 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-Bench: Evaluating Large Language Models for Constraint Modelling
Jun 06, 2025



Combinatorial problems are present in a wide range of industries. Constraint Programming (CP) is a well-suited problem-solving paradigm, but its core process, namely constraint modelling, is a bottleneck for wider adoption. Aiming to alleviate this bottleneck, recent studies have explored using Large Language Models (LLMs) as modelling assistants, transforming combinatorial problem descriptions to executable constraint models, similar to coding assistants. However, the existing evaluation datasets for constraint modelling are often limited to small, homogeneous, or domain-specific instances, which do not capture the diversity of real-world scenarios. This work addresses this gap by introducing CP-Bench, a novel benchmark dataset that includes a diverse set of well-known combinatorial problem classes sourced from the CP community, structured explicitly for evaluating LLM-driven CP modelling. With this dataset, and given the variety of constraint modelling frameworks, we compare and evaluate the modelling capabilities of LLMs for three distinct constraint modelling systems, which vary in abstraction level and underlying syntax: the high-level MiniZinc language and Python-based CPMpy library, and the lower-level Python interface of the OR-Tools CP-SAT solver. In order to enhance the ability of LLMs to produce valid constraint models, we systematically evaluate the use of prompt-based and inference-time compute methods adapted from existing LLM-based code generation research. Our results underscore the modelling convenience provided by Python-based frameworks, as well as the effectiveness of documentation-rich system prompts, which, augmented with repeated sampling and self-verification, achieve further improvements, reaching up to 70\% accuracy on this new, highly challenging benchmark.
Solver-Free Decision-Focused Learning for Linear Optimization Problems
May 28, 2025



Mathematical optimization is a fundamental tool for decision-making in a wide range of applications. However, in many real-world scenarios, the parameters of the optimization problem are not known a priori and must be predicted from contextual features. This gives rise to predict-then-optimize problems, where a machine learning model predicts problem parameters that are then used to make decisions via optimization. A growing body of work on decision-focused learning (DFL) addresses this setting by training models specifically to produce predictions that maximize downstream decision quality, rather than accuracy. While effective, DFL is computationally expensive, because it requires solving the optimization problem with the predicted parameters at each loss evaluation. In this work, we address this computational bottleneck for linear optimization problems, a common class of problems in both DFL literature and real-world applications. We propose a solver-free training method that exploits the geometric structure of linear optimization to enable efficient training with minimal degradation in solution quality. Our method is based on the insight that a solution is optimal if and only if it achieves an objective value that is at least as good as that of its adjacent vertices on the feasible polytope. Building on this, our method compares the estimated quality of the ground-truth optimal solution with that of its precomputed adjacent vertices, and uses this as loss function. Experiments demonstrate that our method significantly reduces computational cost while maintaining high decision quality.
Generalizing Constraint Models in Constraint Acquisition
Dec 19, 2024



Constraint Acquisition (CA) aims to widen the use of constraint programming by assisting users in the modeling process. However, most CA methods suffer from a significant drawback: they learn a single set of individual constraints for a specific problem instance, but cannot generalize these constraints to the parameterized constraint specifications of the problem. In this paper, we address this limitation by proposing GenCon, a novel approach to learn parameterized constraint models capable of modeling varying instances of the same problem. To achieve this generalization, we make use of statistical learning techniques at the level of individual constraints. Specifically, we propose to train a classifier to predict, for any possible constraint and parameterization, whether the constraint belongs to the problem. We then show how, for some classes of classifiers, we can extract decision rules to construct interpretable constraint specifications. This enables the generation of ground constraints for any parameter instantiation. Additionally, we present a generate-and-test approach that can be used with any classifier, to generate the ground constraints on the fly. Our empirical results demonstrate that our approach achieves high accuracy and is robust to noise in the input instances.
Trustworthy and Explainable Decision-Making for Workforce allocation
Dec 13, 2024



In industrial contexts, effective workforce allocation is crucial for operational efficiency. This paper presents an ongoing project focused on developing a decision-making tool designed for workforce allocation, emphasising the explainability to enhance its trustworthiness. Our objective is to create a system that not only optimises the allocation of teams to scheduled tasks but also provides clear, understandable explanations for its decisions, particularly in cases where the problem is infeasible. By incorporating human-in-the-loop mechanisms, the tool aims to enhance user trust and facilitate interactive conflict resolution. We implemented our approach on a prototype tool/digital demonstrator intended to be evaluated on a real industrial scenario both in terms of performance and user acceptability.
Learning to Learn in Interactive Constraint Acquisition
Dec 17, 2023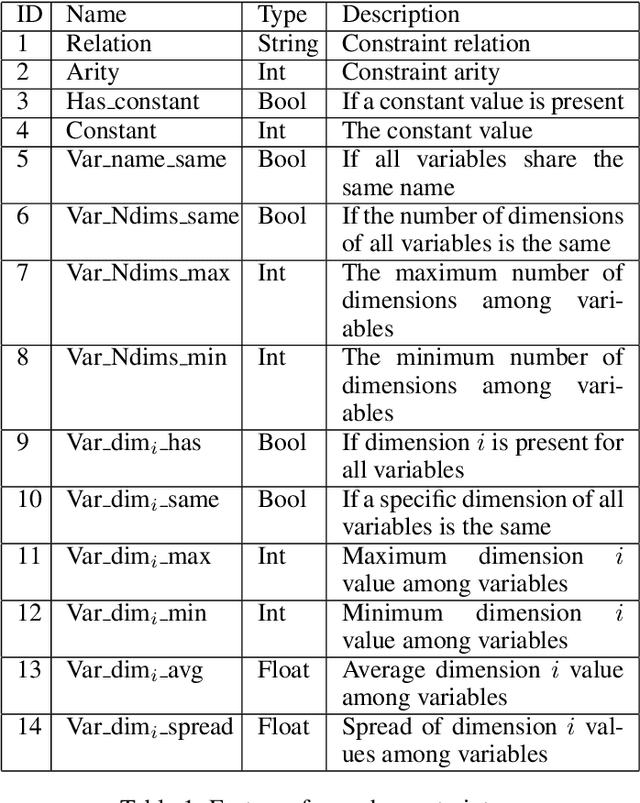
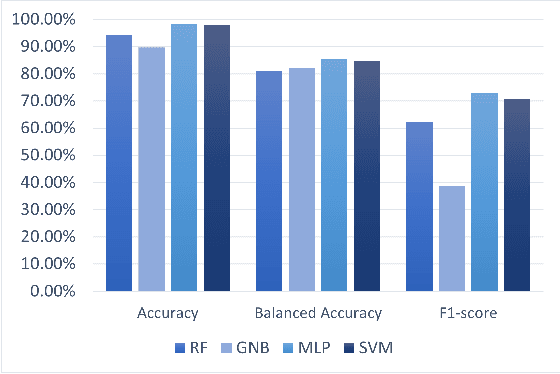
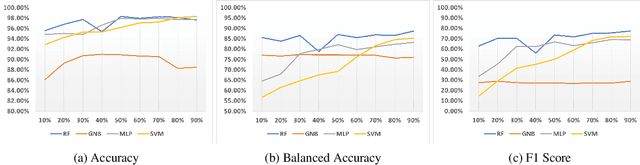
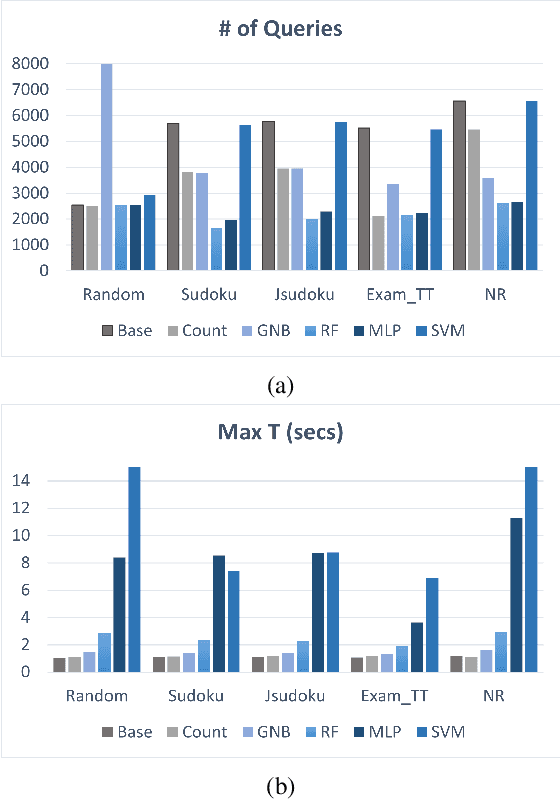
Constraint Programming (CP) has been successfully used to model and solve complex combinatorial problems. However, modeling is often not trivial and requires expertise, which is a bottleneck to wider adoption. In Constraint Acquisition (CA), the goal is to assist the user by automatically learning the model. In (inter)active CA, this is done by interactively posting queries to the user, e.g., asking whether a partial solution satisfies their (unspecified) constraints or not. While interac tive CA methods learn the constraints, the learning is related to symbolic concept learning, as the goal is to learn an exact representation. However, a large number of queries is still required to learn the model, which is a major limitation. In this paper, we aim to alleviate this limitation by tightening the connection of CA and Machine Learning (ML), by, for the first time in interactive CA, exploiting statistical ML methods. We propose to use probabilistic classification models to guide interactive CA to generate more promising queries. We discuss how to train classifiers to predict whether a candidate expression from the bias is a constraint of the problem or not, using both relation-based and scope-based features. We then show how the predictions can be used in all layers of interactive CA: the query generation, the scope finding, and the lowest-level constraint finding. We experimentally evaluate our proposed methods using different classifiers and show that our methods greatly outperform the state of the art, decreasing the number of queries needed to converge by up to 72%.
Holy Grail 2.0: From Natural Language to Constraint Models
Aug 03, 2023Twenty-seven years ago, E. Freuder highlighted that "Constraint programming represents one of the closest approaches computer science has yet made to the Holy Grail of programming: the user states the problem, the computer solves it". Nowadays, CP users have great modeling tools available (like Minizinc and CPMpy), allowing them to formulate the problem and then let a solver do the rest of the job, getting closer to the stated goal. However, this still requires the CP user to know the formalism and respect it. Another significant challenge lies in the expertise required to effectively model combinatorial problems. All this limits the wider adoption of CP. In this position paper, we investigate a possible approach to leverage pre-trained Large Language Models to extract models from textual problem descriptions. More specifically, we take inspiration from the Natural Language Processing for Optimization (NL4OPT) challenge and present early results with a decomposition-based prompting approach to GPT Models.
Guided Bottom-Up Interactive Constraint Acquisition
Jul 12, 2023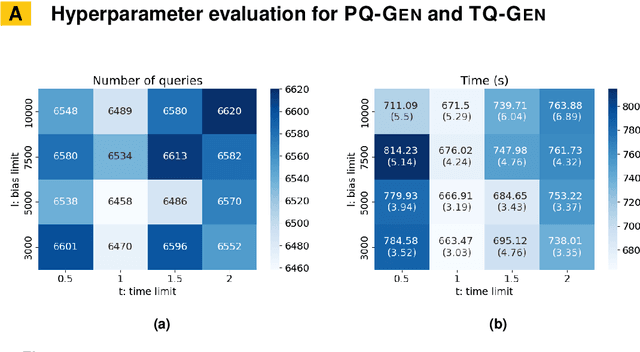

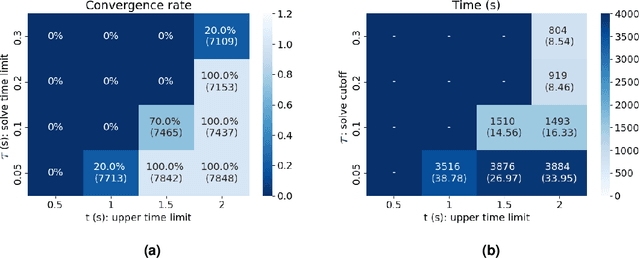

Constraint Acquisition (CA) systems can be used to assist in the modeling of constraint satisfaction problems. In (inter)active CA, the system is given a set of candidate constraints and posts queries to the user with the goal of finding the right constraints among the candidates. Current interactive CA algorithms suffer from at least two major bottlenecks. First, in order to converge, they require a large number of queries to be asked to the user. Second, they cannot handle large sets of candidate constraints, since these lead to large waiting times for the user. For this reason, the user must have fairly precise knowledge about what constraints the system should consider. In this paper, we alleviate these bottlenecks by presenting two novel methods that improve the efficiency of CA. First, we introduce a bottom-up approach named GrowAcq that reduces the maximum waiting time for the user and allows the system to handle much larger sets of candidate constraints. It also reduces the total number of queries for problems in which the target constraint network is not sparse. Second, we propose a probability-based method to guide query generation and show that it can significantly reduce the number of queries required to converge. We also propose a new technique that allows the use of openly accessible CP solvers in query generation, removing the dependency of existing methods on less well-maintained custom solvers that are not publicly available. Experimental results show that our proposed methods outperform state-of-the-art CA methods, reducing the number of queries by up to 60%. Our methods work well even in cases where the set of candidate constraints is 50 times larger than the ones commonly used in the literature.