 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Elicitation for Step-Wise Explanations in Logic Puzzles
Nov 13, 2025Step-wise explanations can explain logic puzzles and other satisfaction problems by showing how to derive decisions step by step. Each step consists of a set of constraints that derive an assignment to one or more decision variables. However, many candidate explanation steps exist, with different sets of constraints and different decisions they derive. To identify the most comprehensible one, a user-defined objective function is required to quantify the quality of each step. However, defining a good objective function is challenging. Here, interactive preference elicitation methods from the wider machine learning community can offer a way to learn user preferences from pairwise comparisons. We investigate the feasibility of this approach for step-wise explanations and address several limitations that distinguish it from elicitation for standard combinatorial problems. First, because the explanation quality is measured using multiple sub-objectives that can vary a lot in scale, we propose two dynamic normalization techniques to rescale these features and stabilize the learning process. We also observed that many generated comparisons involve similar explanations. For this reason, we introduce MACHOP (Multi-Armed CHOice Perceptron), a novel query generation strategy that integrates non-domination constraints with upper confidence bound-based diversification. We evaluate the elicitation techniques on Sudokus and Logic-Grid puzzles using artificial users, and validate them with a real-user evaluation. In both settings, MACHOP consistently produces higher-quality explanations than the standard approach.
Using Certifying Constraint Solvers for Generating Step-wise Explanations
Nov 13, 2025In the field of Explainable Constraint Solving, it is common to explain to a user why a problem is unsatisfiable. A recently proposed method for this is to compute a sequence of explanation steps. Such a step-wise explanation shows individual reasoning steps involving constraints from the original specification, that in the end explain a conflict. However, computing a step-wise explanation is computationally expensive, limiting the scope of problems for which it can be used. We investigate how we can use proofs generated by a constraint solver as a starting point for computing step-wise explanations, instead of computing them step-by-step. More specifically, we define a framework of abstract proofs, in which both proofs and step-wise explanations can be represented. We then propose several methods for converting a proof to a step-wise explanation sequence, with special attention to trimming and simplification techniques to keep the sequence and its individual steps small. Our results show our method significantly speeds up the generation of step-wise explanation sequences, while the resulting step-wise explanation has a quality similar to the current state-of-the-art.
Feasibility-Aware Decision-Focused Learning for Predicting Parameters in the Constraints
Oct 06, 2025When some parameters of a constrained optimization problem (COP) are uncertain, this gives rise to a predict-then-optimize (PtO) problem, comprising two stages -- the prediction of the unknown parameters from contextual information and the subsequent optimization using those predicted parameters. Decision-focused learning (DFL) implements the first stage by training a machine learning (ML) model to optimize the quality of the decisions made using the predicted parameters. When parameters in the constraints of a COP are predicted, the predicted parameters can lead to infeasible solutions. Therefore, it is important to simultaneously manage both feasibility and decision quality. We develop a DFL framework for predicting constraint parameters in a generic COP. While prior works typically assume that the underlying optimization problem is a linear program (LP) or integer linear program (ILP), our approach makes no such assumption. We derive two novel loss functions based on maximum likelihood estimation (MLE): the first one penalizes infeasibility (by penalizing when the predicted parameters lead to infeasible solutions), and the second one penalizes suboptimal decisions (by penalizing when the true optimal solution is infeasible under the predicted parameters). We introduce a single tunable parameter to form a weighted average of the two losses, allowing decision-makers to balance suboptimality and feasibility. We experimentally demonstrate that adjusting this parameter provides a decision-maker the control over the trade-off between the two. Moreover, across several COP instances, we find that for a single value of the tunable parameter, our method matches the performance of the existing baselines on suboptimality and feasibility.
CP-Bench: Evaluating Large Language Models for Constraint Modelling
Jun 06, 2025



Combinatorial problems are present in a wide range of industries. Constraint Programming (CP) is a well-suited problem-solving paradigm, but its core process, namely constraint modelling, is a bottleneck for wider adoption. Aiming to alleviate this bottleneck, recent studies have explored using Large Language Models (LLMs) as modelling assistants, transforming combinatorial problem descriptions to executable constraint models, similar to coding assistants. However, the existing evaluation datasets for constraint modelling are often limited to small, homogeneous, or domain-specific instances, which do not capture the diversity of real-world scenarios. This work addresses this gap by introducing CP-Bench, a novel benchmark dataset that includes a diverse set of well-known combinatorial problem classes sourced from the CP community, structured explicitly for evaluating LLM-driven CP modelling. With this dataset, and given the variety of constraint modelling frameworks, we compare and evaluate the modelling capabilities of LLMs for three distinct constraint modelling systems, which vary in abstraction level and underlying syntax: the high-level MiniZinc language and Python-based CPMpy library, and the lower-level Python interface of the OR-Tools CP-SAT solver. In order to enhance the ability of LLMs to produce valid constraint models, we systematically evaluate the use of prompt-based and inference-time compute methods adapted from existing LLM-based code generation research. Our results underscore the modelling convenience provided by Python-based frameworks, as well as the effectiveness of documentation-rich system prompts, which, augmented with repeated sampling and self-verification, achieve further improvements, reaching up to 70\% accuracy on this new, highly challenging benchmark.
Solver-Free Decision-Focused Learning for Linear Optimization Problems
May 28, 2025



Mathematical optimization is a fundamental tool for decision-making in a wide range of applications. However, in many real-world scenarios, the parameters of the optimization problem are not known a priori and must be predicted from contextual features. This gives rise to predict-then-optimize problems, where a machine learning model predicts problem parameters that are then used to make decisions via optimization. A growing body of work on decision-focused learning (DFL) addresses this setting by training models specifically to produce predictions that maximize downstream decision quality, rather than accuracy. While effective, DFL is computationally expensive, because it requires solving the optimization problem with the predicted parameters at each loss evaluation. In this work, we address this computational bottleneck for linear optimization problems, a common class of problems in both DFL literature and real-world applications. We propose a solver-free training method that exploits the geometric structure of linear optimization to enable efficient training with minimal degradation in solution quality. Our method is based on the insight that a solution is optimal if and only if it achieves an objective value that is at least as good as that of its adjacent vertices on the feasible polytope. Building on this, our method compares the estimated quality of the ground-truth optimal solution with that of its precomputed adjacent vertices, and uses this as loss function. Experiments demonstrate that our method significantly reduces computational cost while maintaining high decision quality.
Preference Elicitation for Multi-objective Combinatorial Optimization with Active Learning and Maximum Likelihood Estimation
Mar 14, 2025



Real-life combinatorial optimization problems often involve several conflicting objectives, such as price, product quality and sustainability. A computationally-efficient way to tackle multiple objectives is to aggregate them into a single-objective function, such as a linear combination. However, defining the weights of the linear combination upfront is hard; alternatively, the use of interactive learning methods that ask users to compare candidate solutions is highly promising. The key challenges are to generate candidates quickly, to learn an objective function that leads to high-quality solutions and to do so with few user interactions. We build upon the Constructive Preference Elicitation framework and show how each of the three properties can be improved: to increase the interaction speed we investigate using pools of (relaxed) solutions, to improve the learning we adopt Maximum Likelihood Estimation of a Bradley-Terry preference model; and to reduce the number of user interactions, we select the pair of candidates to compare with an ensemble-based acquisition function inspired from Active Learning. Our careful experimentation demonstrates each of these improvements: on a PC configuration task and a realistic multi-instance routing problem, our method selects queries faster, needs fewer queries and synthesizes higher-quality combinatorial solutions than previous CPE methods.
Generalizing Constraint Models in Constraint Acquisition
Dec 19, 2024



Constraint Acquisition (CA) aims to widen the use of constraint programming by assisting users in the modeling process. However, most CA methods suffer from a significant drawback: they learn a single set of individual constraints for a specific problem instance, but cannot generalize these constraints to the parameterized constraint specifications of the problem. In this paper, we address this limitation by proposing GenCon, a novel approach to learn parameterized constraint models capable of modeling varying instances of the same problem. To achieve this generalization, we make use of statistical learning techniques at the level of individual constraints. Specifically, we propose to train a classifier to predict, for any possible constraint and parameterization, whether the constraint belongs to the problem. We then show how, for some classes of classifiers, we can extract decision rules to construct interpretable constraint specifications. This enables the generation of ground constraints for any parameter instantiation. Additionally, we present a generate-and-test approach that can be used with any classifier, to generate the ground constraints on the fly. Our empirical results demonstrate that our approach achieves high accuracy and is robust to noise in the input instances.
Exploiting Symmetries in MUS Computation (Extended version)
Dec 18, 2024

In eXplainable Constraint Solving (XCS), it is common to extract a Minimal Unsatisfiable Subset (MUS) from a set of unsatisfiable constraints. This helps explain to a user why a constraint specification does not admit a solution. Finding MUSes can be computationally expensive for highly symmetric problems, as many combinations of constraints need to be considered. In the traditional context of solving satisfaction problems, symmetry has been well studied, and effective ways to detect and exploit symmetries during the search exist. However, in the setting of finding MUSes of unsatisfiable constraint programs, symmetries are understudied. In this paper, we take inspiration from existing symmetry-handling techniques and adapt well-known MUS-computation methods to exploit symmetries in the specification, speeding-up overall computation time. Our results display a significant reduction of runtime for our adapted algorithms compared to the baseline on symmetric problems.
Trustworthy and Explainable Decision-Making for Workforce allocation
Dec 13, 2024



In industrial contexts, effective workforce allocation is crucial for operational efficiency. This paper presents an ongoing project focused on developing a decision-making tool designed for workforce allocation, emphasising the explainability to enhance its trustworthiness. Our objective is to create a system that not only optimises the allocation of teams to scheduled tasks but also provides clear, understandable explanations for its decisions, particularly in cases where the problem is infeasible. By incorporating human-in-the-loop mechanisms, the tool aims to enhance user trust and facilitate interactive conflict resolution. We implemented our approach on a prototype tool/digital demonstrator intended to be evaluated on a real industrial scenario both in terms of performance and user acceptability.
Decision-Focused Learning to Predict Action Costs for Planning
Aug 13, 2024

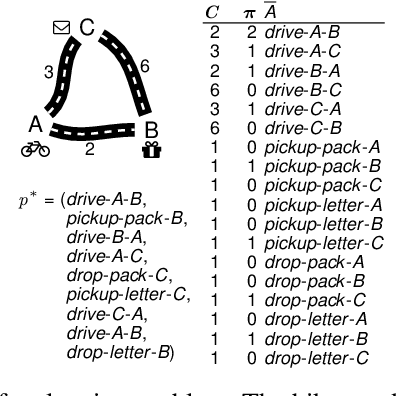

In many automated planning applications, action costs can be hard to specify. An example is the time needed to travel through a certain road segment, which depends on many factors, such as the current weather conditions. A natural way to address this issue is to learn to predict these parameters based on input features (e.g., weather forecasts) and use the predicted action costs in automated planning afterward. Decision-Focused Learning (DFL) has been successful in learning to predict the parameters of combinatorial optimization problems in a way that optimizes solution quality rather than prediction quality. This approach yields better results than treating prediction and optimization as separate tasks. In this paper, we investigate for the first time the challenges of implementing DFL for automated planning in order to learn to predict the action costs. There are two main challenges to overcome: (1) planning systems are called during gradient descent learning, to solve planning problems with negative action costs, which are not supported in planning. We propose novel methods for gradient computation to avoid this issue. (2) DFL requires repeated planner calls during training, which can limit the scalability of the method. We experiment with different methods approximating the optimal plan as well as an easy-to-implement caching mechanism to speed up the learning process. As the first work that addresses DFL for automated planning, we demonstrate that the proposed gradient computation consistently yields significantly better plans than predictions aimed at minimizing prediction error; and that caching can temper the computation requirements.