 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPenBench: Benchmarking Generative Agents for Penetration Testing
Oct 04, 2024



Generative AI agents, software systems powered by Large Language Models (LLMs), are emerging as a promising approach to automate cybersecurity tasks. Among the others, penetration testing is a challenging field due to the task complexity and the diverse strategies to simulate cyber-attacks. Despite growing interest and initial studies in automating penetration testing with generative agents, there remains a significant gap in the form of a comprehensive and standard framework for their evaluation and development. This paper introduces AutoPenBench, an open benchmark for evaluating generative agents in automated penetration testing. We present a comprehensive framework that includes 33 tasks, each representing a vulnerable system that the agent has to attack. Tasks are of increasing difficulty levels, including in-vitro and real-world scenarios. We assess the agent performance with generic and specific milestones that allow us to compare results in a standardised manner and understand the limits of the agent under test. We show the benefits of AutoPenBench by testing two agent architectures: a fully autonomous and a semi-autonomous supporting human interaction. We compare their performance and limitations. For example, the fully autonomous agent performs unsatisfactorily achieving a 21% Success Rate (SR) across the benchmark, solving 27% of the simple tasks and only one real-world task. In contrast, the assisted agent demonstrates substantial improvements, with 64% of SR. AutoPenBench allows us also to observe how different LLMs like GPT-4o or OpenAI o1 impact the ability of the agents to complete the tasks. We believe that our benchmark fills the gap with a standard and flexible framework to compare penetration testing agents on a common ground. We hope to extend AutoPenBench along with the research community by making it available under https://github.com/lucagioacchini/auto-pen-bench.
Generic Multi-modal Representation Learning for Network Traffic Analysis
May 04, 2024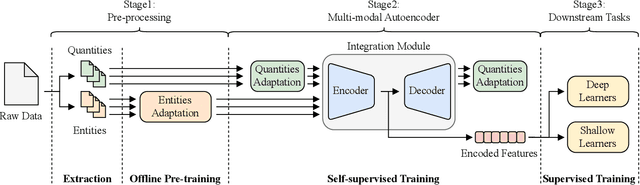
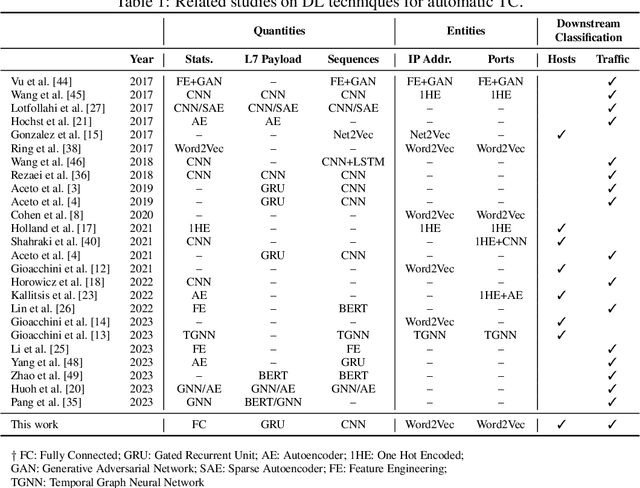
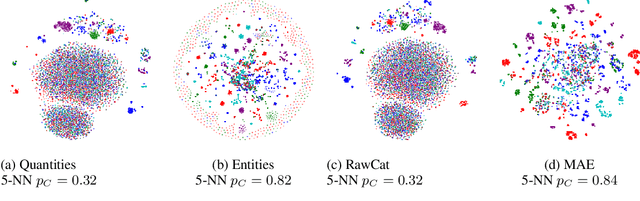
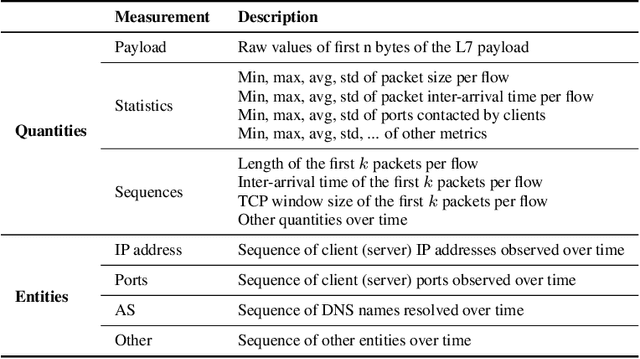
Network traffic analysis is fundamental for network management, troubleshooting, and security. Tasks such as traffic classification, anomaly detection, and novelty discovery are fundamental for extracting operational information from network data and measurements. We witness the shift from deep packet inspection and basic machine learning to Deep Learning (DL) approaches where researchers define and test a custom DL architecture designed for each specific problem. We here advocate the need for a general DL architecture flexible enough to solve different traffic analysis tasks. We test this idea by proposing a DL architecture based on generic data adaptation modules, followed by an integration module that summarises the extracted information into a compact and rich intermediate representation (i.e. embeddings). The result is a flexible Multi-modal Autoencoder (MAE) pipeline that can solve different use cases. We demonstrate the architecture with traffic classification (TC) tasks since they allow us to quantitatively compare results with state-of-the-art solutions. However, we argue that the MAE architecture is generic and can be used to learn representations useful in multiple scenarios. On TC, the MAE performs on par or better than alternatives while avoiding cumbersome feature engineering, thus streamlining the adoption of DL solutions for traffic analysis.
AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents
Apr 09, 2024The advances made by Large Language Models (LLMs) have led to the pursuit of LLM agents that can solve intricate, multi-step reasoning tasks. As with any research pursuit, benchmarking and evaluation are key corner stones to efficient and reliable progress. However, existing benchmarks are often narrow and simply compute overall task success. To face these issues, we propose AgentQuest -- a framework where (i) both benchmarks and metrics are modular and easily extensible through well documented and easy-to-use APIs; (ii) we offer two new evaluation metrics that can reliably track LLM agent progress while solving a task. We exemplify the utility of the metrics on two use cases wherein we identify common failure points and refine the agent architecture to obtain a significant performance increase. Together with the research community, we hope to extend AgentQuest further and therefore we make it available under https://github.com/nec-research/agentquest.
Benchmarking Evolutionary Community Detection Algorithms in Dynamic Networks
Jan 11, 2024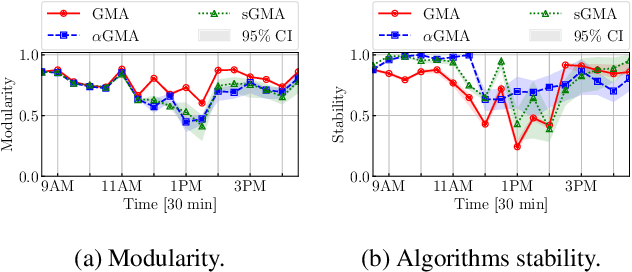

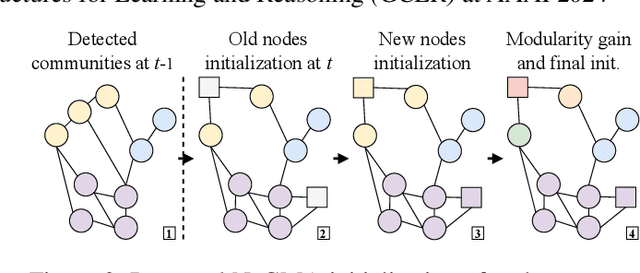

In dynamic complex networks, entities interact and form network communities that evolve over time. Among the many static Community Detection (CD) solutions, the modularity-based Louvain, or Greedy Modularity Algorithm (GMA), is widely employed in real-world applications due to its intuitiveness and scalability. Nevertheless, addressing CD in dynamic graphs remains an open problem, since the evolution of the network connections may poison the identification of communities, which may be evolving at a slower pace. Hence, naively applying GMA to successive network snapshots may lead to temporal inconsistencies in the communities. Two evolutionary adaptations of GMA, sGMA and $\alpha$GMA, have been proposed to tackle this problem. Yet, evaluating the performance of these methods and understanding to which scenarios each one is better suited is challenging because of the lack of a comprehensive set of metrics and a consistent ground truth. To address these challenges, we propose (i) a benchmarking framework for evolutionary CD algorithms in dynamic networks and (ii) a generalised modularity-based approach (NeGMA). Our framework allows us to generate synthetic community-structured graphs and design evolving scenarios with nine basic graph transformations occurring at different rates. We evaluate performance through three metrics we define, i.e. Correctness, Delay, and Stability. Our findings reveal that $\alpha$GMA is well-suited for detecting intermittent transformations, but struggles with abrupt changes; sGMA achieves superior stability, but fails to detect emerging communities; and NeGMA appears a well-balanced solution, excelling in responsiveness and instantaneous transformations detection.
* Accepted at the 4th Workshop on Graphs and more Complex structures for Learning and Reasoning (GCLR) at AAAI 2024