 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Praise of Stubbornness: The Case for Cognitive-Dissonance-Aware Knowledge Updates in LLMs
Feb 05, 2025Despite remarkable capabilities, large language models (LLMs) struggle to continually update their knowledge without catastrophic forgetting. In contrast, humans effortlessly integrate new information, detect conflicts with existing beliefs, and selectively update their mental models. This paper introduces a cognitive-inspired investigation paradigm to study continual knowledge updating in LLMs. We implement two key components inspired by human cognition: (1) Dissonance and Familiarity Awareness, analyzing model behavior to classify information as novel, familiar, or dissonant; and (2) Targeted Network Updates, which track neural activity to identify frequently used (stubborn) and rarely used (plastic) neurons. Through carefully designed experiments in controlled settings, we uncover a number of empirical findings demonstrating the potential of this approach. First, dissonance detection is feasible using simple activation and gradient features, suggesting potential for cognitive-inspired training. Second, we find that non-dissonant updates largely preserve prior knowledge regardless of targeting strategy, revealing inherent robustness in LLM knowledge integration. Most critically, we discover that dissonant updates prove catastrophically destructive to the model's knowledge base, indiscriminately affecting even information unrelated to the current updates. This suggests fundamental limitations in how neural networks handle contradictions and motivates the need for new approaches to knowledge updating that better mirror human cognitive mechanisms.
Generic Multi-modal Representation Learning for Network Traffic Analysis
May 04, 2024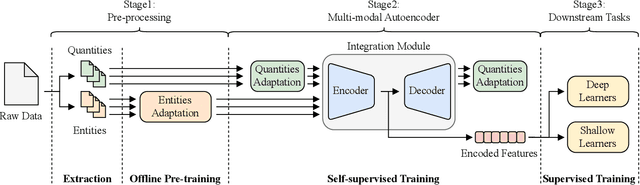
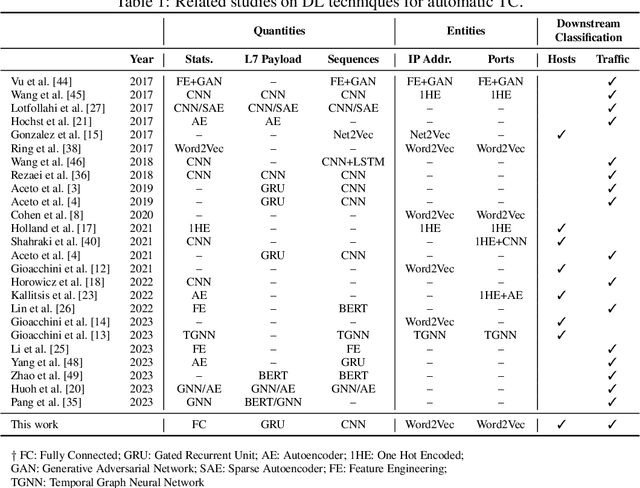
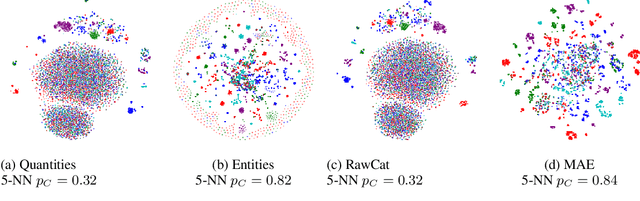
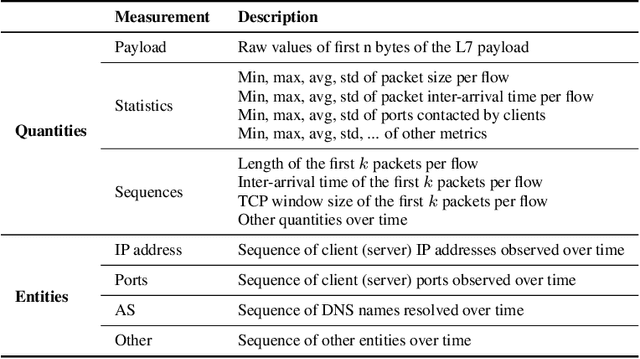
Network traffic analysis is fundamental for network management, troubleshooting, and security. Tasks such as traffic classification, anomaly detection, and novelty discovery are fundamental for extracting operational information from network data and measurements. We witness the shift from deep packet inspection and basic machine learning to Deep Learning (DL) approaches where researchers define and test a custom DL architecture designed for each specific problem. We here advocate the need for a general DL architecture flexible enough to solve different traffic analysis tasks. We test this idea by proposing a DL architecture based on generic data adaptation modules, followed by an integration module that summarises the extracted information into a compact and rich intermediate representation (i.e. embeddings). The result is a flexible Multi-modal Autoencoder (MAE) pipeline that can solve different use cases. We demonstrate the architecture with traffic classification (TC) tasks since they allow us to quantitatively compare results with state-of-the-art solutions. However, we argue that the MAE architecture is generic and can be used to learn representations useful in multiple scenarios. On TC, the MAE performs on par or better than alternatives while avoiding cumbersome feature engineering, thus streamlining the adoption of DL solutions for traffic analysis.
Data Augmentation for Traffic Classification
Jan 23, 2024



Data Augmentation (DA) -- enriching training data by adding synthetic samples -- is a technique widely adopted in Computer Vision (CV) and Natural Language Processing (NLP) tasks to improve models performance. Yet, DA has struggled to gain traction in networking contexts, particularly in Traffic Classification (TC) tasks. In this work, we fulfill this gap by benchmarking 18 augmentation functions applied to 3 TC datasets using packet time series as input representation and considering a variety of training conditions. Our results show that (i) DA can reap benefits previously unexplored, (ii) augmentations acting on time series sequence order and masking are better suited for TC than amplitude augmentations and (iii) basic models latent space analysis can help understanding the positive/negative effects of augmentations on classification performance.
Toward Generative Data Augmentation for Traffic Classification
Oct 21, 2023
Data Augmentation (DA)-augmenting training data with synthetic samples-is wildly adopted in Computer Vision (CV) to improve models performance. Conversely, DA has not been yet popularized in networking use cases, including Traffic Classification (TC). In this work, we present a preliminary study of 14 hand-crafted DAs applied on the MIRAGE19 dataset. Our results (i) show that DA can reap benefits previously unexplored in TC and (ii) foster a research agenda on the use of generative models to automate DA design.
Contrastive Learning and Data Augmentation in Traffic Classification Using a Flowpic Input Representation
Sep 18, 2023Over the last years we witnessed a renewed interest towards Traffic Classification (TC) captivated by the rise of Deep Learning (DL). Yet, the vast majority of TC literature lacks code artifacts, performance assessments across datasets and reference comparisons against Machine Learning (ML) methods. Among those works, a recent study from IMC'22 [17] is worth of attention since it adopts recent DL methodologies (namely, few-shot learning, self-supervision via contrastive learning and data augmentation) appealing for networking as they enable to learn from a few samples and transfer across datasets. The main result of [17] on the UCDAVIS19, ISCX-VPN and ISCX-Tor datasets is that, with such DL methodologies, 100 input samples are enough to achieve very high accuracy using an input representation called "flowpic" (i.e., a per-flow 2d histograms of the packets size evolution over time). In this paper (i) we reproduce [17] on the same datasets and (ii) we replicate its most salient aspect (the importance of data augmentation) on three additional public datasets, MIRAGE-19, MIRAGE-22 and UTMOBILENET21. While we confirm most of the original results, we also found a 20% accuracy drop on some of the investigated scenarios due to a data shift in the original dataset that we uncovered. Additionally, our study validates that the data augmentation strategies studied in [17] perform well on other datasets too. In the spirit of reproducibility and replicability we make all artifacts (code and data) available at [10].
Many or Few Samples? Comparing Transfer, Contrastive and Meta-Learning in Encrypted Traffic Classification
May 21, 2023



The popularity of Deep Learning (DL), coupled with network traffic visibility reduction due to the increased adoption of HTTPS, QUIC and DNS-SEC, re-ignited interest towards Traffic Classification (TC). However, to tame the dependency from task-specific large labeled datasets we need to find better ways to learn representations that are valid across tasks. In this work we investigate this problem comparing transfer learning, meta-learning and contrastive learning against reference Machine Learning (ML) tree-based and monolithic DL models (16 methods total). Using two publicly available datasets, namely MIRAGE19 (40 classes) and AppClassNet (500 classes), we show that (i) using large datasets we can obtain more general representations, (ii) contrastive learning is the best methodology and (iii) meta-learning the worst one, and (iv) while ML tree-based cannot handle large tasks but fits well small tasks, by means of reusing learned representations, DL methods are reaching tree-based models performance also for small tasks.
Continuous-Time Functional Diffusion Processes
Mar 01, 2023
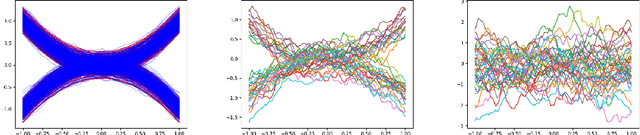


We introduce functional diffusion processes (FDPs), which generalize traditional score-based diffusion models to infinite-dimensional function spaces. FDPs require a new mathematical framework to describe the forward and backward dynamics, and several extensions to derive practical training objectives. These include infinite-dimensional versions of the Girsanov theorem, in order to be able to compute an ELBO, and of the sampling theorem, in order to guarantee that functional evaluations in a countable set of points are equivalent to infinite-dimensional functions. We use FDPs to build a new breed of generative models in function spaces, which do not require specialized network architectures, and that can work with any kind of continuous data. Our results on synthetic and real data illustrate the advantages of FDPs in simplifying the design requirements of diffusion models.
User-aware WLAN Transmit Power Control in the Wild
Feb 21, 2023In Wireless Local Area Networks (WLANs), Access point (AP) transmit power influences (i) received signal quality for users and thus user throughput, (ii) user association and thus load across APs and (iii) AP coverage ranges and thus interference in the network. Despite decades of academic research, transmit power levels are still, in practice, statically assigned to satisfy uniform coverage objectives. Yet each network comes with its unique distribution of users in space, calling for a power control that adapts to users' probabilities of presence, for example, placing the areas with higher interference probabilities where user density is the lowest. Although nice on paper, putting this simple idea in practice comes with a number of challenges, with gains that are difficult to estimate, if any at all. This paper is the first to address these challenges and evaluate in a production network serving thousands of daily users the benefits of a user-aware transmit power control system. Along the way, we contribute a novel approach to reason about user densities of presence from historical IEEE 802.11k data, as well as a new machine learning approach to impute missing signal-strength measurements. Results of a thorough experimental campaign show feasibility and quantify the gains: compared to state-of-the-art solutions, the new system can increase the median signal strength by 15dBm, while decreasing airtime interference at the same time. This comes at an affordable cost of a 5dBm decrease in uplink signal due to lack of terminal cooperation.
"It's a Match!" -- A Benchmark of Task Affinity Scores for Joint Learning
Jan 07, 2023



While the promises of Multi-Task Learning (MTL) are attractive, characterizing the conditions of its success is still an open problem in Deep Learning. Some tasks may benefit from being learned together while others may be detrimental to one another. From a task perspective, grouping cooperative tasks while separating competing tasks is paramount to reap the benefits of MTL, i.e., reducing training and inference costs. Therefore, estimating task affinity for joint learning is a key endeavor. Recent work suggests that the training conditions themselves have a significant impact on the outcomes of MTL. Yet, the literature is lacking of a benchmark to assess the effectiveness of tasks affinity estimation techniques and their relation with actual MTL performance. In this paper, we take a first step in recovering this gap by (i) defining a set of affinity scores by both revisiting contributions from previous literature as well presenting new ones and (ii) benchmarking them on the Taskonomy dataset. Our empirical campaign reveals how, even in a small-scale scenario, task affinity scoring does not correlate well with actual MTL performance. Yet, some metrics can be more indicative than others.
Cross-network transferable neural models for WLAN interference estimation
Nov 25, 2022



Airtime interference is a key performance indicator for WLANs, measuring, for a given time period, the percentage of time during which a node is forced to wait for other transmissions before to transmitting or receiving. Being able to accurately estimate interference resulting from a given state change (e.g., channel, bandwidth, power) would allow a better control of WLAN resources, assessing the impact of a given configuration before actually implementing it. In this paper, we adopt a principled approach to interference estimation in WLANs. We first use real data to characterize the factors that impact it, and derive a set of relevant synthetic workloads for a controlled comparison of various deep learning architectures in terms of accuracy, generalization and robustness to outlier data. We find, unsurprisingly, that Graph Convolutional Networks (GCNs) yield the best performance overall, leveraging the graph structure inherent to campus WLANs. We notice that, unlike e.g. LSTMs, they struggle to learn the behavior of specific nodes, unless given the node indexes in addition. We finally verify GCN model generalization capabilities, by applying trained models on operational deployments unseen at training time.