 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMiLE: Provably Enforcing Global Relational Properties in Neural Networks
Nov 10, 2025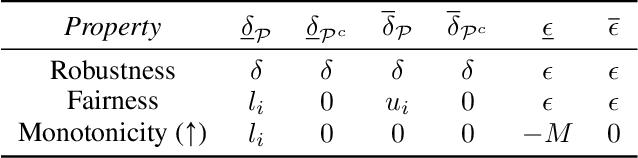
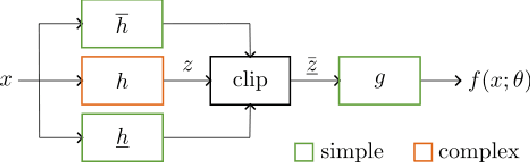
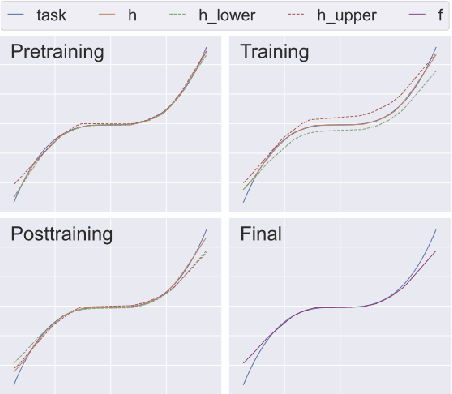
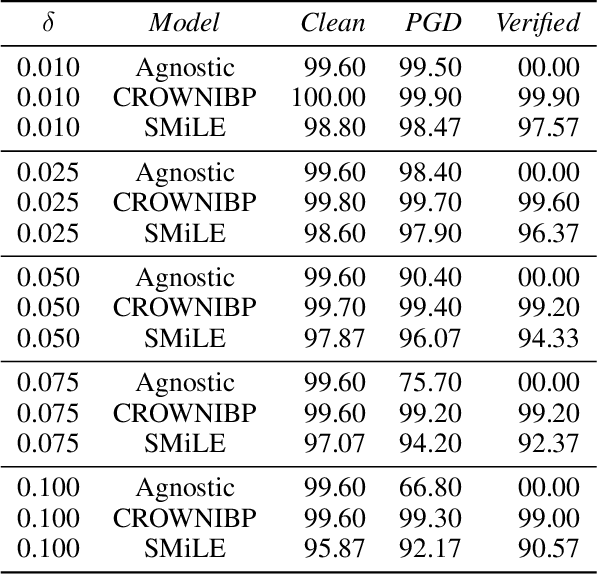
Artificial Intelligence systems are increasingly deployed in settings where ensuring robustness, fairness, or domain-specific properties is essential for regulation compliance and alignment with human values. However, especially on Neural Networks, property enforcement is very challenging, and existing methods are limited to specific constraints or local properties (defined around datapoints), or fail to provide full guarantees. We tackle these limitations by extending SMiLE, a recently proposed enforcement framework for NNs, to support global relational properties (defined over the entire input space). The proposed approach scales well with model complexity, accommodates general properties and backbones, and provides full satisfaction guarantees. We evaluate SMiLE on monotonicity, global robustness, and individual fairness, on synthetic and real data, for regression and classification tasks. Our approach is competitive with property-specific baselines in terms of accuracy and runtime, and strictly superior in terms of generality and level of guarantees. Overall, our results emphasize the potential of the SMiLE framework as a platform for future research and applications.
Robust Non-Linear Correlations via Polynomial Regression
Sep 11, 2025The Hirschfeld-Gebelein-R\'enyi (HGR) correlation coefficient is an extension of Pearson's correlation that is not limited to linear correlations, with potential applications in algorithmic fairness, scientific analysis, and causal discovery. Recently, novel algorithms to estimate HGR in a differentiable manner have been proposed to facilitate its use as a loss regularizer in constrained machine learning applications. However, the inherent uncomputability of HGR requires a bias-variance trade-off, which can possibly compromise the robustness of the proposed methods, hence raising technical concerns if applied in real-world scenarios. We introduce a novel computational approach for HGR that relies on user-configurable polynomial kernels, offering greater robustness compared to previous methods and featuring a faster yet almost equally effective restriction. Our approach provides significant advantages in terms of robustness and determinism, making it a more reliable option for real-world applications. Moreover, we present a brief experimental analysis to validate the applicability of our approach within a constrained machine learning framework, showing that its computation yields an insightful subgradient that can serve as a loss regularizer.
Hybrid Reinforcement Learning and Search for Flight Trajectory Planning
Sep 04, 2025This paper explores the combination of Reinforcement Learning (RL) and search-based path planners to speed up the optimization of flight paths for airliners, where in case of emergency a fast route re-calculation can be crucial. The fundamental idea is to train an RL Agent to pre-compute near-optimal paths based on location and atmospheric data and use those at runtime to constrain the underlying path planning solver and find a solution within a certain distance from the initial guess. The approach effectively reduces the size of the solver's search space, significantly speeding up route optimization. Although global optimality is not guaranteed, empirical results conducted with Airbus aircraft's performance models show that fuel consumption remains nearly identical to that of an unconstrained solver, with deviations typically within 1%. At the same time, computation speed can be improved by up to 50% as compared to using a conventional solver alone.
Constrained Machine Learning Through Hyperspherical Representation
Apr 11, 2025The problem of ensuring constraints satisfaction on the output of machine learning models is critical for many applications, especially in safety-critical domains. Modern approaches rely on penalty-based methods at training time, which do not guarantee to avoid constraints violations; or constraint-specific model architectures (e.g., for monotonocity); or on output projection, which requires to solve an optimization problem that might be computationally demanding. We present the Hypersherical Constrained Representation, a novel method to enforce constraints in the output space for convex and bounded feasibility regions (generalizable to star domains). Our method operates on a different representation system, where Euclidean coordinates are converted into hyperspherical coordinates relative to the constrained region, which can only inherently represent feasible points. Experiments on a synthetic and a real-world dataset show that our method has predictive performance comparable to the other approaches, can guarantee 100% constraint satisfaction, and has a minimal computational cost at inference time.
Language Models Are Implicitly Continuous
Apr 04, 2025Language is typically modelled with discrete sequences. However, the most successful approaches to language modelling, namely neural networks, are continuous and smooth function approximators. In this work, we show that Transformer-based language models implicitly learn to represent sentences as continuous-time functions defined over a continuous input space. This phenomenon occurs in most state-of-the-art Large Language Models (LLMs), including Llama2, Llama3, Phi3, Gemma, Gemma2, and Mistral, and suggests that LLMs reason about language in ways that fundamentally differ from humans. Our work formally extends Transformers to capture the nuances of time and space continuity in both input and output space. Our results challenge the traditional interpretation of how LLMs understand language, with several linguistic and engineering implications.
SMLE: Safe Machine Learning via Embedded Overapproximation
Sep 30, 2024



Despite the extent of recent advances in Machine Learning (ML) and Neural Networks, providing formal guarantees on the behavior of these systems is still an open problem, and a crucial requirement for their adoption in regulated or safety-critical scenarios. We consider the task of training differentiable ML models guaranteed to satisfy designer-chosen properties, stated as input-output implications. This is very challenging, due to the computational complexity of rigorously verifying and enforcing compliance in modern neural models. We provide an innovative approach based on three components: 1) a general, simple architecture enabling efficient verification with a conservative semantic; 2) a rigorous training algorithm based on the Projected Gradient Method; 3) a formulation of the problem of searching for strong counterexamples. The proposed framework, being only marginally affected by model complexity, scales well to practical applications, and produces models that provide full property satisfaction guarantees. We evaluate our approach on properties defined by linear inequalities in regression, and on mutually exclusive classes in multilabel classification. Our approach is competitive with a baseline that includes property enforcement during preprocessing, i.e. on the training data, as well as during postprocessing, i.e. on the model predictions. Finally, our contributions establish a framework that opens up multiple research directions and potential improvements.
QAL-BP: An Augmented Lagrangian Quantum Approach for Bin Packing Problem
Sep 22, 2023The bin packing is a well-known NP-Hard problem in the domain of artificial intelligence, posing significant challenges in finding efficient solutions. Conversely, recent advancements in quantum technologies have shown promising potential for achieving substantial computational speedup, particularly in certain problem classes, such as combinatorial optimization. In this study, we introduce QAL-BP, a novel Quadratic Unconstrained Binary Optimization (QUBO) formulation designed specifically for bin packing and suitable for quantum computation. QAL-BP utilizes the augmented Lagrangian method to incorporate the bin packing constraints into the objective function while also facilitating an analytical estimation of heuristic, but empirically robust, penalty multipliers. This approach leads to a more versatile and generalizable model that eliminates the need for empirically calculating instance-dependent Lagrangian coefficients, a requirement commonly encountered in alternative QUBO formulations for similar problems. To assess the effectiveness of our proposed approach, we conduct experiments on a set of bin-packing instances using a real Quantum Annealing device. Additionally, we compare the results with those obtained from two different classical solvers, namely simulated annealing and Gurobi. The experimental findings not only confirm the correctness of the proposed formulation but also demonstrate the potential of quantum computation in effectively solving the bin-packing problem, particularly as more reliable quantum technology becomes available.
Score Function Gradient Estimation to Widen the Applicability of Decision-Focused Learning
Jul 11, 2023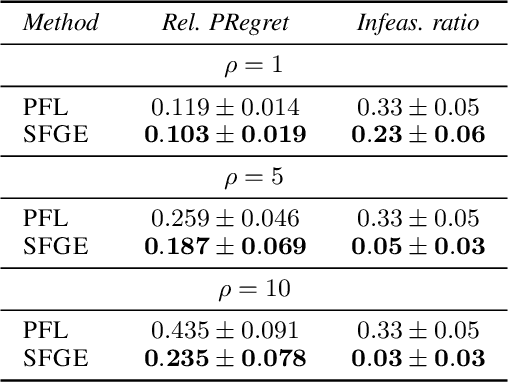
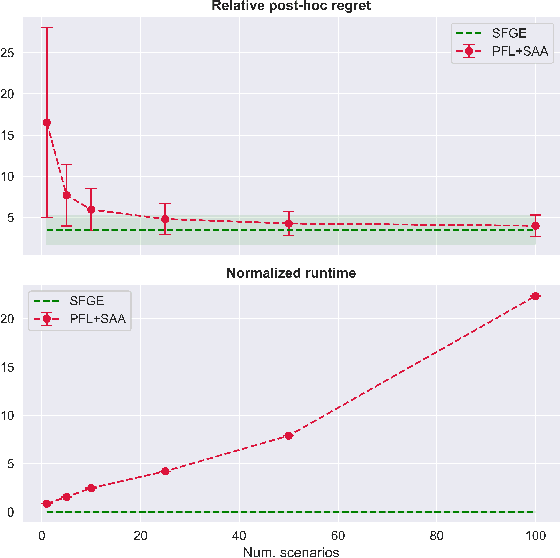
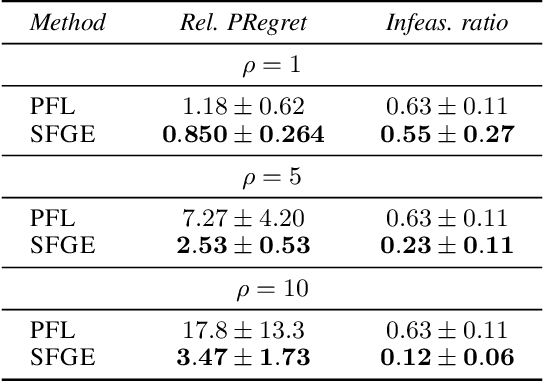
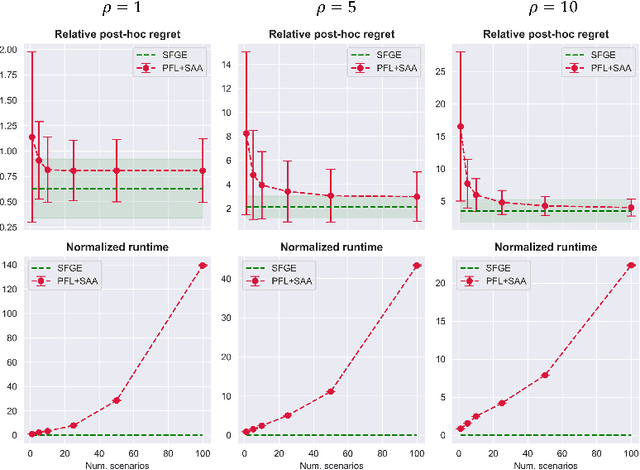
Many real-world optimization problems contain unknown parameters that must be predicted prior to solving. To train the predictive machine learning (ML) models involved, the commonly adopted approach focuses on maximizing predictive accuracy. However, this approach does not always lead to the minimization of the downstream task loss. Decision-focused learning (DFL) is a recently proposed paradigm whose goal is to train the ML model by directly minimizing the task loss. However, state-of-the-art DFL methods are limited by the assumptions they make about the structure of the optimization problem (e.g., that the problem is linear) and by the fact that can only predict parameters that appear in the objective function. In this work, we address these limitations by instead predicting \textit{distributions} over parameters and adopting score function gradient estimation (SFGE) to compute decision-focused updates to the predictive model, thereby widening the applicability of DFL. Our experiments show that by using SFGE we can: (1) deal with predictions that occur both in the objective function and in the constraints; and (2) effectively tackle two-stage stochastic optimization problems.
Computational Asymmetries in Robust Classification
Jun 25, 2023In the context of adversarial robustness, we make three strongly related contributions. First, we prove that while attacking ReLU classifiers is $\mathit{NP}$-hard, ensuring their robustness at training time is $\Sigma^2_P$-hard (even on a single example). This asymmetry provides a rationale for the fact that robust classifications approaches are frequently fooled in the literature. Second, we show that inference-time robustness certificates are not affected by this asymmetry, by introducing a proof-of-concept approach named Counter-Attack (CA). Indeed, CA displays a reversed asymmetry: running the defense is $\mathit{NP}$-hard, while attacking it is $\Sigma_2^P$-hard. Finally, motivated by our previous result, we argue that adversarial attacks can be used in the context of robustness certification, and provide an empirical evaluation of their effectiveness. As a byproduct of this process, we also release UG100, a benchmark dataset for adversarial attacks.
An analysis of Universal Differential Equations for data-driven discovery of Ordinary Differential Equations
Jun 17, 2023

In the last decade, the scientific community has devolved its attention to the deployment of data-driven approaches in scientific research to provide accurate and reliable analysis of a plethora of phenomena. Most notably, Physics-informed Neural Networks and, more recently, Universal Differential Equations (UDEs) proved to be effective both in system integration and identification. However, there is a lack of an in-depth analysis of the proposed techniques. In this work, we make a contribution by testing the UDE framework in the context of Ordinary Differential Equations (ODEs) discovery. In our analysis, performed on two case studies, we highlight some of the issues arising when combining data-driven approaches and numerical solvers, and we investigate the importance of the data collection process. We believe that our analysis represents a significant contribution in investigating the capabilities and limitations of Physics-informed Machine Learning frameworks.