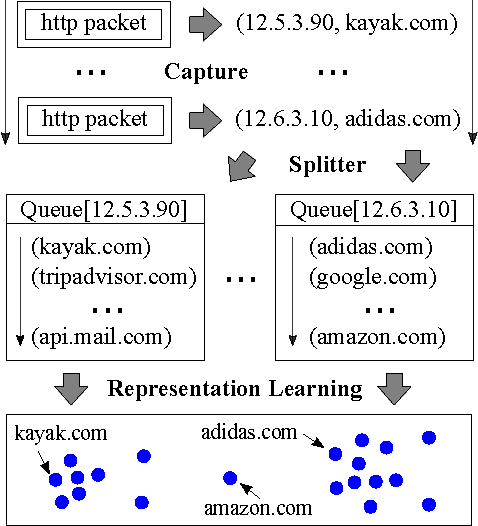
We present Net2Vec, a flexible high-performance platform that allows the execution of deep learning algorithms in the communication network. Net2Vec is able to capture data from the network at more than 60Gbps, transform it into meaningful tuples and apply predictions over the tuples in real time. This platform can be used for different purposes ranging from traffic classification to network performance analysis. Finally, we showcase the use of Net2Vec by implementing and testing a solution able to profile network users at line rate using traces coming from a real network. We show that the use of deep learning for this case outperforms the baseline method both in terms of accuracy and performance.