 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning and Data Augmentation in Traffic Classification Using a Flowpic Input Representation
Sep 18, 2023Over the last years we witnessed a renewed interest towards Traffic Classification (TC) captivated by the rise of Deep Learning (DL). Yet, the vast majority of TC literature lacks code artifacts, performance assessments across datasets and reference comparisons against Machine Learning (ML) methods. Among those works, a recent study from IMC'22 [17] is worth of attention since it adopts recent DL methodologies (namely, few-shot learning, self-supervision via contrastive learning and data augmentation) appealing for networking as they enable to learn from a few samples and transfer across datasets. The main result of [17] on the UCDAVIS19, ISCX-VPN and ISCX-Tor datasets is that, with such DL methodologies, 100 input samples are enough to achieve very high accuracy using an input representation called "flowpic" (i.e., a per-flow 2d histograms of the packets size evolution over time). In this paper (i) we reproduce [17] on the same datasets and (ii) we replicate its most salient aspect (the importance of data augmentation) on three additional public datasets, MIRAGE-19, MIRAGE-22 and UTMOBILENET21. While we confirm most of the original results, we also found a 20% accuracy drop on some of the investigated scenarios due to a data shift in the original dataset that we uncovered. Additionally, our study validates that the data augmentation strategies studied in [17] perform well on other datasets too. In the spirit of reproducibility and replicability we make all artifacts (code and data) available at [10].
Cross-network transferable neural models for WLAN interference estimation
Nov 25, 2022



Airtime interference is a key performance indicator for WLANs, measuring, for a given time period, the percentage of time during which a node is forced to wait for other transmissions before to transmitting or receiving. Being able to accurately estimate interference resulting from a given state change (e.g., channel, bandwidth, power) would allow a better control of WLAN resources, assessing the impact of a given configuration before actually implementing it. In this paper, we adopt a principled approach to interference estimation in WLANs. We first use real data to characterize the factors that impact it, and derive a set of relevant synthetic workloads for a controlled comparison of various deep learning architectures in terms of accuracy, generalization and robustness to outlier data. We find, unsurprisingly, that Graph Convolutional Networks (GCNs) yield the best performance overall, leveraging the graph structure inherent to campus WLANs. We notice that, unlike e.g. LSTMs, they struggle to learn the behavior of specific nodes, unless given the node indexes in addition. We finally verify GCN model generalization capabilities, by applying trained models on operational deployments unseen at training time.
A Lightweight, Efficient and Explainable-by-Design Convolutional Neural Network for Internet Traffic Classification
Feb 11, 2022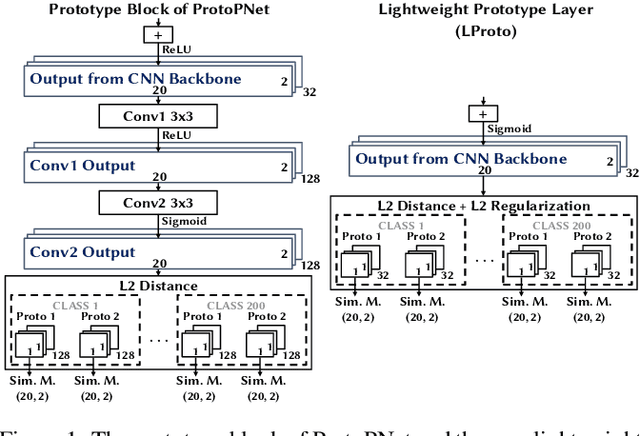


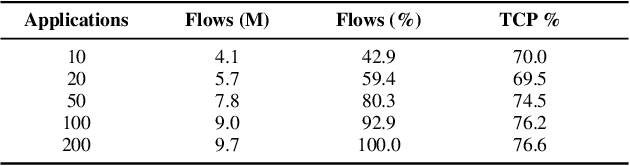
Traffic classification, i.e. the identification of the type of applications flowing in a network, is a strategic task for numerous activities (e.g., intrusion detection, routing). This task faces some critical challenges that current deep learning approaches do not address. The design of current approaches do not take into consideration the fact that networking hardware (e.g., routers) often runs with limited computational resources. Further, they do not meet the need for faithful explainability highlighted by regulatory bodies. Finally, these traffic classifiers are evaluated on small datasets which fail to reflect the diversity of applications in real commercial settings. Therefore, this paper introduces a Lightweight, Efficient and eXplainable-by-design convolutional neural network (LEXNet) for Internet traffic classification, which relies on a new residual block (for lightweight and efficiency purposes) and prototype layer (for explainability). Based on a commercial-grade dataset, our evaluation shows that LEXNet succeeds to maintain the same accuracy as the best performing state-of-the-art neural network, while providing the additional features previously mentioned. Moreover, we demonstrate that LEXNet significantly reduces the model size and inference time compared to the state-of-the-art neural networks with explainability-by-design and post hoc explainability methods. Finally, we illustrate the explainability feature of our approach, which stems from the communication of detected application prototypes to the end-user, and we highlight the faithfulness of LEXNet explanations through a comparison with post hoc methods.