 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Contexts Are Hard Contexts: Lexical Density Limits Effective Context in LLMs
Jun 04, 2026Input length and the position of relevant information are widely cited as the primary causes of degraded LLM long-context performance. Here, we study lexical density -- the rate at which a context introduces distinct information -- as a third, largely overlooked factor that systematically reduces the effective context window of LLMs. We quantify the impact of lexical density on open-weight LLMs (9B-685B) using three "find-the-needle" style benchmarks with identical length (~12k tokens) and controlled needle position, but increasing density of information. We observe a sharp performance collapse in higher-density benchmarks: models that are near-perfect in sparse contexts drop below 60% retrieval score on denser ones. To rule out task-type confounds, we vary and control the density within each benchmark while keeping all other properties unchanged. Reducing density generally restores performance, especially in the high-density regimes where degradation appears. These results show that effective context capacity is a function of lexical density, with direct implications for real-world LLM systems operating on compact, information-rich inputs.
Improving Generalization on Cybersecurity Tasks with Multi-Modal Contrastive Learning
Mar 20, 2026The use of ML in cybersecurity has long been impaired by generalization issues: Models that work well in controlled scenarios fail to maintain performance in production. The root cause often lies in ML algorithms learning superficial patterns (shortcuts) rather than underlying cybersecurity concepts. We investigate contrastive multi-modal learning as a first step towards improving ML performance in cybersecurity tasks. We aim at transferring knowledge from data-rich modalities, such as text, to data-scarce modalities, such as payloads. We set up a case study on threat classification and propose a two-stage multi-modal contrastive learning framework that uses textual vulnerability descriptions to guide payload classification. First, we construct a semantically meaningful embedding space using contrastive learning on descriptions. Then, we align payloads to this space, transferring knowledge from text to payloads. We evaluate the approach on a large-scale private dataset and a synthetic benchmark built from public CVE descriptions and LLM-generated payloads. The methodology appears to reduce shortcut learning over baselines on both benchmarks. We release our synthetic benchmark and source code as open source.
Towards Agentic Honeynet Configuration
Mar 14, 2026Honeypots are deception systems that emulate vulnerable services to collect threat intelligence. While deploying many honeypots increases the opportunity to observe attacker behaviour, in practise network and computational resources limit the number of honeypots that can be exposed. Hence, practitioners must select the assets to deploy, a decision that is typically made statically despite attackers' tactics evolving over time. This work investigates an AI-driven agentic architecture that autonomously manages honeypot exposure in response to ongoing attacks. The proposed agent analyses Intrusion Detection System (IDS) alerts and network state to infer the progression of the attack, identify compromised assets, and predict likely attacker targets. Based on this assessment, the agent dynamically reconfigures the system to maintain attacker engagement while minimizing unnecessary exposure. The approach is evaluated in a simulated environment where attackers execute Proof-of-Concept exploits for known CVEs. Preliminary results indicate that the agent can effectively infer the intent of the attacker and improve the efficiency of exposure under resource constraints
The Sweet Danger of Sugar: Debunking Representation Learning for Encrypted Traffic Classification
Jul 22, 2025Recently we have witnessed the explosion of proposals that, inspired by Language Models like BERT, exploit Representation Learning models to create traffic representations. All of them promise astonishing performance in encrypted traffic classification (up to 98% accuracy). In this paper, with a networking expert mindset, we critically reassess their performance. Through extensive analysis, we demonstrate that the reported successes are heavily influenced by data preparation problems, which allow these models to find easy shortcuts - spurious correlation between features and labels - during fine-tuning that unrealistically boost their performance. When such shortcuts are not present - as in real scenarios - these models perform poorly. We also introduce Pcap-Encoder, an LM-based representation learning model that we specifically design to extract features from protocol headers. Pcap-Encoder appears to be the only model that provides an instrumental representation for traffic classification. Yet, its complexity questions its applicability in practical settings. Our findings reveal flaws in dataset preparation and model training, calling for a better and more conscious test design. We propose a correct evaluation methodology and stress the need for rigorous benchmarking.
AutoPenBench: Benchmarking Generative Agents for Penetration Testing
Oct 04, 2024



Generative AI agents, software systems powered by Large Language Models (LLMs), are emerging as a promising approach to automate cybersecurity tasks. Among the others, penetration testing is a challenging field due to the task complexity and the diverse strategies to simulate cyber-attacks. Despite growing interest and initial studies in automating penetration testing with generative agents, there remains a significant gap in the form of a comprehensive and standard framework for their evaluation and development. This paper introduces AutoPenBench, an open benchmark for evaluating generative agents in automated penetration testing. We present a comprehensive framework that includes 33 tasks, each representing a vulnerable system that the agent has to attack. Tasks are of increasing difficulty levels, including in-vitro and real-world scenarios. We assess the agent performance with generic and specific milestones that allow us to compare results in a standardised manner and understand the limits of the agent under test. We show the benefits of AutoPenBench by testing two agent architectures: a fully autonomous and a semi-autonomous supporting human interaction. We compare their performance and limitations. For example, the fully autonomous agent performs unsatisfactorily achieving a 21% Success Rate (SR) across the benchmark, solving 27% of the simple tasks and only one real-world task. In contrast, the assisted agent demonstrates substantial improvements, with 64% of SR. AutoPenBench allows us also to observe how different LLMs like GPT-4o or OpenAI o1 impact the ability of the agents to complete the tasks. We believe that our benchmark fills the gap with a standard and flexible framework to compare penetration testing agents on a common ground. We hope to extend AutoPenBench along with the research community by making it available under https://github.com/lucagioacchini/auto-pen-bench.
Generic Multi-modal Representation Learning for Network Traffic Analysis
May 04, 2024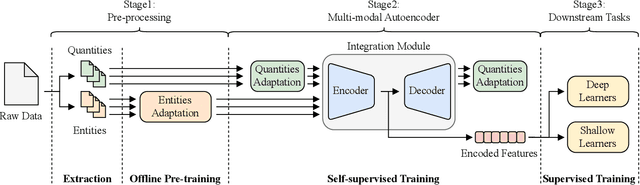
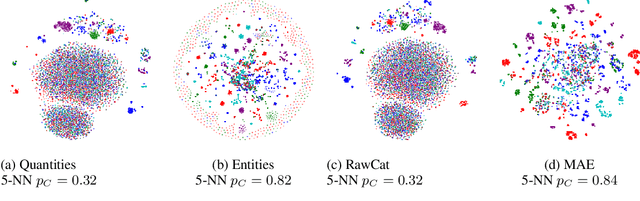
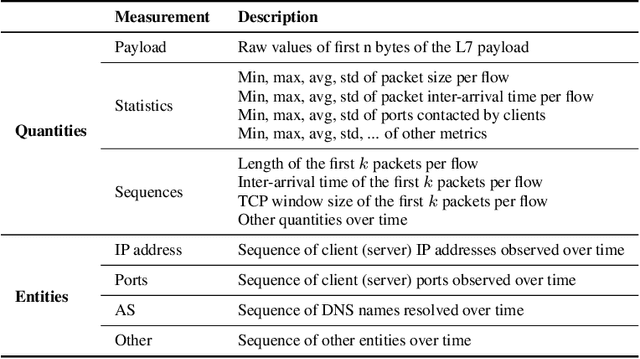
Network traffic analysis is fundamental for network management, troubleshooting, and security. Tasks such as traffic classification, anomaly detection, and novelty discovery are fundamental for extracting operational information from network data and measurements. We witness the shift from deep packet inspection and basic machine learning to Deep Learning (DL) approaches where researchers define and test a custom DL architecture designed for each specific problem. We here advocate the need for a general DL architecture flexible enough to solve different traffic analysis tasks. We test this idea by proposing a DL architecture based on generic data adaptation modules, followed by an integration module that summarises the extracted information into a compact and rich intermediate representation (i.e. embeddings). The result is a flexible Multi-modal Autoencoder (MAE) pipeline that can solve different use cases. We demonstrate the architecture with traffic classification (TC) tasks since they allow us to quantitatively compare results with state-of-the-art solutions. However, we argue that the MAE architecture is generic and can be used to learn representations useful in multiple scenarios. On TC, the MAE performs on par or better than alternatives while avoiding cumbersome feature engineering, thus streamlining the adoption of DL solutions for traffic analysis.
Benchmarking Evolutionary Community Detection Algorithms in Dynamic Networks
Jan 11, 2024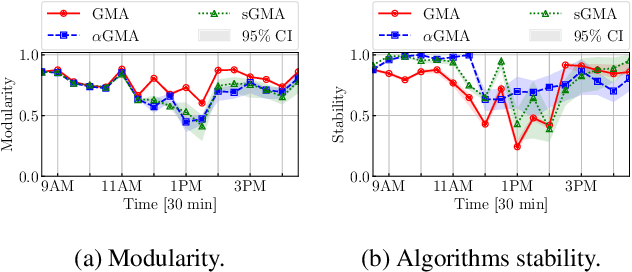

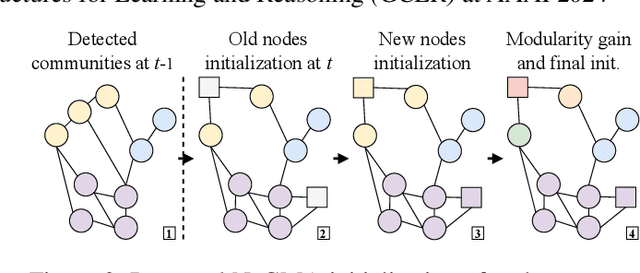

In dynamic complex networks, entities interact and form network communities that evolve over time. Among the many static Community Detection (CD) solutions, the modularity-based Louvain, or Greedy Modularity Algorithm (GMA), is widely employed in real-world applications due to its intuitiveness and scalability. Nevertheless, addressing CD in dynamic graphs remains an open problem, since the evolution of the network connections may poison the identification of communities, which may be evolving at a slower pace. Hence, naively applying GMA to successive network snapshots may lead to temporal inconsistencies in the communities. Two evolutionary adaptations of GMA, sGMA and $\alpha$GMA, have been proposed to tackle this problem. Yet, evaluating the performance of these methods and understanding to which scenarios each one is better suited is challenging because of the lack of a comprehensive set of metrics and a consistent ground truth. To address these challenges, we propose (i) a benchmarking framework for evolutionary CD algorithms in dynamic networks and (ii) a generalised modularity-based approach (NeGMA). Our framework allows us to generate synthetic community-structured graphs and design evolving scenarios with nine basic graph transformations occurring at different rates. We evaluate performance through three metrics we define, i.e. Correctness, Delay, and Stability. Our findings reveal that $\alpha$GMA is well-suited for detecting intermittent transformations, but struggles with abrupt changes; sGMA achieves superior stability, but fails to detect emerging communities; and NeGMA appears a well-balanced solution, excelling in responsiveness and instantaneous transformations detection.
* Accepted at the 4th Workshop on Graphs and more Complex structures for Learning and Reasoning (GCLR) at AAAI 2024
Sound-skwatter (Did You Mean: Sound-squatter?) AI-powered Generator for Phishing Prevention
Oct 10, 2023

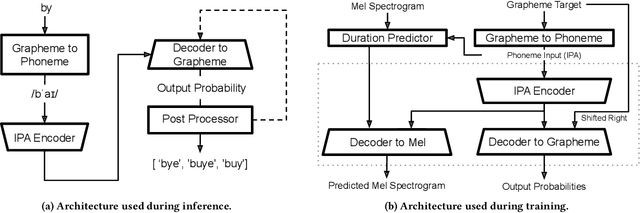
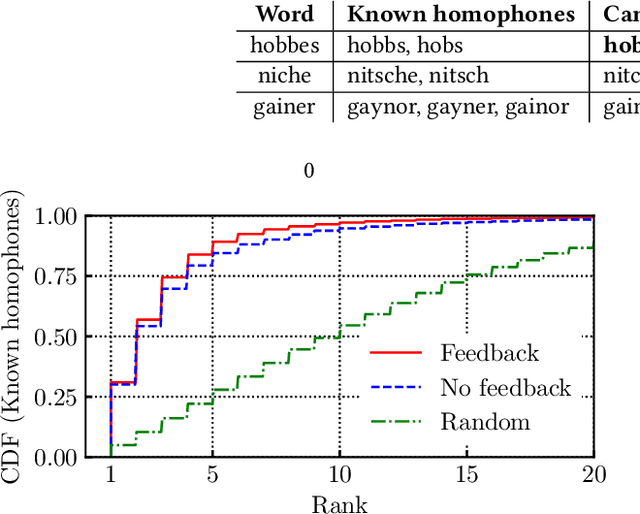
Sound-squatting is a phishing attack that tricks users into malicious resources by exploiting similarities in the pronunciation of words. Proactive defense against sound-squatting candidates is complex, and existing solutions rely on manually curated lists of homophones. We here introduce Sound-skwatter, a multi-language AI-based system that generates sound-squatting candidates for proactive defense. Sound-skwatter relies on an innovative multi-modal combination of Transformers Networks and acoustic models to learn sound similarities. We show that Sound-skwatter can automatically list known homophones and thousands of high-quality candidates. In addition, it covers cross-language sound-squatting, i.e., when the reader and the listener speak different languages, supporting any combination of languages. We apply Sound-skwatter to network-centric phishing via squatted domain names. We find ~ 10% of the generated domains exist in the wild, the vast majority unknown to protection solutions. Next, we show attacks on the PyPI package manager, where ~ 17% of the popular packages have at least one existing candidate. We believe Sound-skwatter is a crucial asset to mitigate the sound-squatting phenomenon proactively on the Internet. To increase its impact, we publish an online demo and release our models and code as open source.
LogPrécis: Unleashing Language Models for Automated Shell Log Analysis
Jul 17, 2023



The collection of security-related logs holds the key to understanding attack behaviors and diagnosing vulnerabilities. Still, their analysis remains a daunting challenge. Recently, Language Models (LMs) have demonstrated unmatched potential in understanding natural and programming languages. The question arises whether and how LMs could be also useful for security experts since their logs contain intrinsically confused and obfuscated information. In this paper, we systematically study how to benefit from the state-of-the-art in LM to automatically analyze text-like Unix shell attack logs. We present a thorough design methodology that leads to LogPr\'ecis. It receives as input raw shell sessions and automatically identifies and assigns the attacker tactic to each portion of the session, i.e., unveiling the sequence of the attacker's goals. We demonstrate LogPr\'ecis capability to support the analysis of two large datasets containing about 400,000 unique Unix shell attacks. LogPr\'ecis reduces them into about 3,000 fingerprints, each grouping sessions with the same sequence of tactics. The abstraction it provides lets the analyst better understand attacks, identify fingerprints, detect novelty, link similar attacks, and track families and mutations. Overall, LogPr\'ecis, released as open source, paves the way for better and more responsive defense against cyberattacks.
Recommendation Systems in Libraries: an Application with Heterogeneous Data Sources
Mar 21, 2023



The Reading&Machine project exploits the support of digitalization to increase the attractiveness of libraries and improve the users' experience. The project implements an application that helps the users in their decision-making process, providing recommendation system (RecSys)-generated lists of books the users might be interested in, and showing them through an interactive Virtual Reality (VR)-based Graphical User Interface (GUI). In this paper, we focus on the design and testing of the recommendation system, employing data about all users' loans over the past 9 years from the network of libraries located in Turin, Italy. In addition, we use data collected by the Anobii online social community of readers, who share their feedback and additional information about books they read. Armed with this heterogeneous data, we build and evaluate Content Based (CB) and Collaborative Filtering (CF) approaches. Our results show that the CF outperforms the CB approach, improving by up to 47\% the relevant recommendations provided to a reader. However, the performance of the CB approach is heavily dependent on the number of books the reader has already read, and it can work even better than CF for users with a large history. Finally, our evaluations highlight that the performances of both approaches are significantly improved if the system integrates and leverages the information from the Anobii dataset, which allows us to include more user readings (for CF) and richer book metadata (for CB).