 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much is Enough? A Study on Diffusion Times in Score-based Generative Models
Jun 10, 2022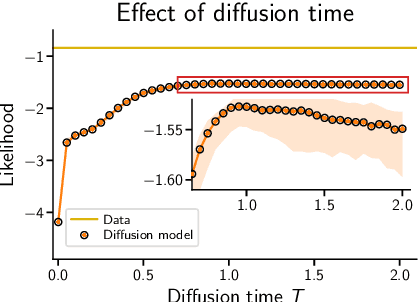
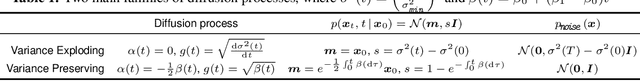


Score-based diffusion models are a class of generative models whose dynamics is described by stochastic differential equations that map noise into data. While recent works have started to lay down a theoretical foundation for these models, an analytical understanding of the role of the diffusion time T is still lacking. Current best practice advocates for a large T to ensure that the forward dynamics brings the diffusion sufficiently close to a known and simple noise distribution; however, a smaller value of T should be preferred for a better approximation of the score-matching objective and higher computational efficiency. Starting from a variational interpretation of diffusion models, in this work we quantify this trade-off, and suggest a new method to improve quality and efficiency of both training and sampling, by adopting smaller diffusion times. Indeed, we show how an auxiliary model can be used to bridge the gap between the ideal and the simulated forward dynamics, followed by a standard reverse diffusion process. Empirical results support our analysis; for image data, our method is competitive w.r.t. the state-of-the-art, according to standard sample quality metrics and log-likelihood.
Quality Monitoring and Assessment of Deployed Deep Learning Models for Network AIOps
Feb 28, 2022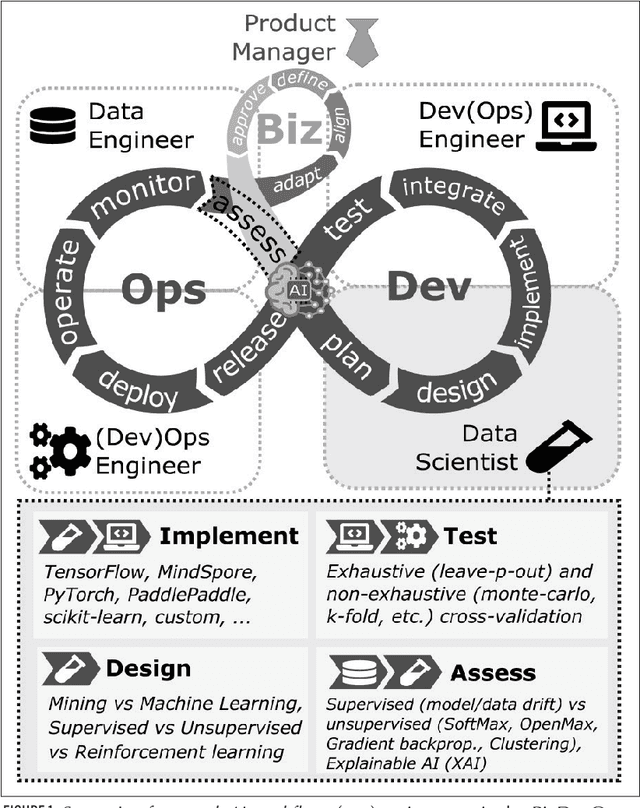

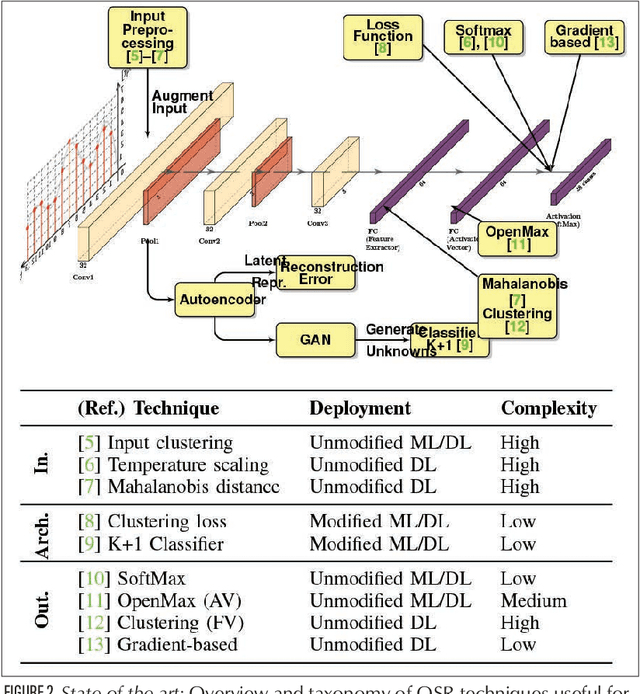
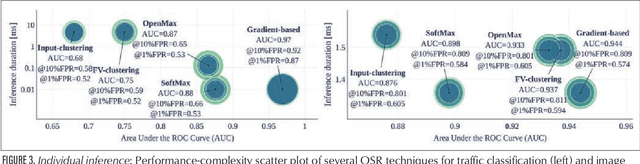
Artificial Intelligence (AI) has recently attracted a lot of attention, transitioning from research labs to a wide range of successful deployments in many fields, which is particularly true for Deep Learning (DL) techniques. Ultimately, DL models being software artifacts, they need to be regularly maintained and updated: AIOps is the logical extension of the DevOps software development practices to AI-software applied to network operation and management. In the lifecycle of a DL model deployment, it is important to assess the quality of deployed models, to detect "stale" models and prioritize their update. In this article, we cover the issue in the context of network management, proposing simple yet effective techniques for (i) quality assessment of individual inference, and for (ii) overall model quality tracking over multiple inferences, that we apply to two use cases, representative of the network management and image recognition fields.
A Lightweight, Efficient and Explainable-by-Design Convolutional Neural Network for Internet Traffic Classification
Feb 11, 2022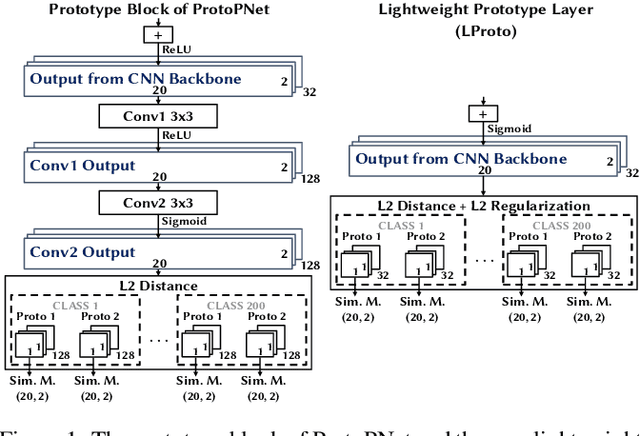


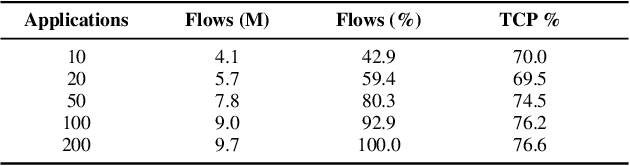
Traffic classification, i.e. the identification of the type of applications flowing in a network, is a strategic task for numerous activities (e.g., intrusion detection, routing). This task faces some critical challenges that current deep learning approaches do not address. The design of current approaches do not take into consideration the fact that networking hardware (e.g., routers) often runs with limited computational resources. Further, they do not meet the need for faithful explainability highlighted by regulatory bodies. Finally, these traffic classifiers are evaluated on small datasets which fail to reflect the diversity of applications in real commercial settings. Therefore, this paper introduces a Lightweight, Efficient and eXplainable-by-design convolutional neural network (LEXNet) for Internet traffic classification, which relies on a new residual block (for lightweight and efficiency purposes) and prototype layer (for explainability). Based on a commercial-grade dataset, our evaluation shows that LEXNet succeeds to maintain the same accuracy as the best performing state-of-the-art neural network, while providing the additional features previously mentioned. Moreover, we demonstrate that LEXNet significantly reduces the model size and inference time compared to the state-of-the-art neural networks with explainability-by-design and post hoc explainability methods. Finally, we illustrate the explainability feature of our approach, which stems from the communication of detected application prototypes to the end-user, and we highlight the faithfulness of LEXNet explanations through a comparison with post hoc methods.
Thinkback: Task-SpecificOut-of-Distribution Detection
Jul 13, 2021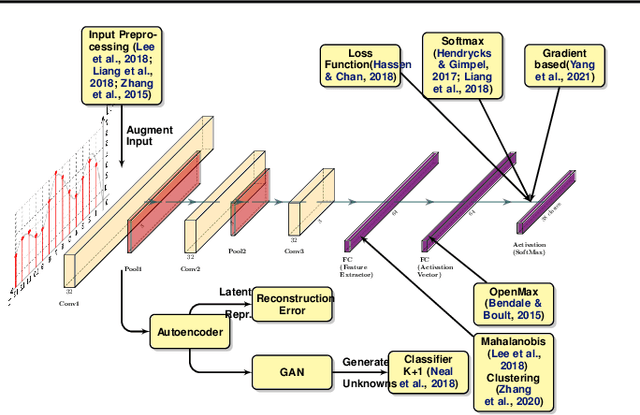

The increased success of Deep Learning (DL) has recently sparked large-scale deployment of DL models in many diverse industry segments. Yet, a crucial weakness of supervised model is the inherent difficulty in handling out-of-distribution samples, i.e., samples belonging to classes that were not presented to the model at training time. We propose in this paper a novel way to formulate the out-of-distribution detection problem, tailored for DL models. Our method does not require fine tuning process on training data, yet is significantly more accurate than the state of the art for out-of-distribution detection.
A First Look at Class Incremental Learning in Deep Learning Mobile Traffic Classification
Jul 09, 2021
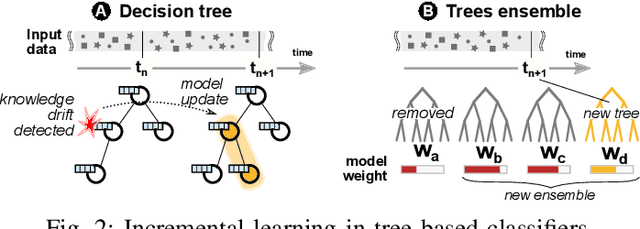

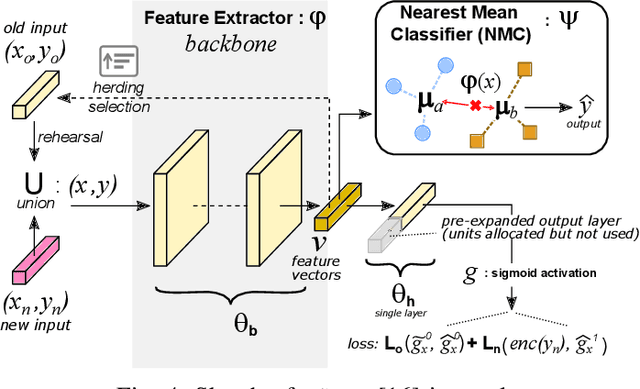
The recent popularity growth of Deep Learning (DL) re-ignited the interest towards traffic classification, with several studies demonstrating the accuracy of DL-based classifiers to identify Internet applications' traffic. Even with the aid of hardware accelerators (GPUs, TPUs), DL model training remains expensive, and limits the ability to operate frequent model updates necessary to fit to the ever evolving nature of Internet traffic, and mobile traffic in particular. To address this pain point, in this work we explore Incremental Learning (IL) techniques to add new classes to models without a full retraining, hence speeding up model's updates cycle. We consider iCarl, a state of the art IL method, and MIRAGE-2019, a public dataset with traffic from 40 Android apps, aiming to understand "if there is a case for incremental learning in traffic classification". By dissecting iCarl internals, we discuss ways to improve its design, contributing a revised version, namely iCarl+. Despite our analysis reveals their infancy, IL techniques are a promising research area on the roadmap towards automated DL-based traffic analysis systems.
Deep Learning and Traffic Classification: Lessons learned from a commercial-grade dataset with hundreds of encrypted and zero-day applications
Apr 07, 2021The increasing success of Machine Learning (ML) and Deep Learning (DL) has recently re-sparked interest towards traffic classification. While classification of known traffic is a well investigated subject with supervised classification tools (such as ML and DL models) are known to provide satisfactory performance, detection of unknown (or zero-day) traffic is more challenging and typically handled by unsupervised techniques (such as clustering algorithms). In this paper, we share our experience on a commercial-grade DL traffic classification engine that is able to (i) identify known applications from encrypted traffic, as well as (ii) handle unknown zero-day applications. In particular, our contribution for (i) is to perform a thorough assessment of state of the art traffic classifiers in commercial-grade settings comprising few thousands of very fine grained application labels, as opposite to the few tens of classes generally targeted in academic evaluations. Additionally, we contribute to the problem of (ii) detection of zero-day applications by proposing a novel technique, tailored for DL models, that is significantly more accurate and light-weight than the state of the art. Summarizing our main findings, we gather that (i) while ML and DL models are both equally able to provide satisfactory solution for classification of known traffic, however (ii) the non-linear feature extraction process of the DL backbone provides sizeable advantages for the detection of unknown classes.
Heterogeneous Data-Aware Federated Learning
Nov 12, 2020

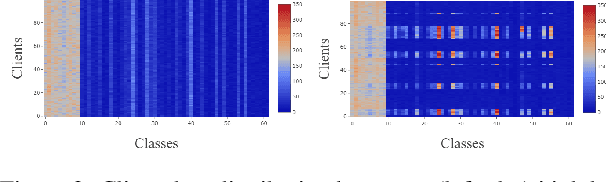
Federated learning (FL) is an appealing concept to perform distributed training of Neural Networks (NN) while keeping data private. With the industrialization of the FL framework, we identify several problems hampering its successful deployment, such as presence of non i.i.d data, disjoint classes, signal multi-modality across datasets. In this work, we address these problems by proposing a novel method that not only (1) aggregates generic model parameters (e.g. a common set of task generic NN layers) on server (e.g. in traditional FL), but also (2) keeps a set of parameters (e.g, a set of task specific NN layer) specific to each client. We validate our method on the traditionally used public benchmarks (e.g., Femnist) as well as on our proprietary collected dataset (i.e., traffic classification). Results show the benefit of our method, with significant advantage on extreme cases.