 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfit is the Red Team: Stress-Testing Agents in Strategic Economic Interactions
Mar 21, 2026As agentic systems move into real-world deployments, their decisions increasingly depend on external inputs such as retrieved content, tool outputs, and information provided by other actors. When these inputs can be strategically shaped by adversaries, the relevant security risk extends beyond a fixed library of prompt attacks to adaptive strategies that steer agents toward unfavorable outcomes. We propose profit-driven red teaming, a stress-testing protocol that replaces handcrafted attacks with a learned opponent trained to maximize its profit using only scalar outcome feedback. The protocol requires no LLM-as-judge scoring, attack labels, or attack taxonomy, and is designed for structured settings with auditable outcomes. We instantiate it in a lean arena of four canonical economic interactions, which provide a controlled testbed for adaptive exploitability. In controlled experiments, agents that appear strong against static baselines become consistently exploitable under profit-optimized pressure, and the learned opponent discovers probing, anchoring, and deceptive commitments without explicit instruction. We then distill exploit episodes into concise prompt rules for the agent, which make most previously observed failures ineffective and substantially improve target performance. These results suggest that profit-driven red-team data can provide a practical route to improving robustness in structured agent settings with auditable outcomes.
Benchmarking at the Edge of Comprehension
Feb 15, 2026As frontier Large Language Models (LLMs) increasingly saturate new benchmarks shortly after they are published, benchmarking itself is at a juncture: if frontier models keep improving, it will become increasingly hard for humans to generate discriminative tasks, provide accurate ground-truth answers, or evaluate complex solutions. If benchmarking becomes infeasible, our ability to measure any progress in AI is at stake. We refer to this scenario as the post-comprehension regime. In this work, we propose Critique-Resilient Benchmarking, an adversarial framework designed to compare models even when full human understanding is infeasible. Our technique relies on the notion of critique-resilient correctness: an answer is deemed correct if no adversary has convincingly proved otherwise. Unlike standard benchmarking, humans serve as bounded verifiers and focus on localized claims, which preserves evaluation integrity beyond full comprehension of the task. Using an itemized bipartite Bradley-Terry model, we jointly rank LLMs by their ability to solve challenging tasks and to generate difficult yet solvable questions. We showcase the effectiveness of our method in the mathematical domain across eight frontier LLMs, showing that the resulting scores are stable and correlate with external capability measures. Our framework reformulates benchmarking as an adversarial generation-evaluation game in which humans serve as final adjudicators.
An End-to-end Planning Framework with Agentic LLMs and PDDL
Dec 10, 2025We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework across various domains and tasks, including the Google NaturalPlan benchmark and PlanBench, as well as planning problems like Blocksworld and the Tower of Hanoi (where LLMs are known to struggle even with small instances). Our framework can be integrated with any PDDL planning engine and validator (such as Fast Downward, LPG, POPF, VAL, and uVAL, which we have tested) and represents a significant step toward end-to-end planning aided by LLMs.
Large Language Models Miss the Multi-Agent Mark
May 27, 2025
Recent interest in Multi-Agent Systems of Large Language Models (MAS LLMs) has led to an increase in frameworks leveraging multiple LLMs to tackle complex tasks. However, much of this literature appropriates the terminology of MAS without engaging with its foundational principles. In this position paper, we highlight critical discrepancies between MAS theory and current MAS LLMs implementations, focusing on four key areas: the social aspect of agency, environment design, coordination and communication protocols, and measuring emergent behaviours. Our position is that many MAS LLMs lack multi-agent characteristics such as autonomy, social interaction, and structured environments, and often rely on oversimplified, LLM-centric architectures. The field may slow down and lose traction by revisiting problems the MAS literature has already addressed. Therefore, we systematically analyse this issue and outline associated research opportunities; we advocate for better integrating established MAS concepts and more precise terminology to avoid mischaracterisation and missed opportunities.
Language Models Are Implicitly Continuous
Apr 04, 2025Language is typically modelled with discrete sequences. However, the most successful approaches to language modelling, namely neural networks, are continuous and smooth function approximators. In this work, we show that Transformer-based language models implicitly learn to represent sentences as continuous-time functions defined over a continuous input space. This phenomenon occurs in most state-of-the-art Large Language Models (LLMs), including Llama2, Llama3, Phi3, Gemma, Gemma2, and Mistral, and suggests that LLMs reason about language in ways that fundamentally differ from humans. Our work formally extends Transformers to capture the nuances of time and space continuity in both input and output space. Our results challenge the traditional interpretation of how LLMs understand language, with several linguistic and engineering implications.
Code Simulation as a Proxy for High-order Tasks in Large Language Models
Feb 05, 2025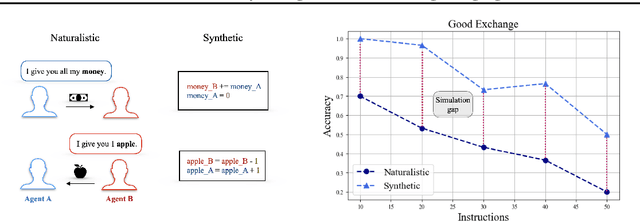


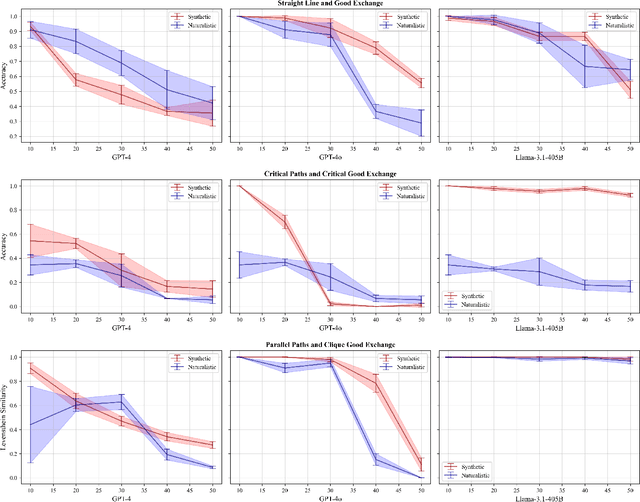
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.
Jailbreaking Large Language Models in Infinitely Many Ways
Jan 18, 2025



We discuss the "Infinitely Many Meanings" attacks (IMM), a category of jailbreaks that leverages the increasing capabilities of a model to handle paraphrases and encoded communications to bypass their defensive mechanisms. IMMs' viability pairs and grows with a model's capabilities to handle and bind the semantics of simple mappings between tokens and work extremely well in practice, posing a concrete threat to the users of the most powerful LLMs in commerce. We show how one can bypass the safeguards of the most powerful open- and closed-source LLMs and generate content that explicitly violates their safety policies. One can protect against IMMs by improving the guardrails and making them scale with the LLMs' capabilities. For two categories of attacks that are straightforward to implement, i.e., bijection and encoding, we discuss two defensive strategies, one in token and the other in embedding space. We conclude with some research questions we believe should be prioritised to enhance the defensive mechanisms of LLMs and our understanding of their safety.
Authenticated Delegation and Authorized AI Agents
Jan 16, 2025



The rapid deployment of autonomous AI agents creates urgent challenges around authorization, accountability, and access control in digital spaces. New standards are needed to know whom AI agents act on behalf of and guide their use appropriately, protecting online spaces while unlocking the value of task delegation to autonomous agents. We introduce a novel framework for authenticated, authorized, and auditable delegation of authority to AI agents, where human users can securely delegate and restrict the permissions and scope of agents while maintaining clear chains of accountability. This framework builds on existing identification and access management protocols, extending OAuth 2.0 and OpenID Connect with agent-specific credentials and metadata, maintaining compatibility with established authentication and web infrastructure. Further, we propose a framework for translating flexible, natural language permissions into auditable access control configurations, enabling robust scoping of AI agent capabilities across diverse interaction modalities. Taken together, this practical approach facilitates immediate deployment of AI agents while addressing key security and accountability concerns, working toward ensuring agentic AI systems perform only appropriate actions and providing a tool for digital service providers to enable AI agent interactions without risking harm from scalable interaction.
A Scalable Communication Protocol for Networks of Large Language Models
Oct 14, 2024



Communication is a prerequisite for collaboration. When scaling networks of AI-powered agents, communication must be versatile, efficient, and portable. These requisites, which we refer to as the Agent Communication Trilemma, are hard to achieve in large networks of agents. We introduce Agora, a meta protocol that leverages existing communication standards to make LLM-powered agents solve complex problems efficiently. In Agora, agents typically use standardised routines for frequent communications, natural language for rare communications, and LLM-written routines for everything in between. Agora sidesteps the Agent Communication Trilemma and robustly handles changes in interfaces and members, allowing unprecedented scalability with full decentralisation and minimal involvement of human beings. On large Agora networks, we observe the emergence of self-organising, fully automated protocols that achieve complex goals without human intervention.
A Notion of Complexity for Theory of Mind via Discrete World Models
Jun 16, 2024Theory of Mind (ToM) can be used to assess the capabilities of Large Language Models (LLMs) in complex scenarios where social reasoning is required. While the research community has proposed many ToM benchmarks, their hardness varies greatly, and their complexity is not well defined. This work proposes a framework to measure the complexity of ToM tasks. We quantify a problem's complexity as the number of states necessary to solve it correctly. Our complexity measure also accounts for spurious states of a ToM problem designed to make it apparently harder. We use our method to assess the complexity of five widely adopted ToM benchmarks. On top of this framework, we design a prompting technique that augments the information available to a model with a description of how the environment changes with the agents' interactions. We name this technique Discrete World Models (DWM) and show how it elicits superior performance on ToM tasks.