 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility-Aware Decision-Focused Learning for Predicting Parameters in the Constraints
Oct 06, 2025When some parameters of a constrained optimization problem (COP) are uncertain, this gives rise to a predict-then-optimize (PtO) problem, comprising two stages -- the prediction of the unknown parameters from contextual information and the subsequent optimization using those predicted parameters. Decision-focused learning (DFL) implements the first stage by training a machine learning (ML) model to optimize the quality of the decisions made using the predicted parameters. When parameters in the constraints of a COP are predicted, the predicted parameters can lead to infeasible solutions. Therefore, it is important to simultaneously manage both feasibility and decision quality. We develop a DFL framework for predicting constraint parameters in a generic COP. While prior works typically assume that the underlying optimization problem is a linear program (LP) or integer linear program (ILP), our approach makes no such assumption. We derive two novel loss functions based on maximum likelihood estimation (MLE): the first one penalizes infeasibility (by penalizing when the predicted parameters lead to infeasible solutions), and the second one penalizes suboptimal decisions (by penalizing when the true optimal solution is infeasible under the predicted parameters). We introduce a single tunable parameter to form a weighted average of the two losses, allowing decision-makers to balance suboptimality and feasibility. We experimentally demonstrate that adjusting this parameter provides a decision-maker the control over the trade-off between the two. Moreover, across several COP instances, we find that for a single value of the tunable parameter, our method matches the performance of the existing baselines on suboptimality and feasibility.
Solver-Free Decision-Focused Learning for Linear Optimization Problems
May 28, 2025



Mathematical optimization is a fundamental tool for decision-making in a wide range of applications. However, in many real-world scenarios, the parameters of the optimization problem are not known a priori and must be predicted from contextual features. This gives rise to predict-then-optimize problems, where a machine learning model predicts problem parameters that are then used to make decisions via optimization. A growing body of work on decision-focused learning (DFL) addresses this setting by training models specifically to produce predictions that maximize downstream decision quality, rather than accuracy. While effective, DFL is computationally expensive, because it requires solving the optimization problem with the predicted parameters at each loss evaluation. In this work, we address this computational bottleneck for linear optimization problems, a common class of problems in both DFL literature and real-world applications. We propose a solver-free training method that exploits the geometric structure of linear optimization to enable efficient training with minimal degradation in solution quality. Our method is based on the insight that a solution is optimal if and only if it achieves an objective value that is at least as good as that of its adjacent vertices on the feasible polytope. Building on this, our method compares the estimated quality of the ground-truth optimal solution with that of its precomputed adjacent vertices, and uses this as loss function. Experiments demonstrate that our method significantly reduces computational cost while maintaining high decision quality.
Generalizing Constraint Models in Constraint Acquisition
Dec 19, 2024



Constraint Acquisition (CA) aims to widen the use of constraint programming by assisting users in the modeling process. However, most CA methods suffer from a significant drawback: they learn a single set of individual constraints for a specific problem instance, but cannot generalize these constraints to the parameterized constraint specifications of the problem. In this paper, we address this limitation by proposing GenCon, a novel approach to learn parameterized constraint models capable of modeling varying instances of the same problem. To achieve this generalization, we make use of statistical learning techniques at the level of individual constraints. Specifically, we propose to train a classifier to predict, for any possible constraint and parameterization, whether the constraint belongs to the problem. We then show how, for some classes of classifiers, we can extract decision rules to construct interpretable constraint specifications. This enables the generation of ground constraints for any parameter instantiation. Additionally, we present a generate-and-test approach that can be used with any classifier, to generate the ground constraints on the fly. Our empirical results demonstrate that our approach achieves high accuracy and is robust to noise in the input instances.
Learning to Learn in Interactive Constraint Acquisition
Dec 17, 2023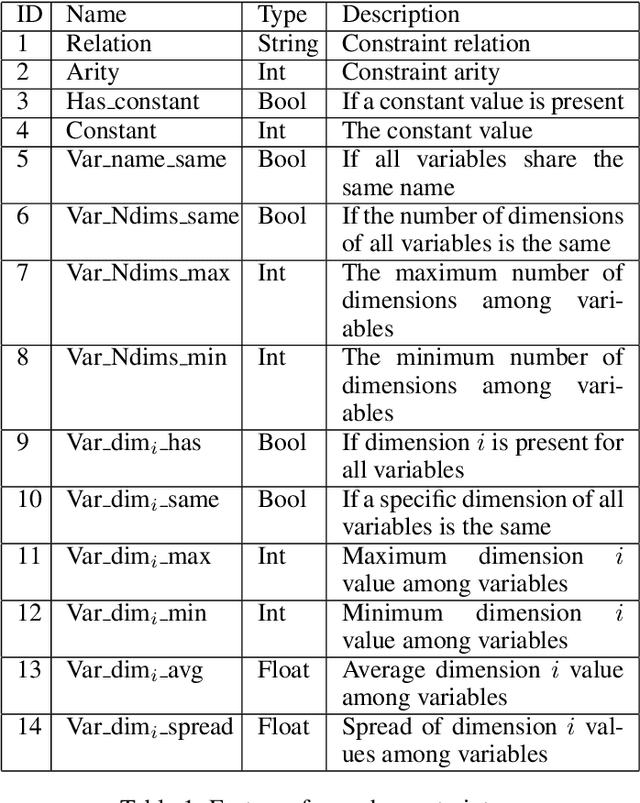
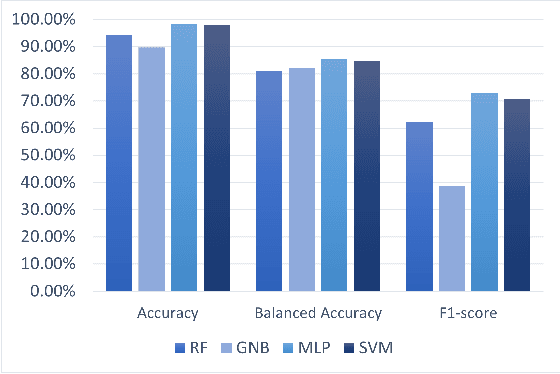
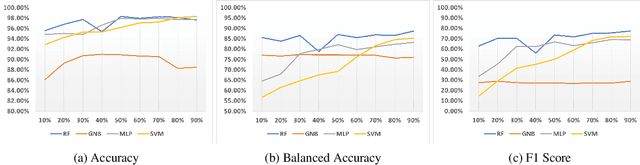
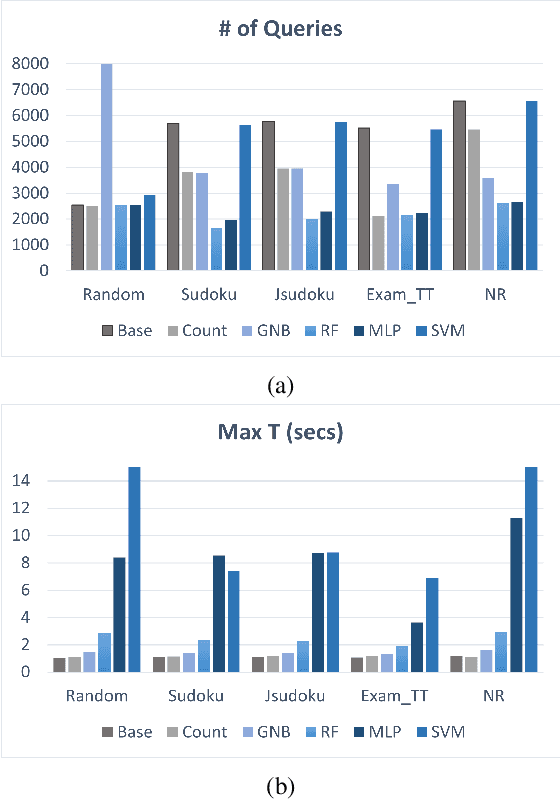
Constraint Programming (CP) has been successfully used to model and solve complex combinatorial problems. However, modeling is often not trivial and requires expertise, which is a bottleneck to wider adoption. In Constraint Acquisition (CA), the goal is to assist the user by automatically learning the model. In (inter)active CA, this is done by interactively posting queries to the user, e.g., asking whether a partial solution satisfies their (unspecified) constraints or not. While interac tive CA methods learn the constraints, the learning is related to symbolic concept learning, as the goal is to learn an exact representation. However, a large number of queries is still required to learn the model, which is a major limitation. In this paper, we aim to alleviate this limitation by tightening the connection of CA and Machine Learning (ML), by, for the first time in interactive CA, exploiting statistical ML methods. We propose to use probabilistic classification models to guide interactive CA to generate more promising queries. We discuss how to train classifiers to predict whether a candidate expression from the bias is a constraint of the problem or not, using both relation-based and scope-based features. We then show how the predictions can be used in all layers of interactive CA: the query generation, the scope finding, and the lowest-level constraint finding. We experimentally evaluate our proposed methods using different classifiers and show that our methods greatly outperform the state of the art, decreasing the number of queries needed to converge by up to 72%.
Decision-Focused Learning: Foundations, State of the Art, Benchmark and Future Opportunities
Aug 16, 2023



Decision-focused learning (DFL) is an emerging paradigm in machine learning which trains a model to optimize decisions, integrating prediction and optimization in an end-to-end system. This paradigm holds the promise to revolutionize decision-making in many real-world applications which operate under uncertainty, where the estimation of unknown parameters within these decision models often becomes a substantial roadblock. This paper presents a comprehensive review of DFL. It provides an in-depth analysis of the various techniques devised to integrate machine learning and optimization models, introduces a taxonomy of DFL methods distinguished by their unique characteristics, and conducts an extensive empirical evaluation of these methods proposing suitable benchmark dataset and tasks for DFL. Finally, the study provides valuable insights into current and potential future avenues in DFL research.
Guided Bottom-Up Interactive Constraint Acquisition
Jul 12, 2023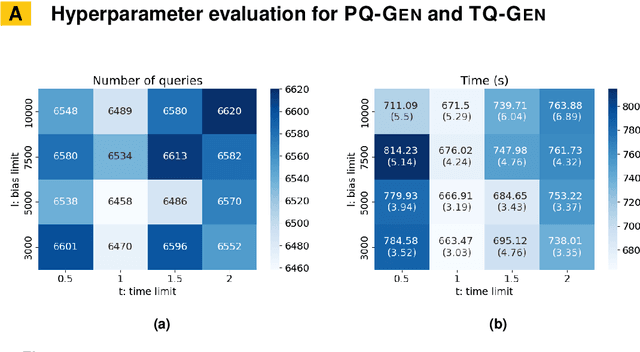

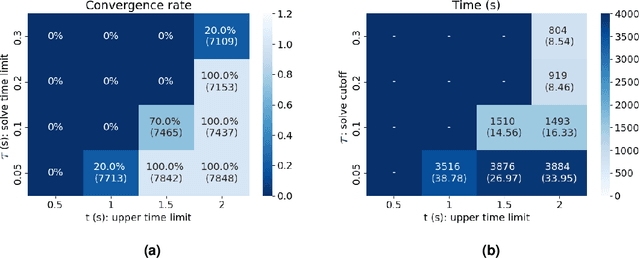

Constraint Acquisition (CA) systems can be used to assist in the modeling of constraint satisfaction problems. In (inter)active CA, the system is given a set of candidate constraints and posts queries to the user with the goal of finding the right constraints among the candidates. Current interactive CA algorithms suffer from at least two major bottlenecks. First, in order to converge, they require a large number of queries to be asked to the user. Second, they cannot handle large sets of candidate constraints, since these lead to large waiting times for the user. For this reason, the user must have fairly precise knowledge about what constraints the system should consider. In this paper, we alleviate these bottlenecks by presenting two novel methods that improve the efficiency of CA. First, we introduce a bottom-up approach named GrowAcq that reduces the maximum waiting time for the user and allows the system to handle much larger sets of candidate constraints. It also reduces the total number of queries for problems in which the target constraint network is not sparse. Second, we propose a probability-based method to guide query generation and show that it can significantly reduce the number of queries required to converge. We also propose a new technique that allows the use of openly accessible CP solvers in query generation, removing the dependency of existing methods on less well-maintained custom solvers that are not publicly available. Experimental results show that our proposed methods outperform state-of-the-art CA methods, reducing the number of queries by up to 60%. Our methods work well even in cases where the set of candidate constraints is 50 times larger than the ones commonly used in the literature.
Score Function Gradient Estimation to Widen the Applicability of Decision-Focused Learning
Jul 11, 2023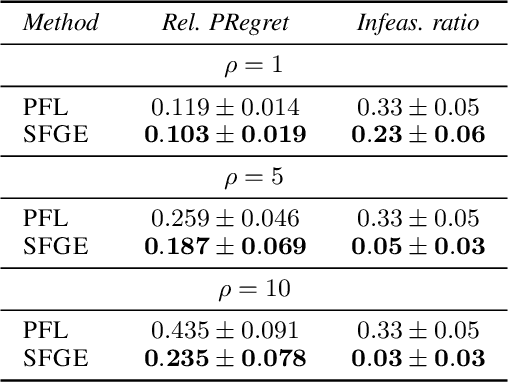
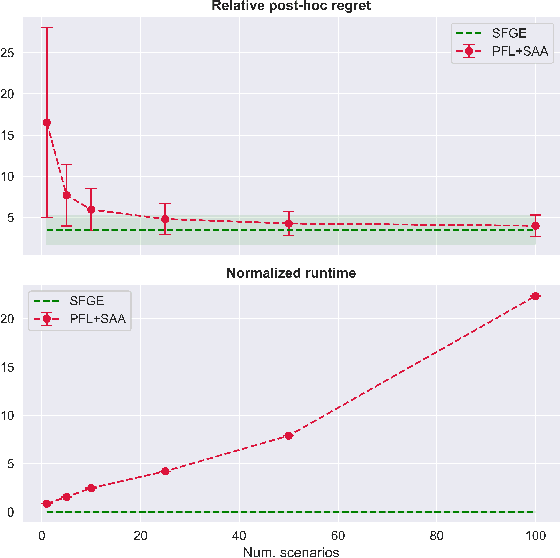
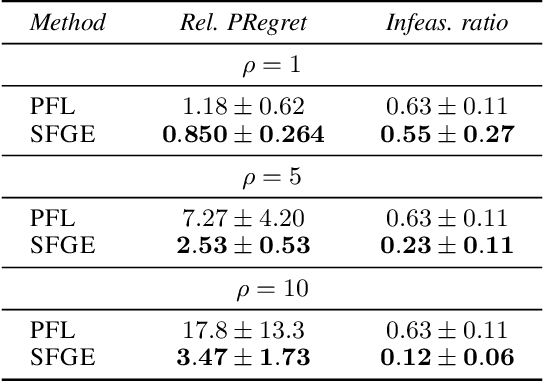
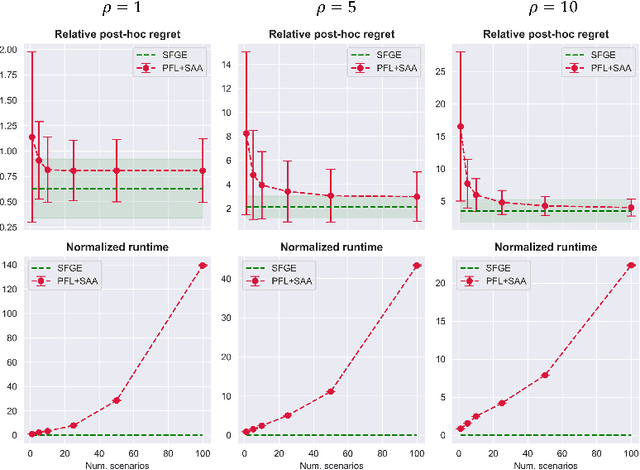
Many real-world optimization problems contain unknown parameters that must be predicted prior to solving. To train the predictive machine learning (ML) models involved, the commonly adopted approach focuses on maximizing predictive accuracy. However, this approach does not always lead to the minimization of the downstream task loss. Decision-focused learning (DFL) is a recently proposed paradigm whose goal is to train the ML model by directly minimizing the task loss. However, state-of-the-art DFL methods are limited by the assumptions they make about the structure of the optimization problem (e.g., that the problem is linear) and by the fact that can only predict parameters that appear in the objective function. In this work, we address these limitations by instead predicting \textit{distributions} over parameters and adopting score function gradient estimation (SFGE) to compute decision-focused updates to the predictive model, thereby widening the applicability of DFL. Our experiments show that by using SFGE we can: (1) deal with predictions that occur both in the objective function and in the constraints; and (2) effectively tackle two-stage stochastic optimization problems.