 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSorting Out the Bad Seeds: Automatic Classification of Cryptocurrency Abuse Reports
Oct 28, 2024Abuse reporting services collect reports about abuse victims have suffered. Accurate classification of the submitted reports is fundamental to analyzing the prevalence and financial impact of different abuse types (e.g., sextortion, investment, romance). Current classification approaches are problematic because they require the reporter to select the abuse type from a list, assuming the reporter has the necessary experience for the classification, which we show is frequently not the case, or require manual classification by analysts, which does not scale. To address these issues, this paper presents a novel approach to classify cryptocurrency abuse reports automatically. We first build a taxonomy of 19 frequently reported abuse types. Given as input the textual description written by the reporter, our classifier leverages a large language model (LLM) to interpret the text and assign it an abuse type in our taxonomy. We collect 290K cryptocurrency abuse reports from two popular reporting services: BitcoinAbuse and BBB's ScamTracker. We build ground truth datasets for 20K of those reports and use them to evaluate three designs for our LLM-based classifier and four LLMs, as well as a supervised ML classifier used as a baseline. Our LLM-based classifier achieves a precision of 0.92, a recall of 0.87, and an F1 score of 0.89, compared to an F1 score of 0.55 for the baseline. We demonstrate our classifier in two applications: providing financial loss statistics for fine-grained abuse types and generating tagged addresses for cryptocurrency analysis platforms.
What Did I Do Wrong? Quantifying LLMs' Sensitivity and Consistency to Prompt Engineering
Jun 18, 2024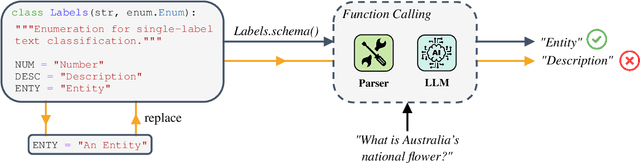
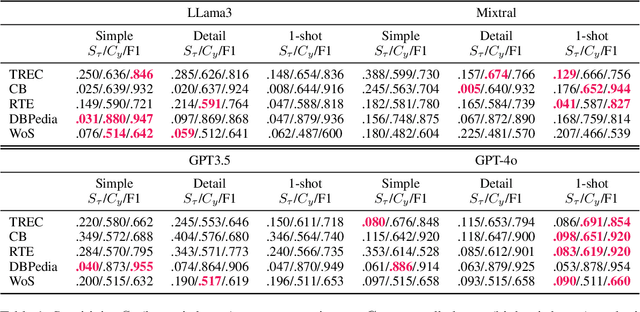
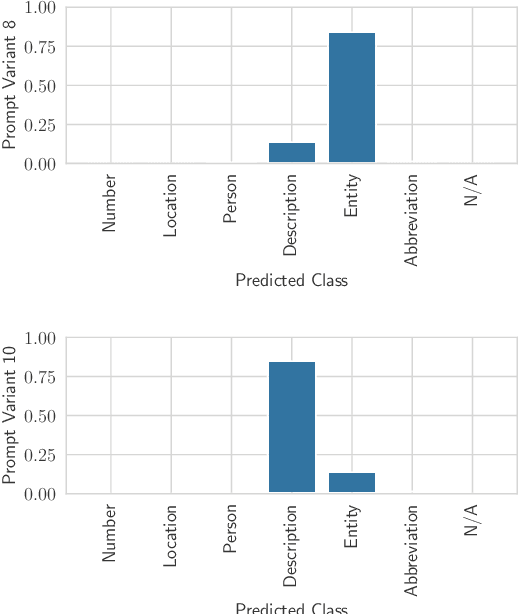
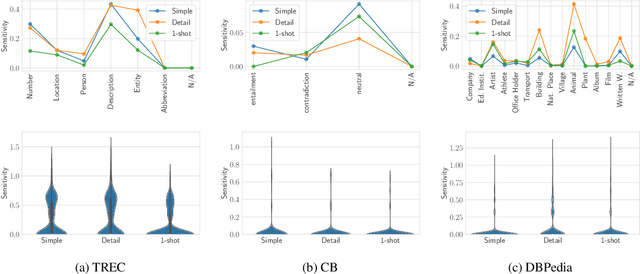
Large Language Models (LLMs) changed the way we design and interact with software systems. Their ability to process and extract information from text has drastically improved productivity in a number of routine tasks. Developers that want to include these models in their software stack, however, face a dreadful challenge: debugging their inconsistent behavior across minor variations of the prompt. We therefore introduce two metrics for classification tasks, namely sensitivity and consistency, which are complementary to task performance. First, sensitivity measures changes of predictions across rephrasings of the prompt, and does not require access to ground truth labels. Instead, consistency measures how predictions vary across rephrasings for elements of the same class. We perform an empirical comparison of these metrics on text classification tasks, using them as guideline for understanding failure modes of the LLM. Our hope is that sensitivity and consistency will be powerful allies in automatic prompt engineering frameworks to obtain LLMs that balance robustness with performance.
AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents
Apr 09, 2024The advances made by Large Language Models (LLMs) have led to the pursuit of LLM agents that can solve intricate, multi-step reasoning tasks. As with any research pursuit, benchmarking and evaluation are key corner stones to efficient and reliable progress. However, existing benchmarks are often narrow and simply compute overall task success. To face these issues, we propose AgentQuest -- a framework where (i) both benchmarks and metrics are modular and easily extensible through well documented and easy-to-use APIs; (ii) we offer two new evaluation metrics that can reliably track LLM agent progress while solving a task. We exemplify the utility of the metrics on two use cases wherein we identify common failure points and refine the agent architecture to obtain a significant performance increase. Together with the research community, we hope to extend AgentQuest further and therefore we make it available under https://github.com/nec-research/agentquest.
Time for aCTIon: Automated Analysis of Cyber Threat Intelligence in the Wild
Jul 14, 2023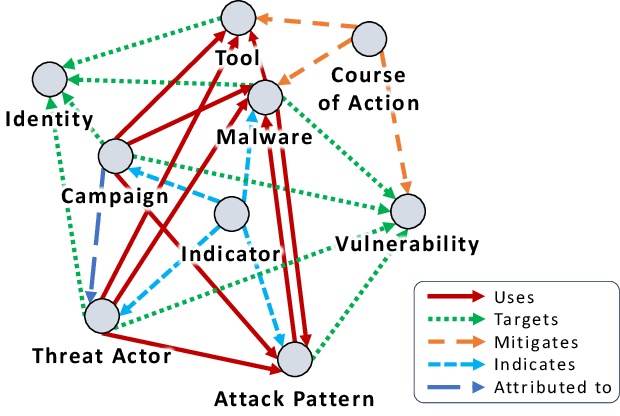
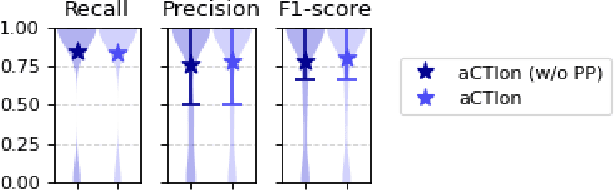
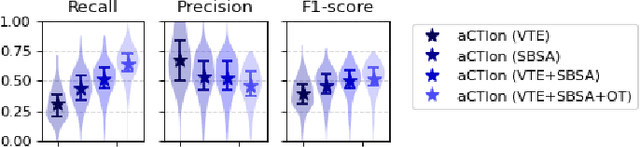
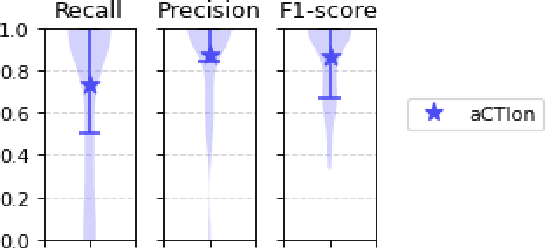
Cyber Threat Intelligence (CTI) plays a crucial role in assessing risks and enhancing security for organizations. However, the process of extracting relevant information from unstructured text sources can be expensive and time-consuming. Our empirical experience shows that existing tools for automated structured CTI extraction have performance limitations. Furthermore, the community lacks a common benchmark to quantitatively assess their performance. We fill these gaps providing a new large open benchmark dataset and aCTIon, a structured CTI information extraction tool. The dataset includes 204 real-world publicly available reports and their corresponding structured CTI information in STIX format. Our team curated the dataset involving three independent groups of CTI analysts working over the course of several months. To the best of our knowledge, this dataset is two orders of magnitude larger than previously released open source datasets. We then design aCTIon, leveraging recently introduced large language models (GPT3.5) in the context of two custom information extraction pipelines. We compare our method with 10 solutions presented in previous work, for which we develop our own implementations when open-source implementations were lacking. Our results show that aCTIon outperforms previous work for structured CTI extraction with an improvement of the F1-score from 10%points to 50%points across all tasks.
syslrn: Learning What to Monitor for Efficient Anomaly Detection
Mar 29, 2022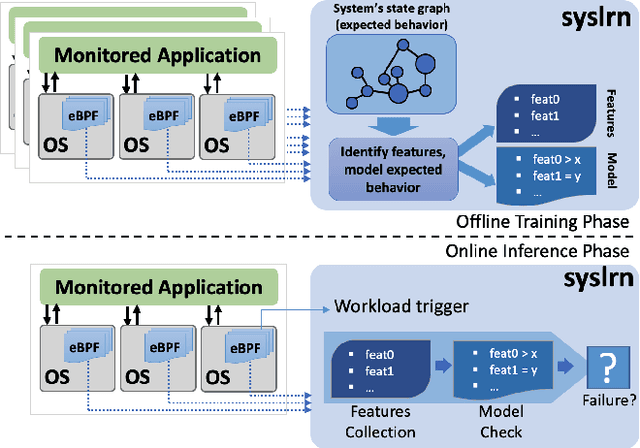
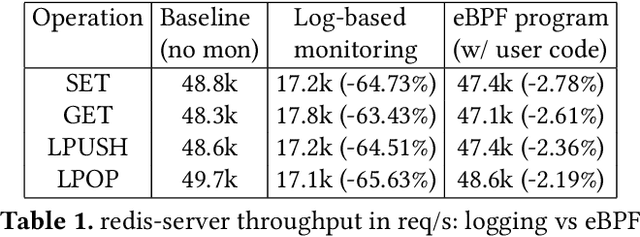
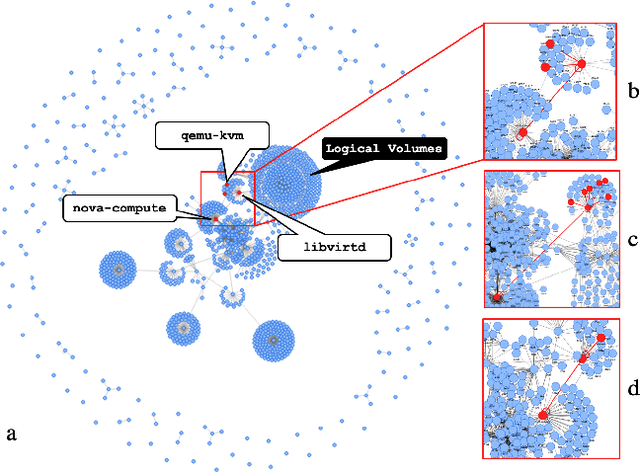
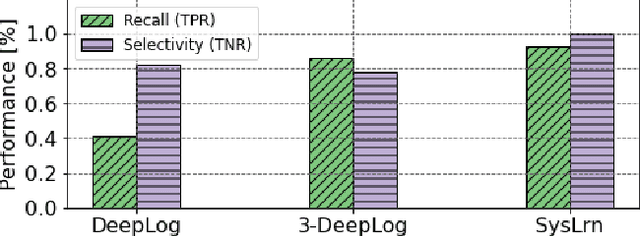
While monitoring system behavior to detect anomalies and failures is important, existing methods based on log-analysis can only be as good as the information contained in the logs, and other approaches that look at the OS-level software state introduce high overheads. We tackle the problem with syslrn, a system that first builds an understanding of a target system offline, and then tailors the online monitoring instrumentation based on the learned identifiers of normal behavior. While our syslrn prototype is still preliminary and lacks many features, we show in a case study for the monitoring of OpenStack failures that it can outperform state-of-the-art log-analysis systems with little overhead.
Running Neural Networks on the NIC
Sep 04, 2020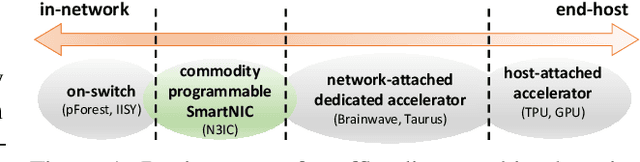
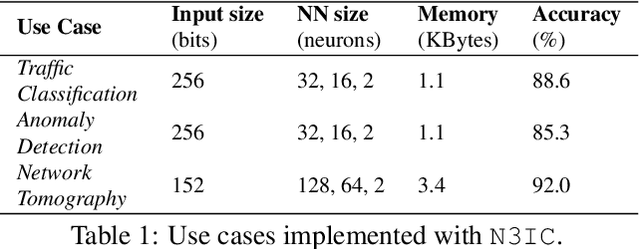
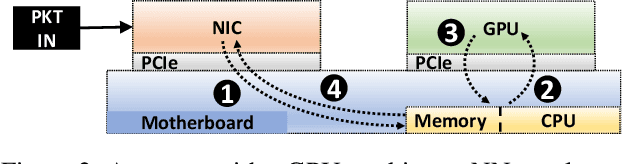

In this paper we show that the data plane of commodity programmable (Network Interface Cards) NICs can run neural network inference tasks required by packet monitoring applications, with low overhead. This is particularly important as the data transfer costs to the host system and dedicated machine learning accelerators, e.g., GPUs, can be more expensive than the processing task itself. We design and implement our system -- N3IC -- on two different NICs and we show that it can greatly benefit three different network monitoring use cases that require machine learning inference as first-class-primitive. N3IC can perform inference for millions of network flows per second, while forwarding traffic at 40Gb/s. Compared to an equivalent solution implemented on a general purpose CPU, N3IC can provide 100x lower processing latency, with 1.5x increase in throughput.