 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevAccSOL: Efficient and Transparent AI Vision Offloading for Mobile Robots
Mar 17, 2026Mobile robots are increasingly deployed for inspection, patrol, and search-and-rescue operations, relying on computer vision for perception, navigation, and autonomous decision-making. However, executing modern vision workloads onboard is challenging due to limited compute resources and strict energy constraints. While some platforms include embedded accelerators, these are typically tied to proprietary software stacks, leaving user-defined workloads to run on resource-constrained companion computers. We present vAccSOL, a framework for efficient and transparent execution of AI-based vision workloads across heterogeneous robotic and edge platforms. vAccSOL integrates two components: SOL, a neural network compiler that generates optimized inference libraries with minimal runtime dependencies, and vAccel, a lightweight execution framework that transparently dispatches inference locally on the robot or to nearby edge infrastructure. This combination enables hardware-optimized inference and flexible execution placement without requiring modifications to robot applications. We evaluate vAccSOL on a real-world testbed with a commercial quadruped robot and twelve deep learning models covering image classification, video classification, and semantic segmentation. Compared to a PyTorch compiler baseline, SOL achieves comparable or better inference performance. With edge offloading, vAccSOL reduces robot-side power consumption by up to 80% and edge-side power by up to 60% compared to PyTorch, while increasing vision pipeline frame rate by up to 24x, extending the operating lifetime of battery-powered robots.
Sorting Out the Bad Seeds: Automatic Classification of Cryptocurrency Abuse Reports
Oct 28, 2024Abuse reporting services collect reports about abuse victims have suffered. Accurate classification of the submitted reports is fundamental to analyzing the prevalence and financial impact of different abuse types (e.g., sextortion, investment, romance). Current classification approaches are problematic because they require the reporter to select the abuse type from a list, assuming the reporter has the necessary experience for the classification, which we show is frequently not the case, or require manual classification by analysts, which does not scale. To address these issues, this paper presents a novel approach to classify cryptocurrency abuse reports automatically. We first build a taxonomy of 19 frequently reported abuse types. Given as input the textual description written by the reporter, our classifier leverages a large language model (LLM) to interpret the text and assign it an abuse type in our taxonomy. We collect 290K cryptocurrency abuse reports from two popular reporting services: BitcoinAbuse and BBB's ScamTracker. We build ground truth datasets for 20K of those reports and use them to evaluate three designs for our LLM-based classifier and four LLMs, as well as a supervised ML classifier used as a baseline. Our LLM-based classifier achieves a precision of 0.92, a recall of 0.87, and an F1 score of 0.89, compared to an F1 score of 0.55 for the baseline. We demonstrate our classifier in two applications: providing financial loss statistics for fine-grained abuse types and generating tagged addresses for cryptocurrency analysis platforms.
Time for aCTIon: Automated Analysis of Cyber Threat Intelligence in the Wild
Jul 14, 2023
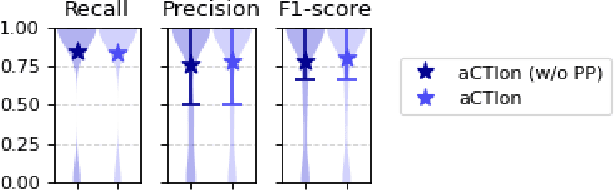
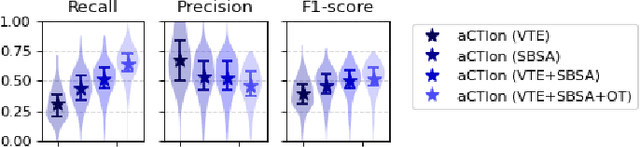
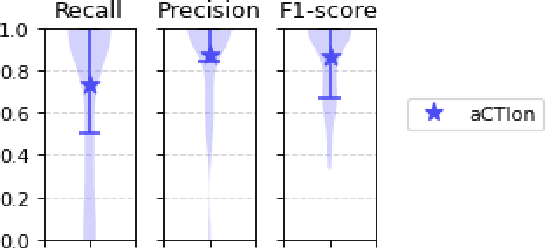
Cyber Threat Intelligence (CTI) plays a crucial role in assessing risks and enhancing security for organizations. However, the process of extracting relevant information from unstructured text sources can be expensive and time-consuming. Our empirical experience shows that existing tools for automated structured CTI extraction have performance limitations. Furthermore, the community lacks a common benchmark to quantitatively assess their performance. We fill these gaps providing a new large open benchmark dataset and aCTIon, a structured CTI information extraction tool. The dataset includes 204 real-world publicly available reports and their corresponding structured CTI information in STIX format. Our team curated the dataset involving three independent groups of CTI analysts working over the course of several months. To the best of our knowledge, this dataset is two orders of magnitude larger than previously released open source datasets. We then design aCTIon, leveraging recently introduced large language models (GPT3.5) in the context of two custom information extraction pipelines. We compare our method with 10 solutions presented in previous work, for which we develop our own implementations when open-source implementations were lacking. Our results show that aCTIon outperforms previous work for structured CTI extraction with an improvement of the F1-score from 10%points to 50%points across all tasks.
syslrn: Learning What to Monitor for Efficient Anomaly Detection
Mar 29, 2022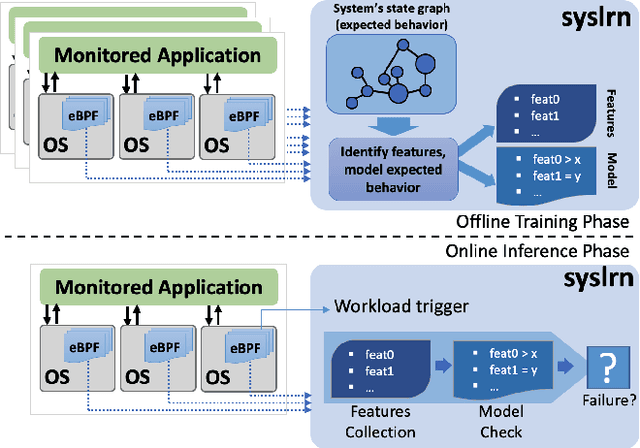
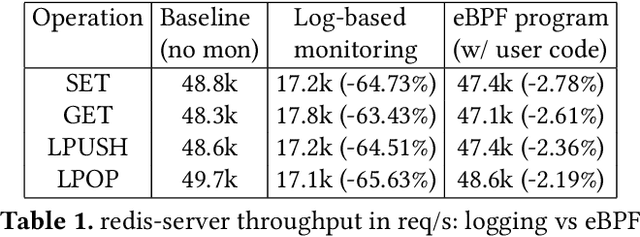
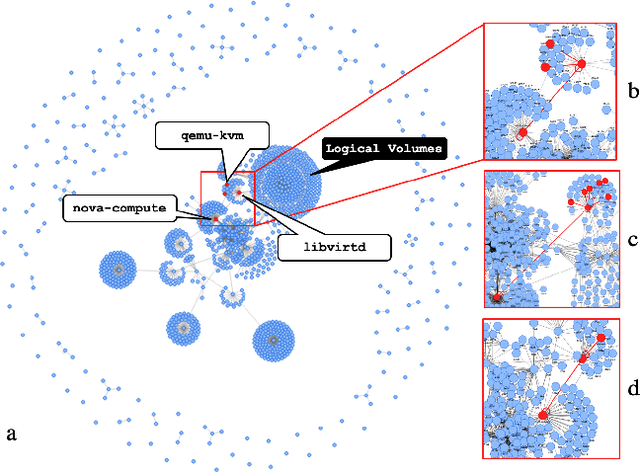
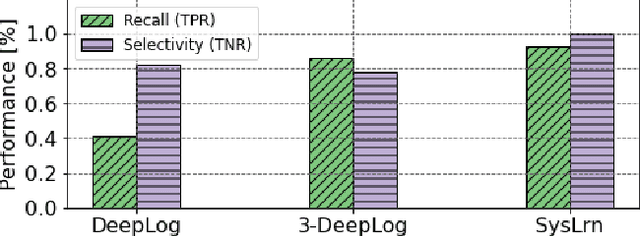
While monitoring system behavior to detect anomalies and failures is important, existing methods based on log-analysis can only be as good as the information contained in the logs, and other approaches that look at the OS-level software state introduce high overheads. We tackle the problem with syslrn, a system that first builds an understanding of a target system offline, and then tailors the online monitoring instrumentation based on the learned identifiers of normal behavior. While our syslrn prototype is still preliminary and lacks many features, we show in a case study for the monitoring of OpenStack failures that it can outperform state-of-the-art log-analysis systems with little overhead.
TransRev: Modeling Reviews as Translations from Users to Items
Apr 18, 2018
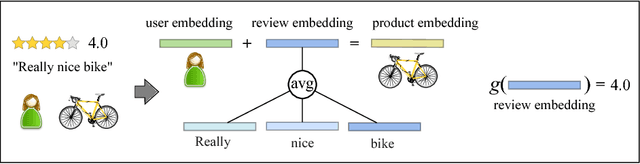
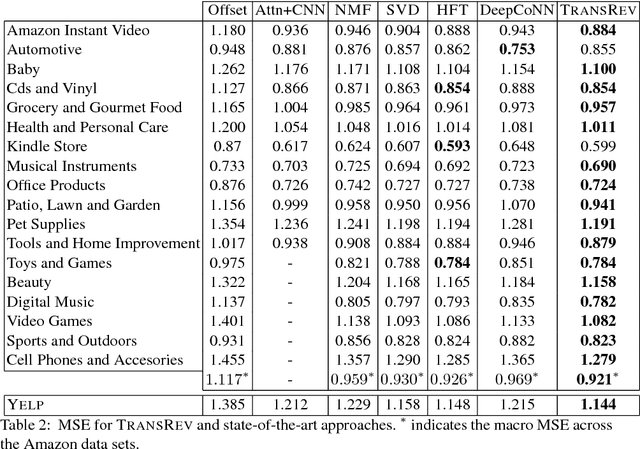
The text of a review expresses the sentiment a customer has towards a particular product. This is exploited in sentiment analysis where machine learning models are used to predict the review score from the text of the review. Furthermore, the products costumers have purchased in the past are indicative of the products they will purchase in the future. This is what recommender systems exploit by learning models from purchase information to predict the items a customer might be interested in. We propose TransRev, an approach to the product recommendation problem that integrates ideas from recommender systems, sentiment analysis, and multi-relational learning into a joint learning objective. TransRev learns vector representations for users, items, and reviews. The embedding of a review is learned such that (a) it performs well as input feature of a regression model for sentiment prediction; and (b) it always translates the reviewer embedding to the embedding of the reviewed items. This allows TransRev to approximate a review embedding at test time as the difference of the embedding of each item and the user embedding. The approximated review embedding is then used with the regression model to predict the review score for each item. TransRev outperforms state of the art recommender systems on a large number of benchmark data sets. Moreover, it is able to retrieve, for each user and item, the review text from the training set whose embedding is most similar to the approximated review embedding.
Net2Vec: Deep Learning for the Network
May 10, 2017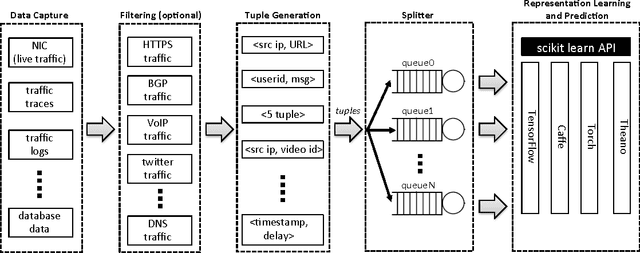
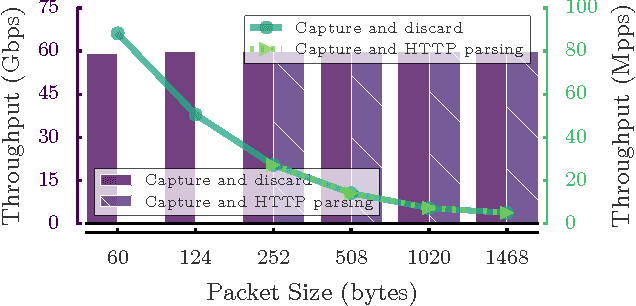
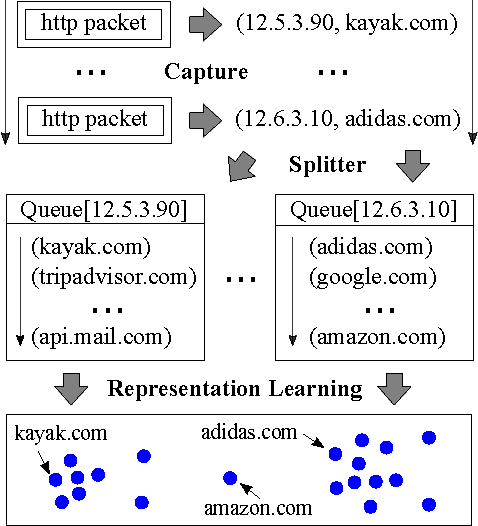
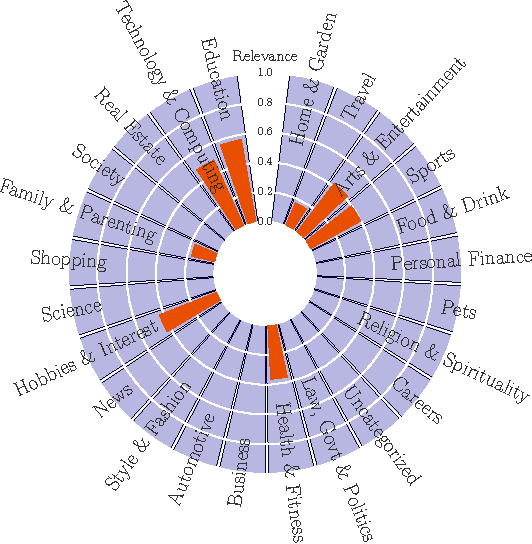
We present Net2Vec, a flexible high-performance platform that allows the execution of deep learning algorithms in the communication network. Net2Vec is able to capture data from the network at more than 60Gbps, transform it into meaningful tuples and apply predictions over the tuples in real time. This platform can be used for different purposes ranging from traffic classification to network performance analysis. Finally, we showcase the use of Net2Vec by implementing and testing a solution able to profile network users at line rate using traces coming from a real network. We show that the use of deep learning for this case outperforms the baseline method both in terms of accuracy and performance.