 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy and Explainable Decision-Making for Workforce allocation
Dec 13, 2024



In industrial contexts, effective workforce allocation is crucial for operational efficiency. This paper presents an ongoing project focused on developing a decision-making tool designed for workforce allocation, emphasising the explainability to enhance its trustworthiness. Our objective is to create a system that not only optimises the allocation of teams to scheduled tasks but also provides clear, understandable explanations for its decisions, particularly in cases where the problem is infeasible. By incorporating human-in-the-loop mechanisms, the tool aims to enhance user trust and facilitate interactive conflict resolution. We implemented our approach on a prototype tool/digital demonstrator intended to be evaluated on a real industrial scenario both in terms of performance and user acceptability.
Modelling Early User-Game Interactions for Joint Estimation of Survival Time and Churn Probability
May 31, 2019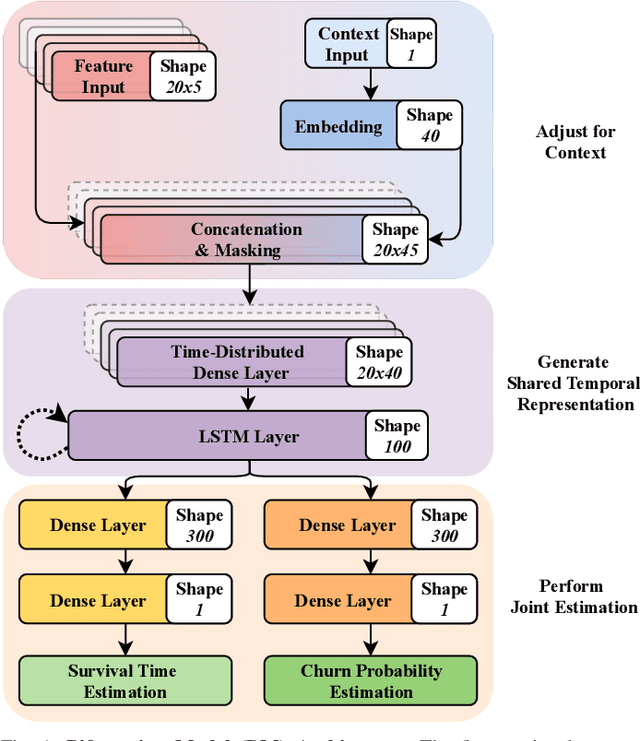
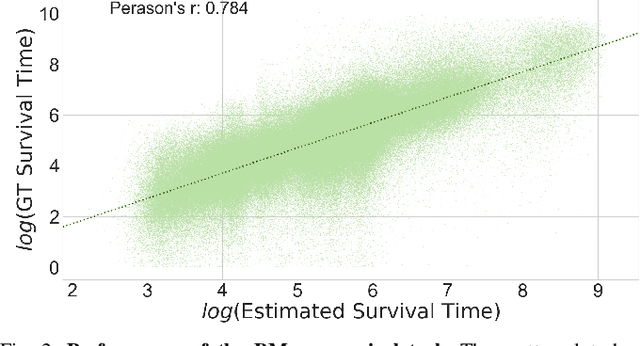
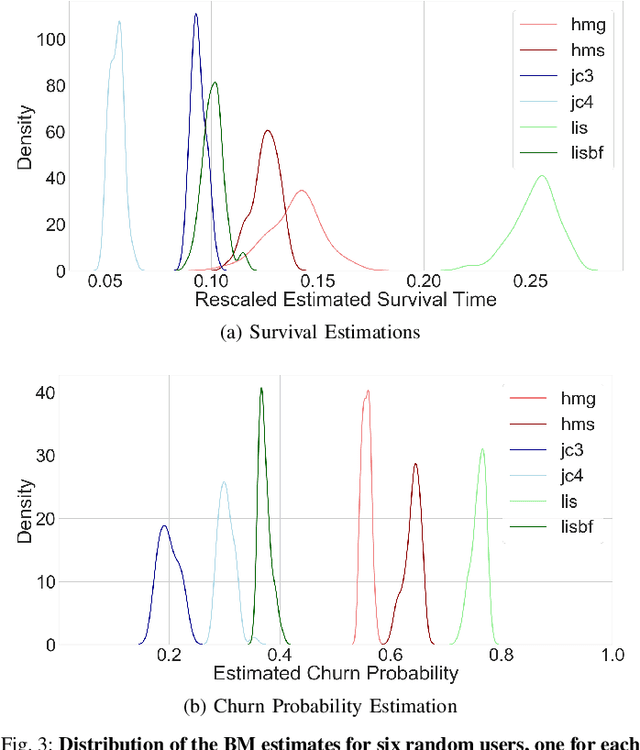

Data-driven approaches which aim to identify and predict player engagement are becoming increasingly popular in games industry contexts. This is due to the growing practice of tracking and storing large volumes of in-game telemetries coupled with a desire to tailor the gaming experience to the end-user's needs. These approaches are particularly useful not just for companies adopting Game-as-a-Service (GaaS) models (e.g. for re-engagement strategies) but also for those working under persistent content-delivery regimes (e.g. for better audience targeting). A major challenge for the latter is to build engagement models of the user which are data-efficient, holistic and can generalize across multiple game titles and genres with minimal adjustments. This work leverages a theoretical framework rooted in engagement and behavioural science research for building a model able to estimate engagement-related behaviours employing only a minimal set of game-agnostic metrics. Through a series of experiments we show how, by modelling early user-game interactions, this approach can make joint estimates of long-term survival time and churn probability across several single-player games in a range of genres. The model proposed is very suitable for industry applications since it relies on a minimal set of metrics and observations, scales well with the number of users and is explicitly designed to work across a diverse range of titles.
Locally Weighted Naive Bayes
Oct 19, 2012
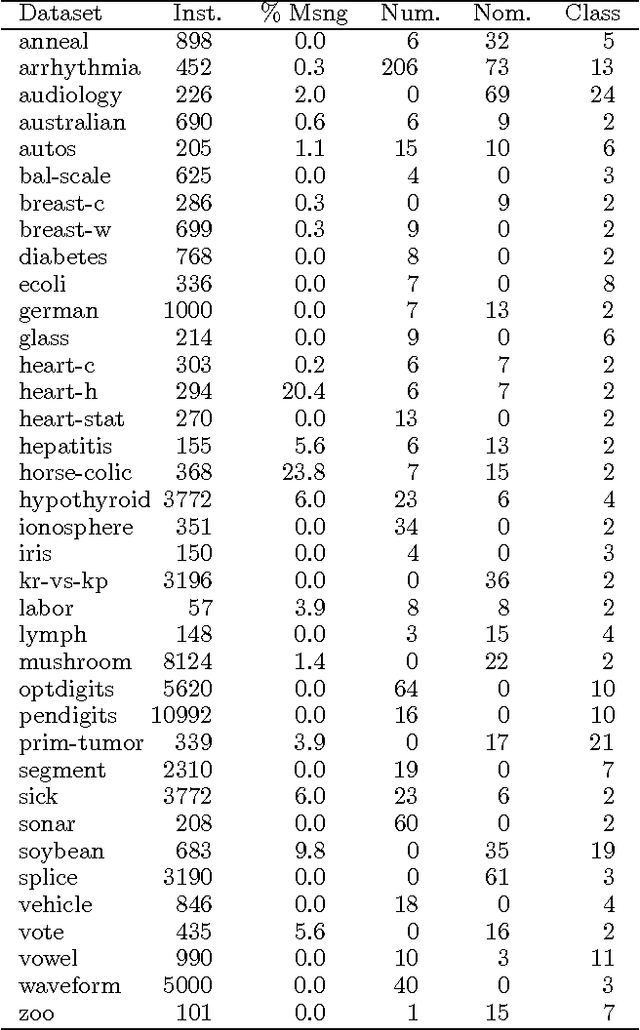

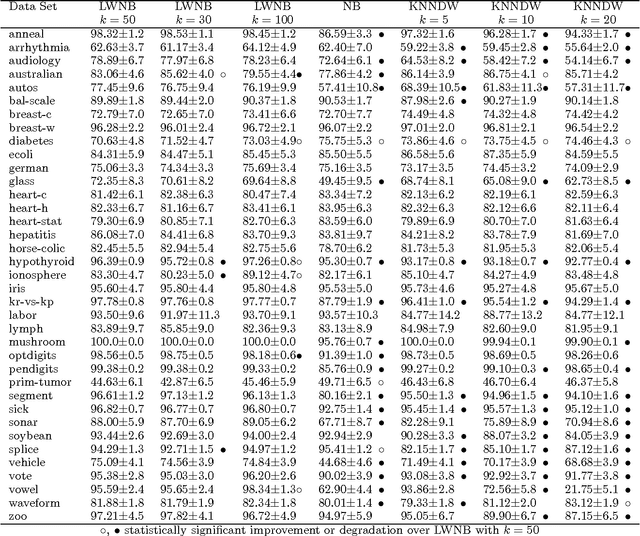
Despite its simplicity, the naive Bayes classifier has surprised machine learning researchers by exhibiting good performance on a variety of learning problems. Encouraged by these results, researchers have looked to overcome naive Bayes primary weakness - attribute independence - and improve the performance of the algorithm. This paper presents a locally weighted version of naive Bayes that relaxes the independence assumption by learning local models at prediction time. Experimental results show that locally weighted naive Bayes rarely degrades accuracy compared to standard naive Bayes and, in many cases, improves accuracy dramatically. The main advantage of this method compared to other techniques for enhancing naive Bayes is its conceptual and computational simplicity.