 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Focused Learning: Foundations, State of the Art, Benchmark and Future Opportunities
Aug 16, 2023



Decision-focused learning (DFL) is an emerging paradigm in machine learning which trains a model to optimize decisions, integrating prediction and optimization in an end-to-end system. This paradigm holds the promise to revolutionize decision-making in many real-world applications which operate under uncertainty, where the estimation of unknown parameters within these decision models often becomes a substantial roadblock. This paper presents a comprehensive review of DFL. It provides an in-depth analysis of the various techniques devised to integrate machine learning and optimization models, introduces a taxonomy of DFL methods distinguished by their unique characteristics, and conducts an extensive empirical evaluation of these methods proposing suitable benchmark dataset and tasks for DFL. Finally, the study provides valuable insights into current and potential future avenues in DFL research.
Score Function Gradient Estimation to Widen the Applicability of Decision-Focused Learning
Jul 11, 2023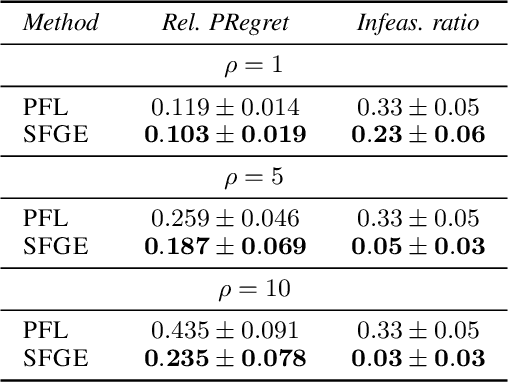
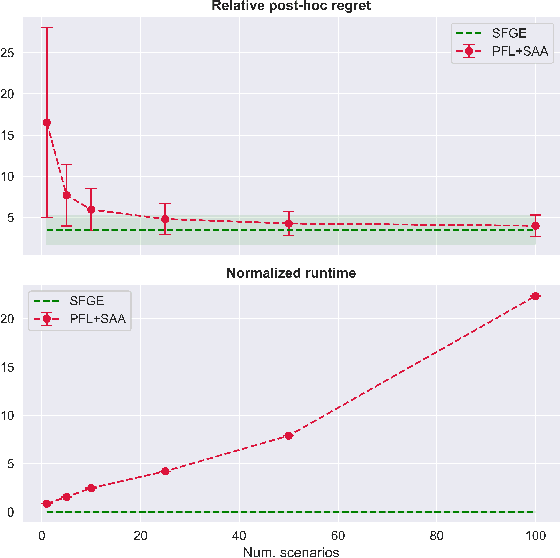
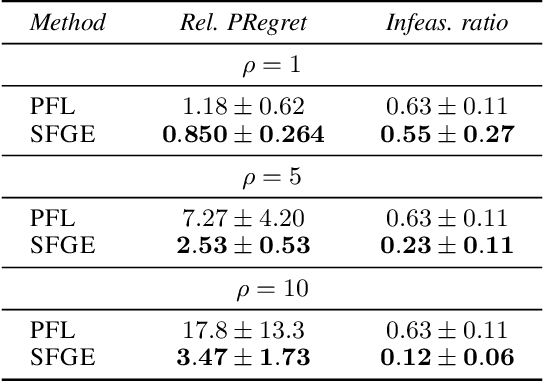
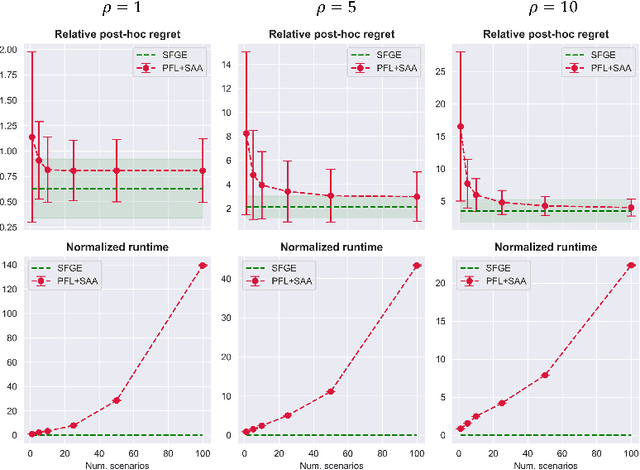
Many real-world optimization problems contain unknown parameters that must be predicted prior to solving. To train the predictive machine learning (ML) models involved, the commonly adopted approach focuses on maximizing predictive accuracy. However, this approach does not always lead to the minimization of the downstream task loss. Decision-focused learning (DFL) is a recently proposed paradigm whose goal is to train the ML model by directly minimizing the task loss. However, state-of-the-art DFL methods are limited by the assumptions they make about the structure of the optimization problem (e.g., that the problem is linear) and by the fact that can only predict parameters that appear in the objective function. In this work, we address these limitations by instead predicting \textit{distributions} over parameters and adopting score function gradient estimation (SFGE) to compute decision-focused updates to the predictive model, thereby widening the applicability of DFL. Our experiments show that by using SFGE we can: (1) deal with predictions that occur both in the objective function and in the constraints; and (2) effectively tackle two-stage stochastic optimization problems.
Probability estimation and structured output prediction for learning preferences in last mile delivery
Jan 25, 2022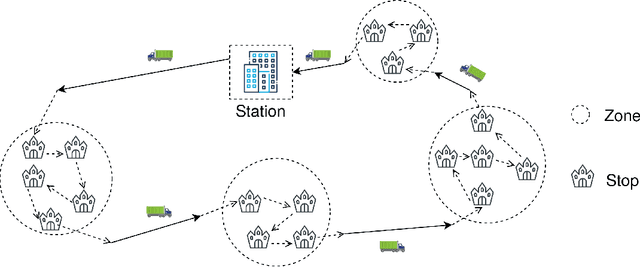
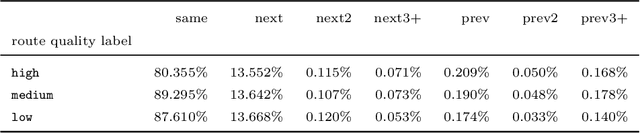
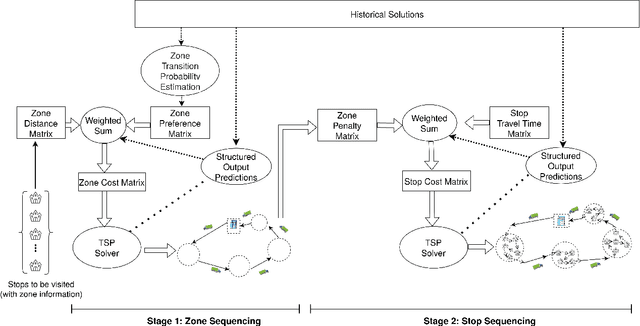
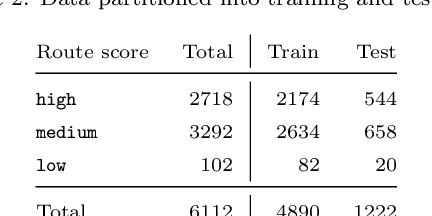
We study the problem of learning the preferences of drivers and planners in the context of last mile delivery. Given a data set containing historical decisions and delivery locations, the goal is to capture the implicit preferences of the decision-makers. We consider two ways to use the historical data: one is through a probability estimation method that learns transition probabilities between stops (or zones). This is a fast and accurate method, recently studied in a VRP setting. Furthermore, we explore the use of machine learning to infer how to best balance multiple objectives such as distance, probability and penalties. Specifically, we cast the learning problem as a structured output prediction problem, where training is done by repeatedly calling the TSP solver. Another important aspect we consider is that for last-mile delivery, every address is a potential client and hence the data is very sparse. Hence, we propose a two-stage approach that first learns preferences at the zone level in order to compute a zone routing; after which a penalty-based TSP computes the stop routing. Results show that the zone transition probability estimation performs well, and that the structured output prediction learning can improve the results further. We hence showcase a successful combination of both probability estimation and machine learning, all the while using standard TSP solvers, both during learning and to compute the final solution; this means the methodology is applicable to other, real-life, TSP variants, or proprietary solvers.
Predict and Optimize: Through the Lens of Learning to Rank
Dec 07, 2021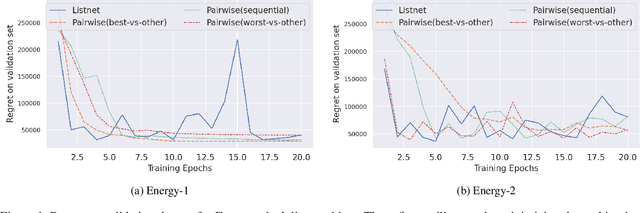
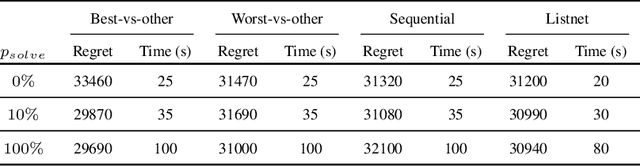
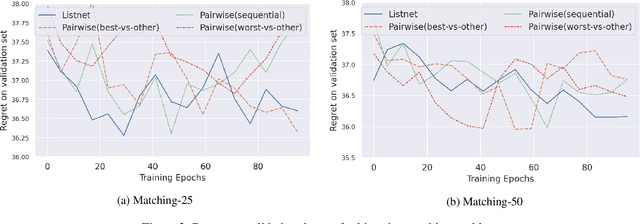

In the last years predict-and-optimize approaches (Elmachtoub and Grigas 2021; Wilder, Dilkina, and Tambe 2019) have received increasing attention. These problems have the settings where the predictions of predictive machine learning (ML) models are fed to downstream optimization problems for decision making. Predict-and-optimize approaches propose to train the ML models, often neural network models, by directly optimizing the quality of decisions made by the optimization solvers. However, one major bottleneck of predict-and-optimize approaches is solving the optimization problem for each training instance at every epoch. To address this challenge, Mulamba et al. (2021) propose noise contrastive estimation by caching feasible solutions. In this work, we show the noise contrastive estimation can be considered a case of learning to rank the solution cache. We also develop pairwise and listwise ranking loss functions, which can be differentiated in closed form without the need of solving the optimization problem. By training with respect to these surrogate loss function, we empirically show that we are able to minimize the regret of the predictions.
Discrete solution pools and noise-contrastive estimation for predict-and-optimize
Nov 10, 2020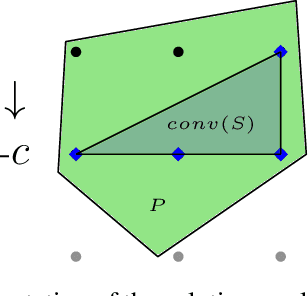


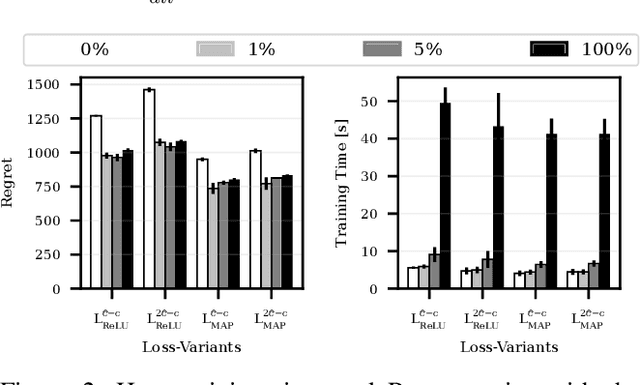
Numerous real-life decision-making processes involve solving a combinatorial optimization problem with uncertain input that can be estimated from historic data. There is a growing interest in decision-focused learning methods, where the loss function used for learning to predict the uncertain input uses the outcome of solving the combinatorial problem over a set of predictions. Different surrogate loss functions have been identified, often using a continuous approximation of the combinatorial problem. However, a key bottleneck is that to compute the loss, one has to solve the combinatorial optimisation problem for each training instance in each epoch, which is computationally expensive even in the case of continuous approximations. We propose a different solver-agnostic method for decision-focused learning, namely by considering a pool of feasible solutions as a discrete approximation of the full combinatorial problem. Solving is now trivial through a single pass over the solution pool. We design several variants of a noise-contrastive loss over the solution pool, which we substantiate theoretically and empirically. Furthermore, we show that by dynamically re-solving only a fraction of the training instances each epoch, our method performs on par with the state of the art, whilst drastically reducing the time spent solving, hence increasing the feasibility of predict-and-optimize for larger problems.
Hybrid Classification and Reasoning for Image-based Constraint Solving
Mar 24, 2020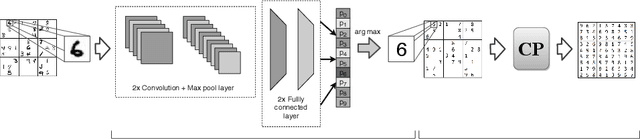

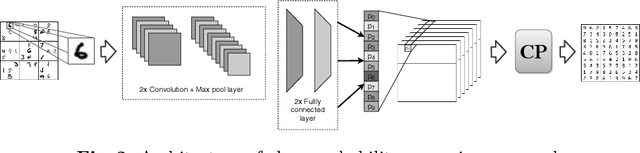
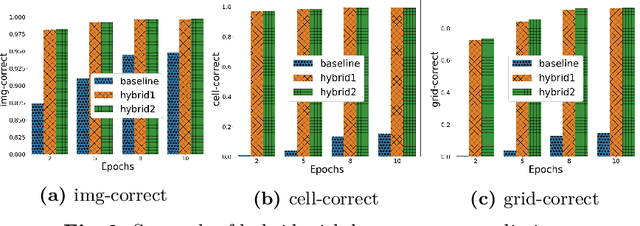
There is an increased interest in solving complex constrained problems where part of the input is not given as facts but received as raw sensor data such as images or speech. We will use "visual sudoku" as a prototype problem, where the given cell digits are handwritten and provided as an image thereof. In this case, one first has to train and use a classifier to label the images, so that the labels can be used for solving the problem. In this paper, we explore the hybridization of classifying the images with the reasoning of a constraint solver. We show that pure constraint reasoning on predictions does not give satisfactory results. Instead, we explore the possibilities of a tighter integration, by exposing the probabilistic estimates of the classifier to the constraint solver. This allows joint inference on these probabilistic estimates, where we use the solver to find the maximum likelihood solution. We explore the trade-off between the power of the classifier and the power of the constraint reasoning, as well as further integration through the additional use of structural knowledge. Furthermore, we investigate the effect of calibration of the probabilistic estimates on the reasoning. Our results show that such hybrid approaches vastly outperform a separate approach, which encourages a further integration of prediction (probabilities) and constraint solving.