Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesyslrn: Learning What to Monitor for Efficient Anomaly Detection
Paper and Code
Mar 29, 2022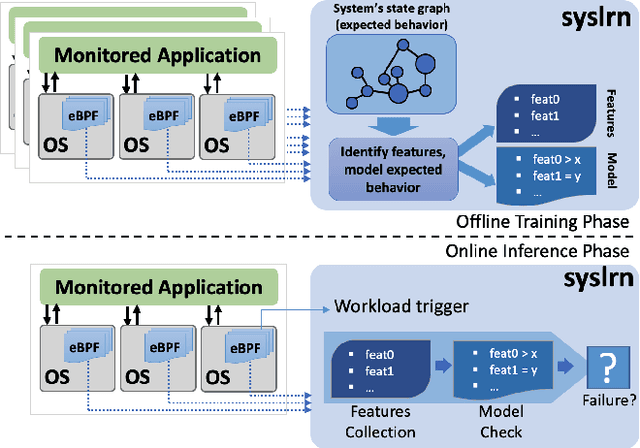
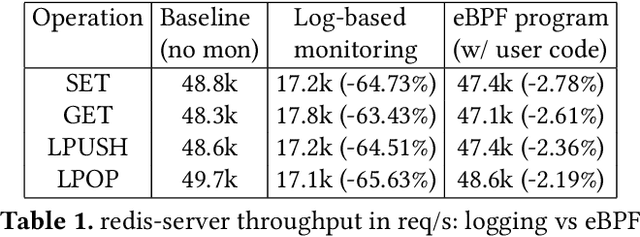
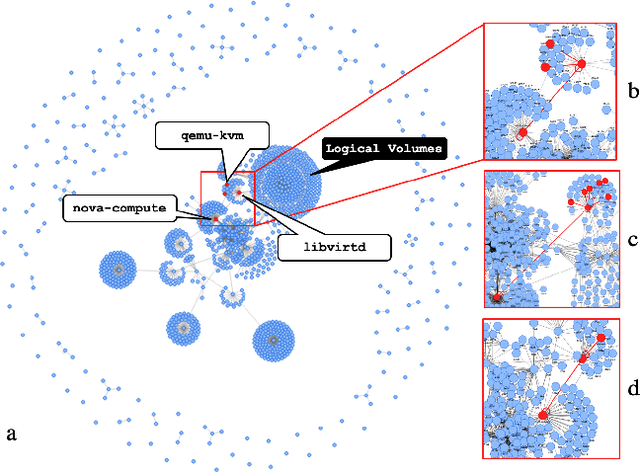
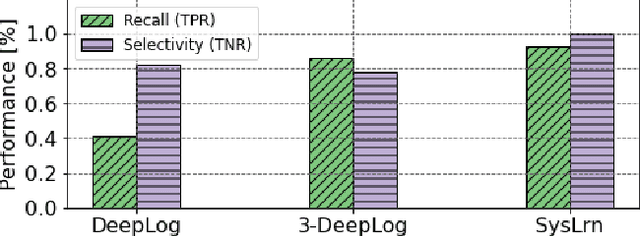
While monitoring system behavior to detect anomalies and failures is important, existing methods based on log-analysis can only be as good as the information contained in the logs, and other approaches that look at the OS-level software state introduce high overheads. We tackle the problem with syslrn, a system that first builds an understanding of a target system offline, and then tailors the online monitoring instrumentation based on the learned identifiers of normal behavior. While our syslrn prototype is still preliminary and lacks many features, we show in a case study for the monitoring of OpenStack failures that it can outperform state-of-the-art log-analysis systems with little overhead.
View paper on