 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Did I Do Wrong? Quantifying LLMs' Sensitivity and Consistency to Prompt Engineering
Paper and Code
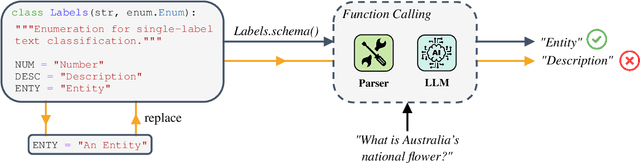
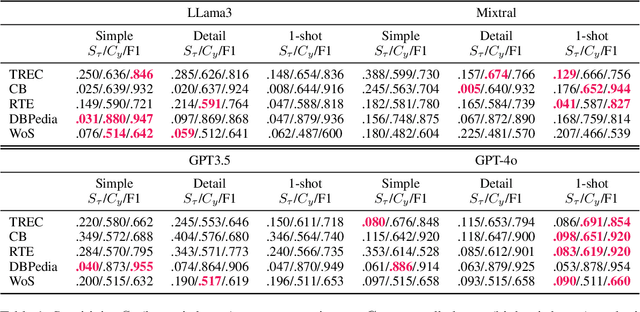
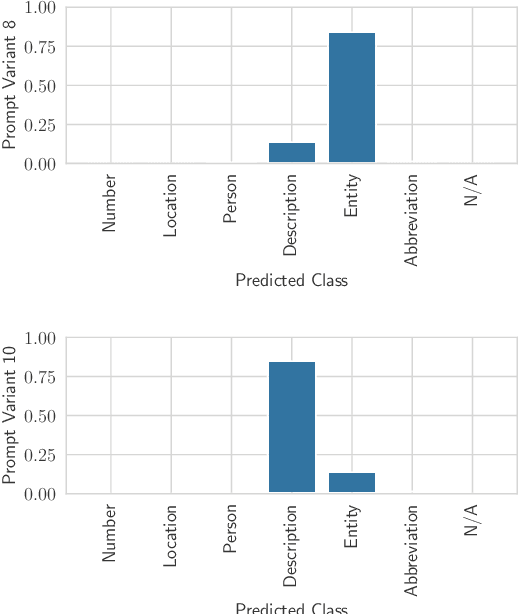
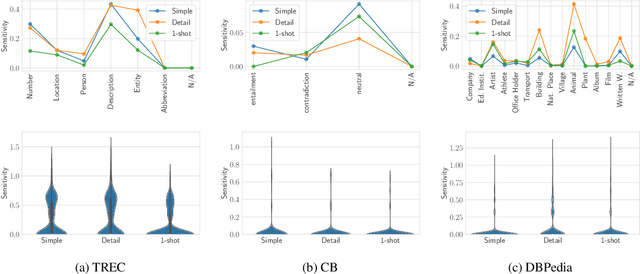
Large Language Models (LLMs) changed the way we design and interact with software systems. Their ability to process and extract information from text has drastically improved productivity in a number of routine tasks. Developers that want to include these models in their software stack, however, face a dreadful challenge: debugging their inconsistent behavior across minor variations of the prompt. We therefore introduce two metrics for classification tasks, namely sensitivity and consistency, which are complementary to task performance. First, sensitivity measures changes of predictions across rephrasings of the prompt, and does not require access to ground truth labels. Instead, consistency measures how predictions vary across rephrasings for elements of the same class. We perform an empirical comparison of these metrics on text classification tasks, using them as guideline for understanding failure modes of the LLM. Our hope is that sensitivity and consistency will be powerful allies in automatic prompt engineering frameworks to obtain LLMs that balance robustness with performance.