 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Praise of Stubbornness: The Case for Cognitive-Dissonance-Aware Knowledge Updates in LLMs
Feb 05, 2025Despite remarkable capabilities, large language models (LLMs) struggle to continually update their knowledge without catastrophic forgetting. In contrast, humans effortlessly integrate new information, detect conflicts with existing beliefs, and selectively update their mental models. This paper introduces a cognitive-inspired investigation paradigm to study continual knowledge updating in LLMs. We implement two key components inspired by human cognition: (1) Dissonance and Familiarity Awareness, analyzing model behavior to classify information as novel, familiar, or dissonant; and (2) Targeted Network Updates, which track neural activity to identify frequently used (stubborn) and rarely used (plastic) neurons. Through carefully designed experiments in controlled settings, we uncover a number of empirical findings demonstrating the potential of this approach. First, dissonance detection is feasible using simple activation and gradient features, suggesting potential for cognitive-inspired training. Second, we find that non-dissonant updates largely preserve prior knowledge regardless of targeting strategy, revealing inherent robustness in LLM knowledge integration. Most critically, we discover that dissonant updates prove catastrophically destructive to the model's knowledge base, indiscriminately affecting even information unrelated to the current updates. This suggests fundamental limitations in how neural networks handle contradictions and motivates the need for new approaches to knowledge updating that better mirror human cognitive mechanisms.
Rare Yet Popular: Evidence and Implications from Labeled Datasets for Network Anomaly Detection
Nov 18, 2022Anomaly detection research works generally propose algorithms or end-to-end systems that are designed to automatically discover outliers in a dataset or a stream. While literature abounds concerning algorithms or the definition of metrics for better evaluation, the quality of the ground truth against which they are evaluated is seldom questioned. In this paper, we present a systematic analysis of available public (and additionally our private) ground truth for anomaly detection in the context of network environments, where data is intrinsically temporal, multivariate and, in particular, exhibits spatial properties, which, to the best of our knowledge, we are the first to explore. Our analysis reveals that, while anomalies are, by definition, temporally rare events, their spatial characterization clearly shows some type of anomalies are significantly more popular than others. We find that simple clustering can reduce the need for human labeling by a factor of 2x-10x, that we are first to quantitatively analyze in the wild.
Local Evaluation of Time Series Anomaly Detection Algorithms
Jun 27, 2022
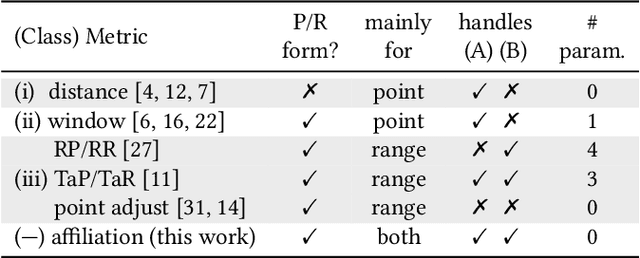
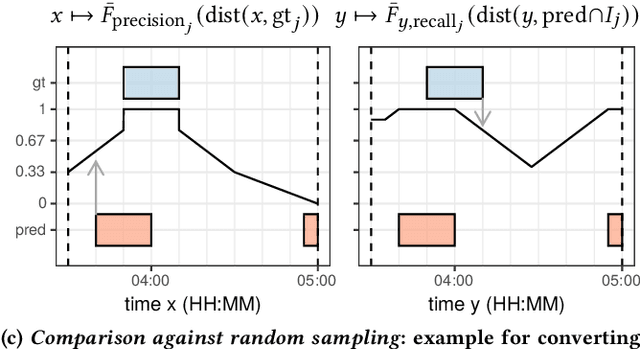
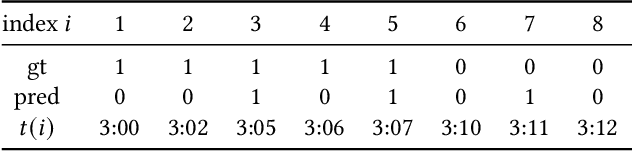
In recent years, specific evaluation metrics for time series anomaly detection algorithms have been developed to handle the limitations of the classical precision and recall. However, such metrics are heuristically built as an aggregate of multiple desirable aspects, introduce parameters and wipe out the interpretability of the output. In this article, we first highlight the limitations of the classical precision/recall, as well as the main issues of the recent event-based metrics -- for instance, we show that an adversary algorithm can reach high precision and recall on almost any dataset under weak assumption. To cope with the above problems, we propose a theoretically grounded, robust, parameter-free and interpretable extension to precision/recall metrics, based on the concept of ``affiliation'' between the ground truth and the prediction sets. Our metrics leverage measures of duration between ground truth and predictions, and have thus an intuitive interpretation. By further comparison against random sampling, we obtain a normalized precision/recall, quantifying how much a given set of results is better than a random baseline prediction. By construction, our approach keeps the evaluation local regarding ground truth events, enabling fine-grained visualization and interpretation of algorithmic results. We compare our proposal against various public time series anomaly detection datasets, algorithms and metrics. We further derive theoretical properties of the affiliation metrics that give explicit expectations about their behavior and ensure robustness against adversary strategies.
Human readable network troubleshooting based on anomaly detection and feature scoring
Aug 26, 2021
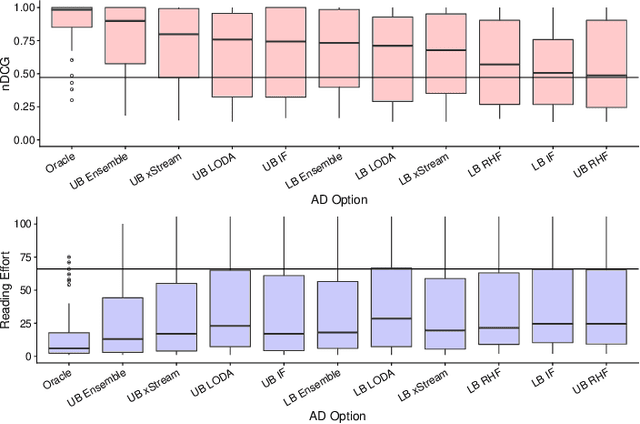
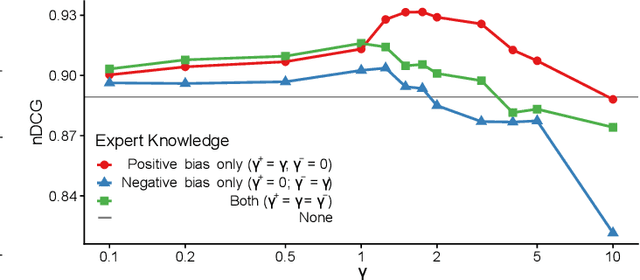
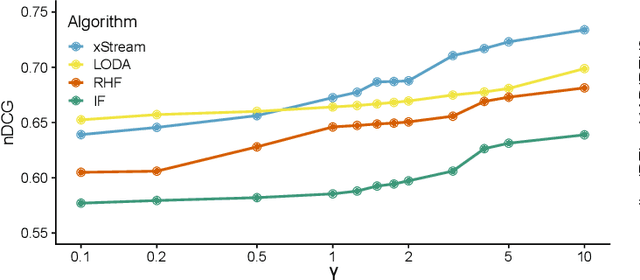
Network troubleshooting is still a heavily human-intensive process. To reduce the time spent by human operators in the diagnosis process, we present a system based on (i) unsupervised learning methods for detecting anomalies in the time domain, (ii) an attention mechanism to rank features in the feature space and finally (iii) an expert knowledge module able to seamlessly incorporate previously collected domain-knowledge. In this paper, we thoroughly evaluate the performance of the full system and of its individual building blocks: particularly, we consider (i) 10 anomaly detection algorithms as well as (ii) 10 attention mechanisms, that comprehensively represent the current state of the art in the respective fields. Leveraging a unique collection of expert-labeled datasets worth several months of real router telemetry data, we perform a thorough performance evaluation contrasting practical results in constrained stream-mode settings, with the results achievable by an ideal oracle in academic settings. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, and (ii) that even a simple statistical approach is able to extract useful information from expert knowledge gained in past cases, significantly improving troubleshooting performance.