 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Yet Popular: Evidence and Implications from Labeled Datasets for Network Anomaly Detection
Nov 18, 2022Anomaly detection research works generally propose algorithms or end-to-end systems that are designed to automatically discover outliers in a dataset or a stream. While literature abounds concerning algorithms or the definition of metrics for better evaluation, the quality of the ground truth against which they are evaluated is seldom questioned. In this paper, we present a systematic analysis of available public (and additionally our private) ground truth for anomaly detection in the context of network environments, where data is intrinsically temporal, multivariate and, in particular, exhibits spatial properties, which, to the best of our knowledge, we are the first to explore. Our analysis reveals that, while anomalies are, by definition, temporally rare events, their spatial characterization clearly shows some type of anomalies are significantly more popular than others. We find that simple clustering can reduce the need for human labeling by a factor of 2x-10x, that we are first to quantitatively analyze in the wild.
Local Evaluation of Time Series Anomaly Detection Algorithms
Jun 27, 2022
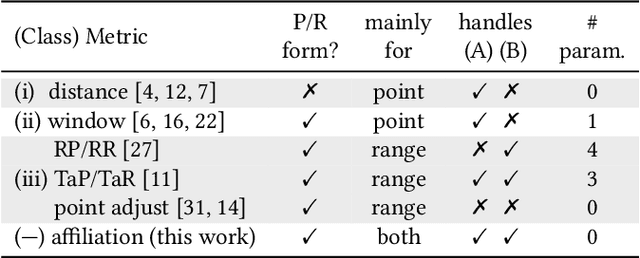
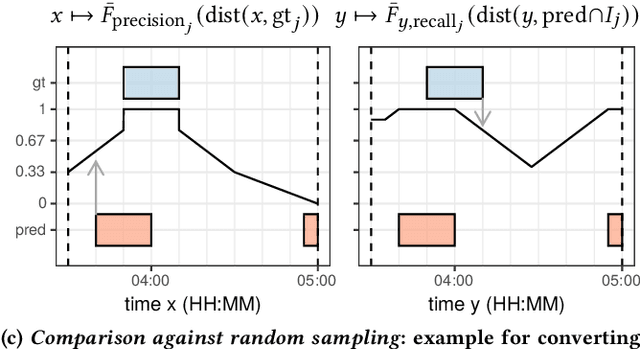
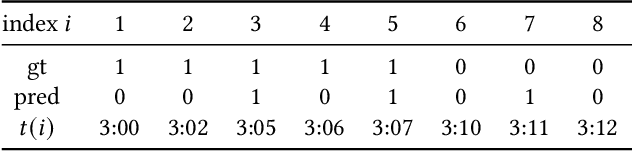
In recent years, specific evaluation metrics for time series anomaly detection algorithms have been developed to handle the limitations of the classical precision and recall. However, such metrics are heuristically built as an aggregate of multiple desirable aspects, introduce parameters and wipe out the interpretability of the output. In this article, we first highlight the limitations of the classical precision/recall, as well as the main issues of the recent event-based metrics -- for instance, we show that an adversary algorithm can reach high precision and recall on almost any dataset under weak assumption. To cope with the above problems, we propose a theoretically grounded, robust, parameter-free and interpretable extension to precision/recall metrics, based on the concept of ``affiliation'' between the ground truth and the prediction sets. Our metrics leverage measures of duration between ground truth and predictions, and have thus an intuitive interpretation. By further comparison against random sampling, we obtain a normalized precision/recall, quantifying how much a given set of results is better than a random baseline prediction. By construction, our approach keeps the evaluation local regarding ground truth events, enabling fine-grained visualization and interpretation of algorithmic results. We compare our proposal against various public time series anomaly detection datasets, algorithms and metrics. We further derive theoretical properties of the affiliation metrics that give explicit expectations about their behavior and ensure robustness against adversary strategies.