 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFMI: Estimating Mutual Information on Rectified Flow for Text-to-Image Alignment
Mar 18, 2025Rectified Flow (RF) models trained with a Flow matching framework have achieved state-of-the-art performance on Text-to-Image (T2I) conditional generation. Yet, multiple benchmarks show that synthetic images can still suffer from poor alignment with the prompt, i.e., images show wrong attribute binding, subject positioning, numeracy, etc. While the literature offers many methods to improve T2I alignment, they all consider only Diffusion Models, and require auxiliary datasets, scoring models, and linguistic analysis of the prompt. In this paper we aim to address these gaps. First, we introduce RFMI, a novel Mutual Information (MI) estimator for RF models that uses the pre-trained model itself for the MI estimation. Then, we investigate a self-supervised fine-tuning approach for T2I alignment based on RFMI that does not require auxiliary information other than the pre-trained model itself. Specifically, a fine-tuning set is constructed by selecting synthetic images generated from the pre-trained RF model and having high point-wise MI between images and prompts. Our experiments on MI estimation benchmarks demonstrate the validity of RFMI, and empirical fine-tuning on SD3.5-Medium confirms the effectiveness of RFMI for improving T2I alignment while maintaining image quality.
Fine-grained Attention in Hierarchical Transformers for Tabular Time-series
Jun 21, 2024



Tabular data is ubiquitous in many real-life systems. In particular, time-dependent tabular data, where rows are chronologically related, is typically used for recording historical events, e.g., financial transactions, healthcare records, or stock history. Recently, hierarchical variants of the attention mechanism of transformer architectures have been used to model tabular time-series data. At first, rows (or columns) are encoded separately by computing attention between their fields. Subsequently, encoded rows (or columns) are attended to one another to model the entire tabular time-series. While efficient, this approach constrains the attention granularity and limits its ability to learn patterns at the field-level across separate rows, or columns. We take a first step to address this gap by proposing Fieldy, a fine-grained hierarchical model that contextualizes fields at both the row and column levels. We compare our proposal against state of the art models on regression and classification tasks using public tabular time-series datasets. Our results show that combining row-wise and column-wise attention improves performance without increasing model size. Code and data are available at https://github.com/raphaaal/fieldy.
Information Theoretic Text-to-Image Alignment
May 31, 2024Diffusion models for Text-to-Image (T2I) conditional generation have seen tremendous success recently. Despite their success, accurately capturing user intentions with these models still requires a laborious trial and error process. This challenge is commonly identified as a model alignment problem, an issue that has attracted considerable attention by the research community. Instead of relying on fine-grained linguistic analyses of prompts, human annotation, or auxiliary vision-language models to steer image generation, in this work we present a novel method that relies on an information-theoretic alignment measure. In a nutshell, our method uses self-supervised fine-tuning and relies on point-wise mutual information between prompts and images to define a synthetic training set to induce model alignment. Our comparative analysis shows that our method is on-par or superior to the state-of-the-art, yet requires nothing but a pre-trained denoising network to estimate MI and a lightweight fine-tuning strategy.
Data Augmentation for Traffic Classification
Jan 23, 2024



Data Augmentation (DA) -- enriching training data by adding synthetic samples -- is a technique widely adopted in Computer Vision (CV) and Natural Language Processing (NLP) tasks to improve models performance. Yet, DA has struggled to gain traction in networking contexts, particularly in Traffic Classification (TC) tasks. In this work, we fulfill this gap by benchmarking 18 augmentation functions applied to 3 TC datasets using packet time series as input representation and considering a variety of training conditions. Our results show that (i) DA can reap benefits previously unexplored, (ii) augmentations acting on time series sequence order and masking are better suited for TC than amplitude augmentations and (iii) basic models latent space analysis can help understanding the positive/negative effects of augmentations on classification performance.
Toward Generative Data Augmentation for Traffic Classification
Oct 21, 2023
Data Augmentation (DA)-augmenting training data with synthetic samples-is wildly adopted in Computer Vision (CV) to improve models performance. Conversely, DA has not been yet popularized in networking use cases, including Traffic Classification (TC). In this work, we present a preliminary study of 14 hand-crafted DAs applied on the MIRAGE19 dataset. Our results (i) show that DA can reap benefits previously unexplored in TC and (ii) foster a research agenda on the use of generative models to automate DA design.
Contrastive Learning and Data Augmentation in Traffic Classification Using a Flowpic Input Representation
Sep 18, 2023Over the last years we witnessed a renewed interest towards Traffic Classification (TC) captivated by the rise of Deep Learning (DL). Yet, the vast majority of TC literature lacks code artifacts, performance assessments across datasets and reference comparisons against Machine Learning (ML) methods. Among those works, a recent study from IMC'22 [17] is worth of attention since it adopts recent DL methodologies (namely, few-shot learning, self-supervision via contrastive learning and data augmentation) appealing for networking as they enable to learn from a few samples and transfer across datasets. The main result of [17] on the UCDAVIS19, ISCX-VPN and ISCX-Tor datasets is that, with such DL methodologies, 100 input samples are enough to achieve very high accuracy using an input representation called "flowpic" (i.e., a per-flow 2d histograms of the packets size evolution over time). In this paper (i) we reproduce [17] on the same datasets and (ii) we replicate its most salient aspect (the importance of data augmentation) on three additional public datasets, MIRAGE-19, MIRAGE-22 and UTMOBILENET21. While we confirm most of the original results, we also found a 20% accuracy drop on some of the investigated scenarios due to a data shift in the original dataset that we uncovered. Additionally, our study validates that the data augmentation strategies studied in [17] perform well on other datasets too. In the spirit of reproducibility and replicability we make all artifacts (code and data) available at [10].
Many or Few Samples? Comparing Transfer, Contrastive and Meta-Learning in Encrypted Traffic Classification
May 21, 2023



The popularity of Deep Learning (DL), coupled with network traffic visibility reduction due to the increased adoption of HTTPS, QUIC and DNS-SEC, re-ignited interest towards Traffic Classification (TC). However, to tame the dependency from task-specific large labeled datasets we need to find better ways to learn representations that are valid across tasks. In this work we investigate this problem comparing transfer learning, meta-learning and contrastive learning against reference Machine Learning (ML) tree-based and monolithic DL models (16 methods total). Using two publicly available datasets, namely MIRAGE19 (40 classes) and AppClassNet (500 classes), we show that (i) using large datasets we can obtain more general representations, (ii) contrastive learning is the best methodology and (iii) meta-learning the worst one, and (iv) while ML tree-based cannot handle large tasks but fits well small tasks, by means of reusing learned representations, DL methods are reaching tree-based models performance also for small tasks.
"It's a Match!" -- A Benchmark of Task Affinity Scores for Joint Learning
Jan 07, 2023



While the promises of Multi-Task Learning (MTL) are attractive, characterizing the conditions of its success is still an open problem in Deep Learning. Some tasks may benefit from being learned together while others may be detrimental to one another. From a task perspective, grouping cooperative tasks while separating competing tasks is paramount to reap the benefits of MTL, i.e., reducing training and inference costs. Therefore, estimating task affinity for joint learning is a key endeavor. Recent work suggests that the training conditions themselves have a significant impact on the outcomes of MTL. Yet, the literature is lacking of a benchmark to assess the effectiveness of tasks affinity estimation techniques and their relation with actual MTL performance. In this paper, we take a first step in recovering this gap by (i) defining a set of affinity scores by both revisiting contributions from previous literature as well presenting new ones and (ii) benchmarking them on the Taskonomy dataset. Our empirical campaign reveals how, even in a small-scale scenario, task affinity scoring does not correlate well with actual MTL performance. Yet, some metrics can be more indicative than others.
How Much is Enough? A Study on Diffusion Times in Score-based Generative Models
Jun 10, 2022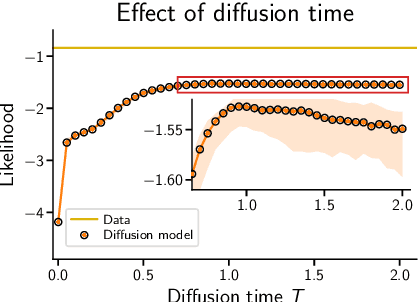
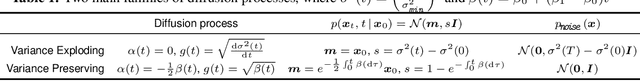


Score-based diffusion models are a class of generative models whose dynamics is described by stochastic differential equations that map noise into data. While recent works have started to lay down a theoretical foundation for these models, an analytical understanding of the role of the diffusion time T is still lacking. Current best practice advocates for a large T to ensure that the forward dynamics brings the diffusion sufficiently close to a known and simple noise distribution; however, a smaller value of T should be preferred for a better approximation of the score-matching objective and higher computational efficiency. Starting from a variational interpretation of diffusion models, in this work we quantify this trade-off, and suggest a new method to improve quality and efficiency of both training and sampling, by adopting smaller diffusion times. Indeed, we show how an auxiliary model can be used to bridge the gap between the ideal and the simulated forward dynamics, followed by a standard reverse diffusion process. Empirical results support our analysis; for image data, our method is competitive w.r.t. the state-of-the-art, according to standard sample quality metrics and log-likelihood.
A Lightweight, Efficient and Explainable-by-Design Convolutional Neural Network for Internet Traffic Classification
Feb 11, 2022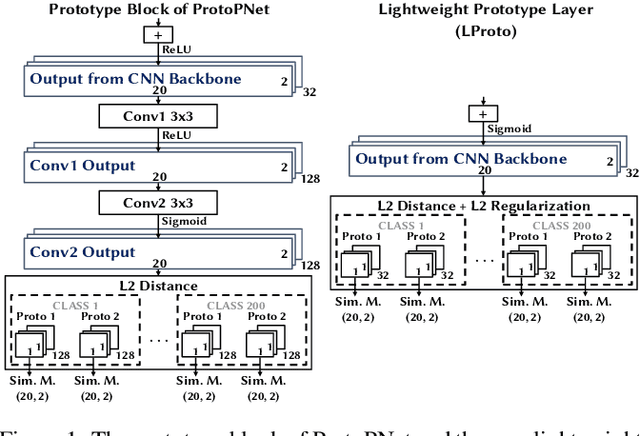


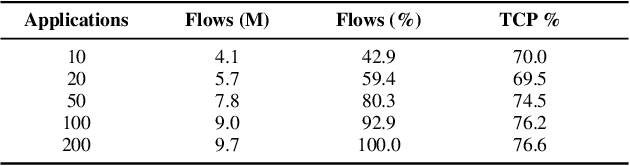
Traffic classification, i.e. the identification of the type of applications flowing in a network, is a strategic task for numerous activities (e.g., intrusion detection, routing). This task faces some critical challenges that current deep learning approaches do not address. The design of current approaches do not take into consideration the fact that networking hardware (e.g., routers) often runs with limited computational resources. Further, they do not meet the need for faithful explainability highlighted by regulatory bodies. Finally, these traffic classifiers are evaluated on small datasets which fail to reflect the diversity of applications in real commercial settings. Therefore, this paper introduces a Lightweight, Efficient and eXplainable-by-design convolutional neural network (LEXNet) for Internet traffic classification, which relies on a new residual block (for lightweight and efficiency purposes) and prototype layer (for explainability). Based on a commercial-grade dataset, our evaluation shows that LEXNet succeeds to maintain the same accuracy as the best performing state-of-the-art neural network, while providing the additional features previously mentioned. Moreover, we demonstrate that LEXNet significantly reduces the model size and inference time compared to the state-of-the-art neural networks with explainability-by-design and post hoc explainability methods. Finally, we illustrate the explainability feature of our approach, which stems from the communication of detected application prototypes to the end-user, and we highlight the faithfulness of LEXNet explanations through a comparison with post hoc methods.