 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLeAN: Continual Learning Adaptive Normalization in Dynamic Environments
Mar 18, 2026Artificial intelligence systems predominantly rely on static data distributions, making them ineffective in dynamic real-world environments, such as cybersecurity, autonomous transportation, or finance, where data shifts frequently. Continual learning offers a potential solution by enabling models to learn from sequential data while retaining prior knowledge. However, a critical and underexplored issue in this domain is data normalization. Conventional normalization methods, such as min-max scaling, presuppose access to the entire dataset, which is incongruent with the sequential nature of continual learning. In this paper we introduce Continual Learning Adaptive Normalization (CLeAN), a novel adaptive normalization technique designed for continual learning in tabular data. CLeAN involves the estimation of global feature scales using learnable parameters that are updated via an Exponential Moving Average (EMA) module, enabling the model to adapt to evolving data distributions. Through comprehensive evaluations on two datasets and various continual learning strategies, including Resevoir Experience Replay, A-GEM, and EwC we demonstrate that CLeAN not only improves model performance on new data but also mitigates catastrophic forgetting. The findings underscore the importance of adaptive normalization in enhancing the stability and effectiveness of tabular data, offering a novel perspective on the use of normalization to preserve knowledge in dynamic learning environments.
A Diffusion-Based Generative Prior Approach to Sparse-view Computed Tomography
Feb 11, 2026The reconstruction of X-rays CT images from sparse or limited-angle geometries is a highly challenging task. The lack of data typically results in artifacts in the reconstructed image and may even lead to object distortions. For this reason, the use of deep generative models in this context has great interest and potential success. In the Deep Generative Prior (DGP) framework, the use of diffusion-based generative models is combined with an iterative optimization algorithm for the reconstruction of CT images from sinograms acquired under sparse geometries, to maintain the explainability of a model-based approach while introducing the generative power of a neural network. There are therefore several aspects that can be further investigated within these frameworks to improve reconstruction quality, such as image generation, the model, and the iterative algorithm used to solve the minimization problem, for which we propose modifications with respect to existing approaches. The results obtained even under highly sparse geometries are very promising, although further research is clearly needed in this direction.
Language Models Are Implicitly Continuous
Apr 04, 2025Language is typically modelled with discrete sequences. However, the most successful approaches to language modelling, namely neural networks, are continuous and smooth function approximators. In this work, we show that Transformer-based language models implicitly learn to represent sentences as continuous-time functions defined over a continuous input space. This phenomenon occurs in most state-of-the-art Large Language Models (LLMs), including Llama2, Llama3, Phi3, Gemma, Gemma2, and Mistral, and suggests that LLMs reason about language in ways that fundamentally differ from humans. Our work formally extends Transformers to capture the nuances of time and space continuity in both input and output space. Our results challenge the traditional interpretation of how LLMs understand language, with several linguistic and engineering implications.
Deep Guess acceleration for explainable image reconstruction in sparse-view CT
Dec 02, 2024Sparse-view Computed Tomography (CT) is an emerging protocol designed to reduce X-ray dose radiation in medical imaging. Traditional Filtered Back Projection algorithm reconstructions suffer from severe artifacts due to sparse data. In contrast, Model-Based Iterative Reconstruction (MBIR) algorithms, though better at mitigating noise through regularization, are too computationally costly for clinical use. This paper introduces a novel technique, denoted as the Deep Guess acceleration scheme, using a trained neural network both to quicken the regularized MBIR and to enhance the reconstruction accuracy. We integrate state-of-the-art deep learning tools to initialize a clever starting guess for a proximal algorithm solving a non-convex model and thus computing an interpretable solution image in a few iterations. Experimental results on real CT images demonstrate the Deep Guess effectiveness in (very) sparse tomographic protocols, where it overcomes its mere variational counterpart and many data-driven approaches at the state of the art. We also consider a ground truth-free implementation and test the robustness of the proposed framework to noise.
LIP-CAR: contrast agent reduction by a deep learned inverse problem
Jul 15, 2024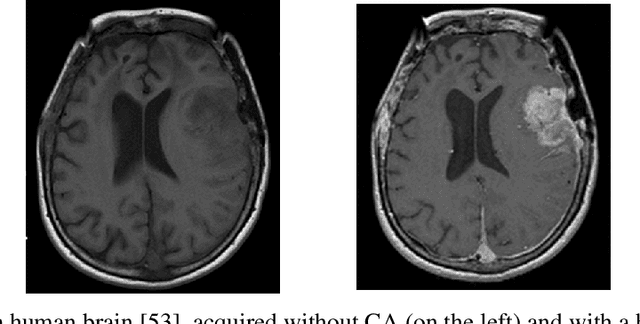
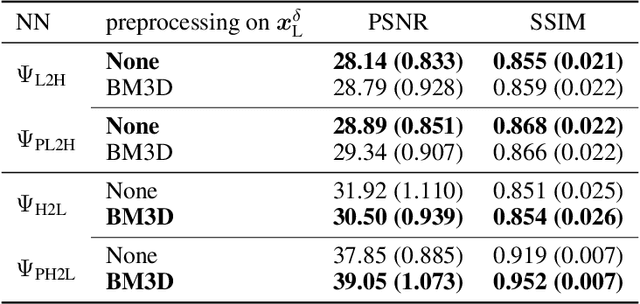
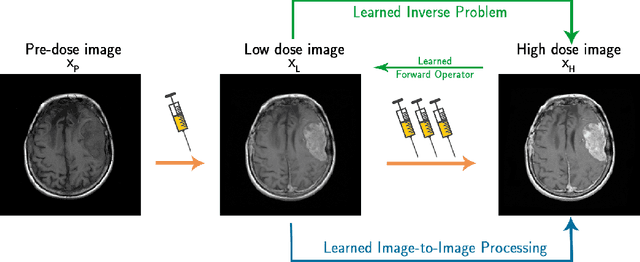
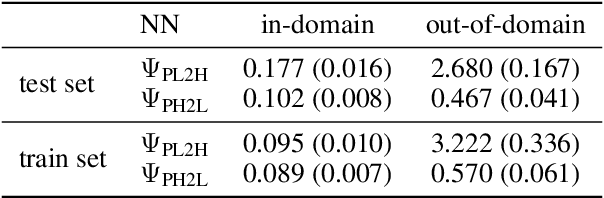
The adoption of contrast agents in medical imaging protocols is crucial for accurate and timely diagnosis. While highly effective and characterized by an excellent safety profile, the use of contrast agents has its limitation, including rare risk of allergic reactions, potential environmental impact and economic burdens on patients and healthcare systems. In this work, we address the contrast agent reduction (CAR) problem, which involves reducing the administered dosage of contrast agent while preserving the visual enhancement. The current literature on the CAR task is based on deep learning techniques within a fully image processing framework. These techniques digitally simulate high-dose images from images acquired with a low dose of contrast agent. We investigate the feasibility of a ``learned inverse problem'' (LIP) approach, as opposed to the end-to-end paradigm in the state-of-the-art literature. Specifically, we learn the image-to-image operator that maps high-dose images to their corresponding low-dose counterparts, and we frame the CAR task as an inverse problem. We then solve this problem through a regularized optimization reformulation. Regularization methods are well-established mathematical techniques that offer robustness and explainability. Our approach combines these rigorous techniques with cutting-edge deep learning tools. Numerical experiments performed on pre-clinical medical images confirm the effectiveness of this strategy, showing improved stability and accuracy in the simulated high-dose images.
Space-Variant Total Variation boosted by learning techniques in few-view tomographic imaging
Apr 25, 2024This paper focuses on the development of a space-variant regularization model for solving an under-determined linear inverse problem. The case study is a medical image reconstruction from few-view tomographic noisy data. The primary objective of the proposed optimization model is to achieve a good balance between denoising and the preservation of fine details and edges, overcoming the performance of the popular and largely used Total Variation (TV) regularization through the application of appropriate pixel-dependent weights. The proposed strategy leverages the role of gradient approximations for the computation of the space-variant TV weights. For this reason, a convolutional neural network is designed, to approximate both the ground truth image and its gradient using an elastic loss function in its training. Additionally, the paper provides a theoretical analysis of the proposed model, showing the uniqueness of its solution, and illustrates a Chambolle-Pock algorithm tailored to address the specific problem at hand. This comprehensive framework integrates innovative regularization techniques with advanced neural network capabilities, demonstrating promising results in achieving high-quality reconstructions from low-sampled tomographic data.
Ambiguity in solving imaging inverse problems with deep learning based operators
May 31, 2023In recent years, large convolutional neural networks have been widely used as tools for image deblurring, because of their ability in restoring images very precisely. It is well known that image deblurring is mathematically modeled as an ill-posed inverse problem and its solution is difficult to approximate when noise affects the data. Really, one limitation of neural networks for deblurring is their sensitivity to noise and other perturbations, which can lead to instability and produce poor reconstructions. In addition, networks do not necessarily take into account the numerical formulation of the underlying imaging problem, when trained end-to-end. In this paper, we propose some strategies to improve stability without losing to much accuracy to deblur images with deep-learning based methods. First, we suggest a very small neural architecture, which reduces the execution time for training, satisfying a green AI need, and does not extremely amplify noise in the computed image. Second, we introduce a unified framework where a pre-processing step balances the lack of stability of the following, neural network-based, step. Two different pre-processors are presented: the former implements a strong parameter-free denoiser, and the latter is a variational model-based regularized formulation of the latent imaging problem. This framework is also formally characterized by mathematical analysis. Numerical experiments are performed to verify the accuracy and stability of the proposed approaches for image deblurring when unknown or not-quantified noise is present; the results confirm that they improve the network stability with respect to noise. In particular, the model-based framework represents the most reliable trade-off between visual precision and robustness.
To be or not to be stable, that is the question: understanding neural networks for inverse problems
Nov 24, 2022



The solution of linear inverse problems arising, for example, in signal and image processing is a challenging problem, since the ill-conditioning amplifies the noise on the data. Recently introduced deep-learning based algorithms overwhelm the more traditional model-based approaches but they typically suffer from instability with respect to data perturbation. In this paper, we theoretically analyse the trade-off between neural networks stability and accuracy in the solution of linear inverse problems. Moreover, we propose different supervised and unsupervised solutions, to increase network stability by maintaining good accuracy, by inheriting, in the network training, regularization from a model-based iterative scheme. Extensive numerical experiments on image deblurring confirm the theoretical results and the effectiveness of the proposed networks in solving inverse problems with stability with respect to noise.
Dissecting FLOPs along input dimensions for GreenAI cost estimations
Jul 26, 2021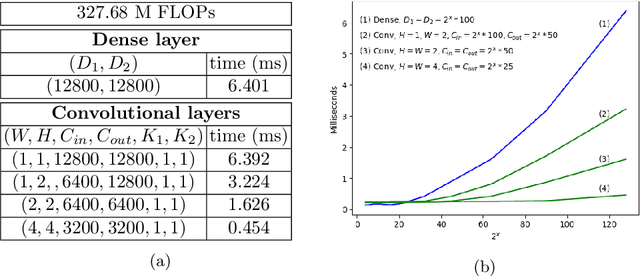
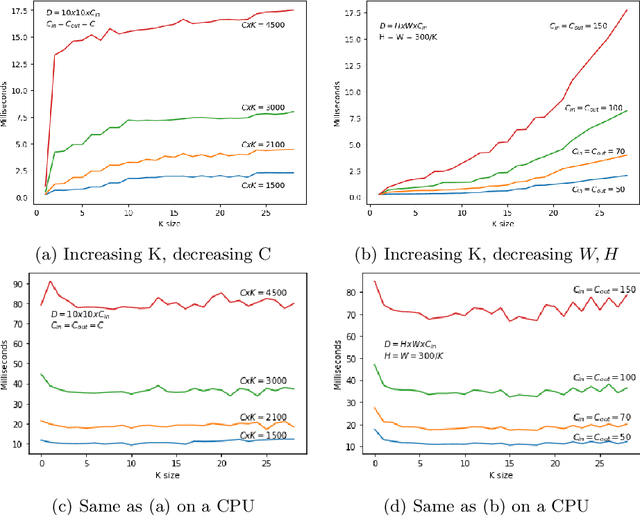
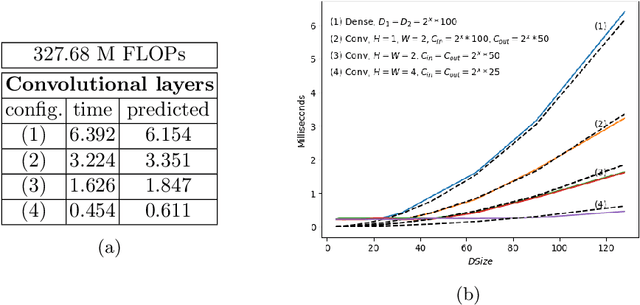
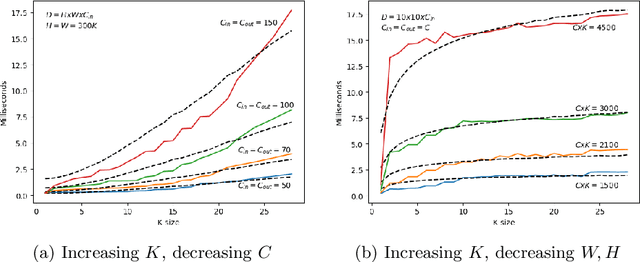
The term GreenAI refers to a novel approach to Deep Learning, that is more aware of the ecological impact and the computational efficiency of its methods. The promoters of GreenAI suggested the use of Floating Point Operations (FLOPs) as a measure of the computational cost of Neural Networks; however, that measure does not correlate well with the energy consumption of hardware equipped with massively parallel processing units like GPUs or TPUs. In this article, we propose a simple refinement of the formula used to compute floating point operations for convolutional layers, called {\alpha}-FLOPs, explaining and correcting the traditional discrepancy with respect to different layers, and closer to reality. The notion of {\alpha}-FLOPs relies on the crucial insight that, in case of inputs with multiple dimensions, there is no reason to believe that the speedup offered by parallelism will be uniform along all different axes.