 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a fully declarative neuro-symbolic language
May 15, 2024

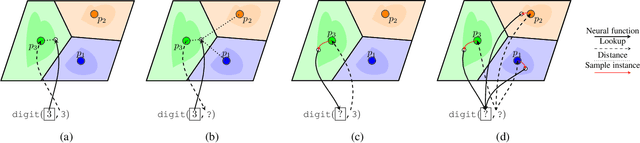
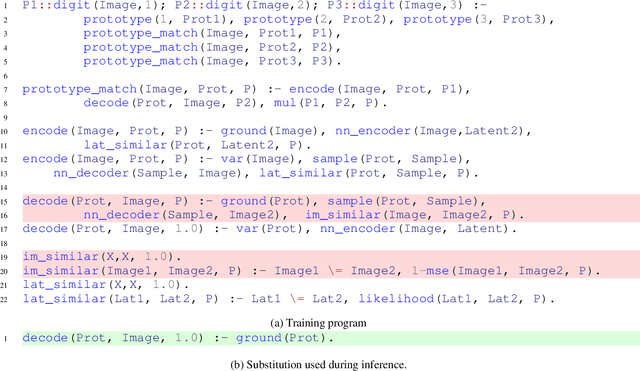
Neuro-symbolic systems (NeSy), which claim to combine the best of both learning and reasoning capabilities of artificial intelligence, are missing a core property of reasoning systems: Declarativeness. The lack of declarativeness is caused by the functional nature of neural predicates inherited from neural networks. We propose and implement a general framework for fully declarative neural predicates, which hence extends to fully declarative NeSy frameworks. We first show that the declarative extension preserves the learning and reasoning capabilities while being able to answer arbitrary queries while only being trained on a single query type.
DeepSaDe: Learning Neural Networks that Guarantee Domain Constraint Satisfaction
Mar 02, 2023As machine learning models, specifically neural networks, are becoming increasingly popular, there are concerns regarding their trustworthiness, specially in safety-critical applications, e.g. actions of an autonomous vehicle must be safe. There are approaches that can train neural networks where such domain requirements are enforced as constraints, but they either cannot guarantee that the constraint will be satisfied by all possible predictions (even on unseen data) or they are limited in the type of constraints that can be enforced. In this paper, we present an approach to train neural networks which can enforce a wide variety of constraints and guarantee that the constraint is satisfied by all possible predictions. The approach builds on earlier work where learning linear models is formulated as a constraint satisfaction problem (CSP). To make this idea applicable to neural networks, two crucial new elements are added: constraint propagation over the network layers, and weight updates based on a mix of gradient descent and CSP solving. Evaluation on various machine learning tasks demonstrates that our approach is flexible enough to enforce a wide variety of domain constraints and is able to guarantee them in neural networks.
SaDe: Learning Models that Provably Satisfy Domain Constraints
Dec 08, 2021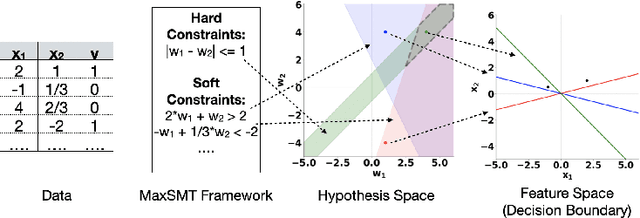

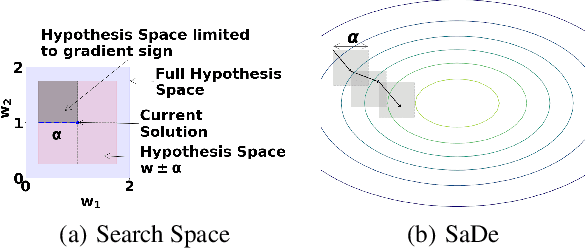
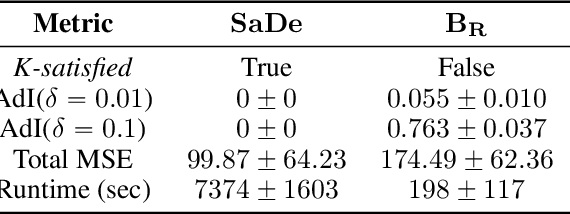
With increasing real world applications of machine learning, models are often required to comply with certain domain based requirements, e.g., safety guarantees in aircraft systems, legal constraints in a loan approval model. A natural way to represent these properties is in the form of constraints. Including such constraints in machine learning is typically done by the means of regularization, which does not guarantee satisfaction of the constraints. In this paper, we present a machine learning approach that can handle a wide variety of constraints, and guarantee that these constraints will be satisfied by the model even on unseen data. We cast machine learning as a maximum satisfiability problem, and solve it using a novel algorithm SaDe which combines constraint satisfaction with gradient descent. We demonstrate on three use cases that this approach learns models that provably satisfy the given constraints.
Feature Interactions in XGBoost
Jul 11, 2020In this paper, we investigate how feature interactions can be identified to be used as constraints in the gradient boosting tree models using XGBoost's implementation. Our results show that accurate identification of these constraints can help improve the performance of baseline XGBoost model significantly. Further, the improvement in the model structure can also lead to better interpretability.
Knowledge Refactoring for Program Induction
Apr 21, 2020


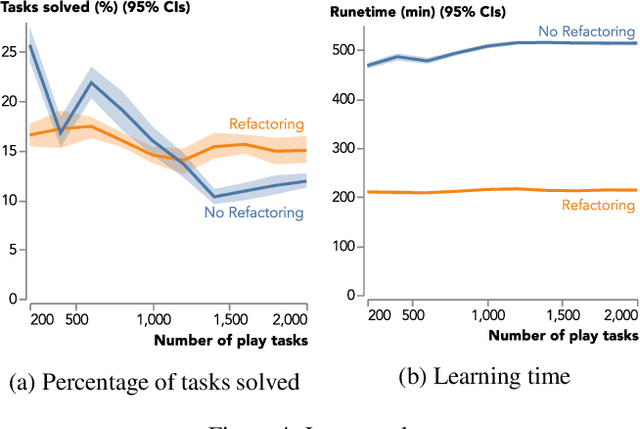
Humans constantly restructure knowledge to use it more efficiently. Our goal is to give a machine learning system similar abilities so that it can learn more efficiently. We introduce the \textit{knowledge refactoring} problem, where the goal is to restructure a learner's knowledge base to reduce its size and to minimise redundancy in it. We focus on inductive logic programming, where the knowledge base is a logic program. We introduce Knorf, a system which solves the refactoring problem using constraint optimisation. We evaluate our approach on two program induction domains: real-world string transformations and building Lego structures. Our experiments show that learning from refactored knowledge can improve predictive accuracies fourfold and reduce learning times by half.
Learning Relational Representations with Auto-encoding Logic Programs
Mar 29, 2019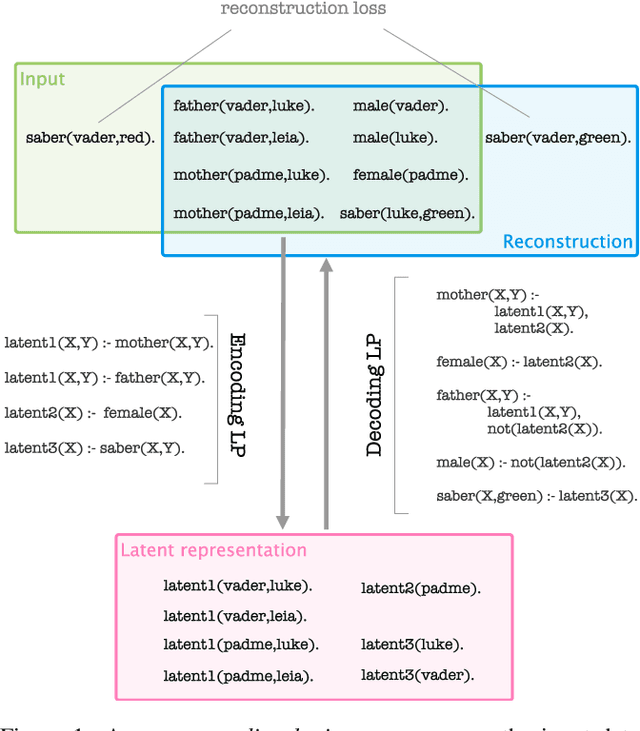


Deep learning methods capable of handling relational data have proliferated over the last years. In contrast to traditional relational learning methods that leverage first-order logic for representing such data, these deep learning methods aim at re-representing symbolic relational data in Euclidean spaces. They offer better scalability, but can only numerically approximate relational structures and are less flexible in terms of reasoning tasks supported. This paper introduces a novel framework for relational representation learning that combines the best of both worlds. This framework, inspired by the auto-encoding principle, uses first-order logic as a data representation language, and the mapping between the original and latent representation is done by means of logic programs instead of neural networks. We show how learning can be cast as a constraint optimisation problem for which existing solvers can be used. The use of logic as a representation language makes the proposed framework more accurate (as the representation is exact, rather than approximate), more flexible, and more interpretable than deep learning methods. We experimentally show that these latent representations are indeed beneficial in relational learning tasks.
On embeddings as an alternative paradigm for relational learning
Jul 02, 2018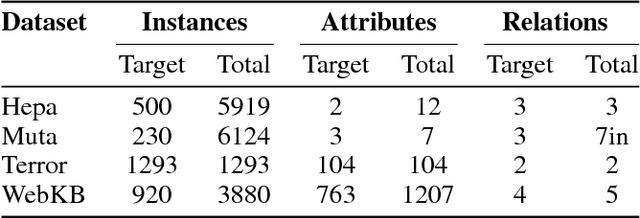
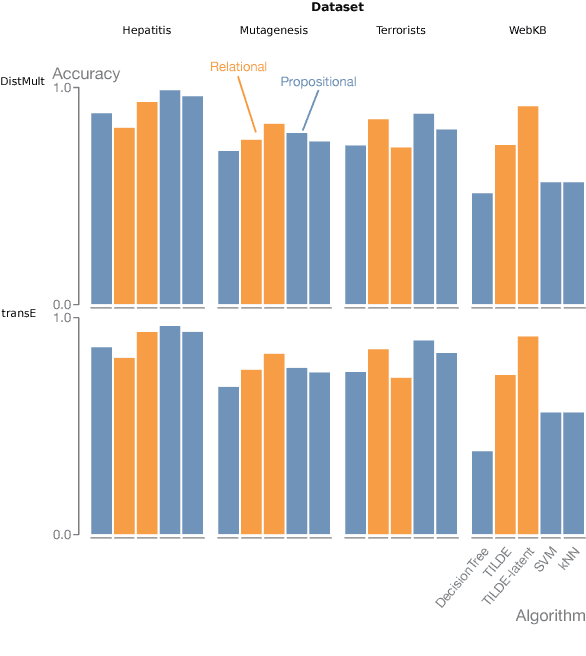
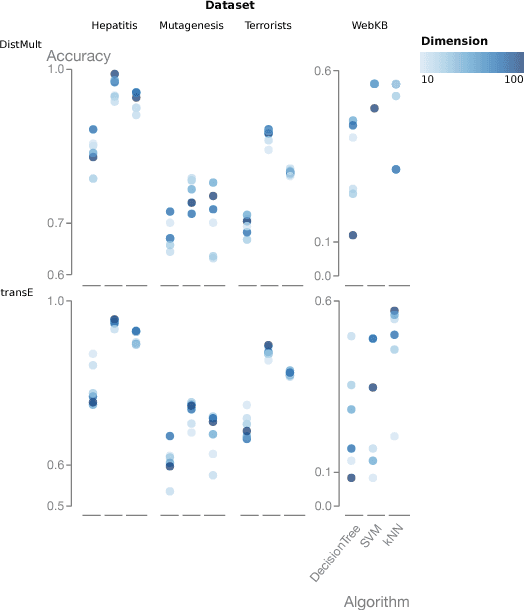

Many real-world domains can be expressed as graphs and, more generally, as multi-relational knowledge graphs. Though reasoning and learning with knowledge graphs has traditionally been addressed by symbolic approaches, recent methods in (deep) representation learning has shown promising results for specialized tasks such as knowledge base completion. These approaches abandon the traditional symbolic paradigm by replacing symbols with vectors in Euclidean space. With few exceptions, symbolic and distributional approaches are explored in different communities and little is known about their respective strengths and weaknesses. In this work, we compare representation learning and relational learning on various relational classification and clustering tasks and analyse the complexity of the rules used implicitly by these approaches. Preliminary results reveal possible indicators that could help in choosing one approach over the other for particular knowledge graphs.
COBRAS-TS: A new approach to Semi-Supervised Clustering of Time Series
May 02, 2018

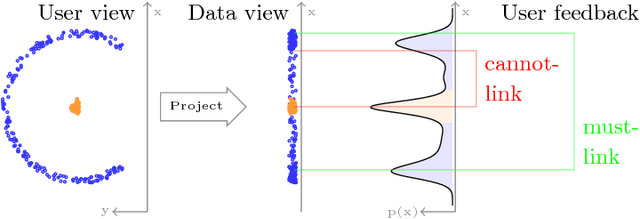
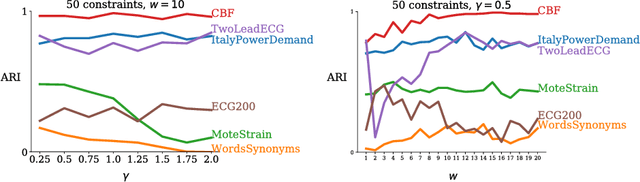
Clustering is ubiquitous in data analysis, including analysis of time series. It is inherently subjective: different users may prefer different clusterings for a particular dataset. Semi-supervised clustering addresses this by allowing the user to provide examples of instances that should (not) be in the same cluster. This paper studies semi-supervised clustering in the context of time series. We show that COBRAS, a state-of-the-art semi-supervised clustering method, can be adapted to this setting. We refer to this approach as COBRAS-TS. An extensive experimental evaluation supports the following claims: (1) COBRAS-TS far outperforms the current state of the art in semi-supervised clustering for time series, and thus presents a new baseline for the field; (2) COBRAS-TS can identify clusters with separated components; (3) COBRAS-TS can identify clusters that are characterized by small local patterns; (4) a small amount of semi-supervision can greatly improve clustering quality for time series; (5) the choice of the clustering algorithm matters (contrary to earlier claims in the literature).
COBRA: A Fast and Simple Method for Active Clustering with Pairwise Constraints
Jan 30, 2018



Clustering is inherently ill-posed: there often exist multiple valid clusterings of a single dataset, and without any additional information a clustering system has no way of knowing which clustering it should produce. This motivates the use of constraints in clustering, as they allow users to communicate their interests to the clustering system. Active constraint-based clustering algorithms select the most useful constraints to query, aiming to produce a good clustering using as few constraints as possible. We propose COBRA, an active method that first over-clusters the data by running K-means with a $K$ that is intended to be too large, and subsequently merges the resulting small clusters into larger ones based on pairwise constraints. In its merging step, COBRA is able to keep the number of pairwise queries low by maximally exploiting constraint transitivity and entailment. We experimentally show that COBRA outperforms the state of the art in terms of clustering quality and runtime, without requiring the number of clusters in advance.
Clustering-Based Relational Unsupervised Representation Learning with an Explicit Distributed Representation
Mar 08, 2017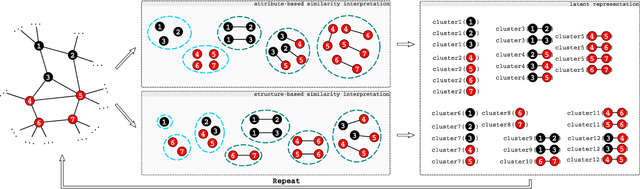
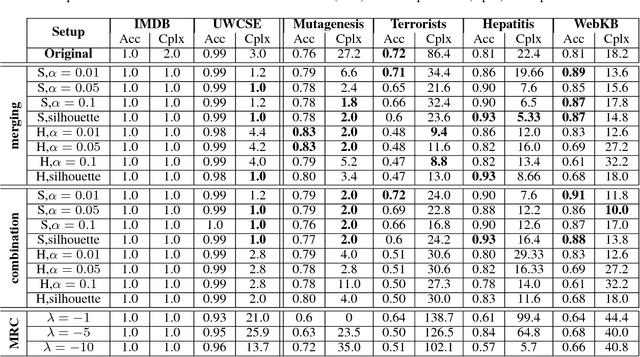

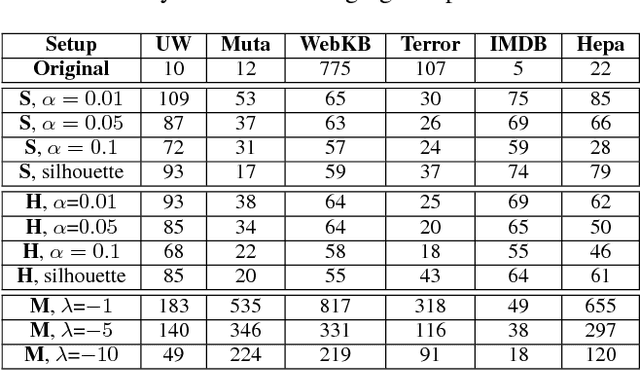
The goal of unsupervised representation learning is to extract a new representation of data, such that solving many different tasks becomes easier. Existing methods typically focus on vectorized data and offer little support for relational data, which additionally describe relationships among instances. In this work we introduce an approach for relational unsupervised representation learning. Viewing a relational dataset as a hypergraph, new features are obtained by clustering vertices and hyperedges. To find a representation suited for many relational learning tasks, a wide range of similarities between relational objects is considered, e.g. feature and structural similarities. We experimentally evaluate the proposed approach and show that models learned on such latent representations perform better, have lower complexity, and outperform the existing approaches on classification tasks.