 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Simulation as a Proxy for High-order Tasks in Large Language Models
Feb 05, 2025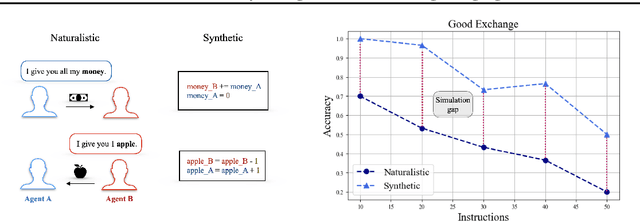


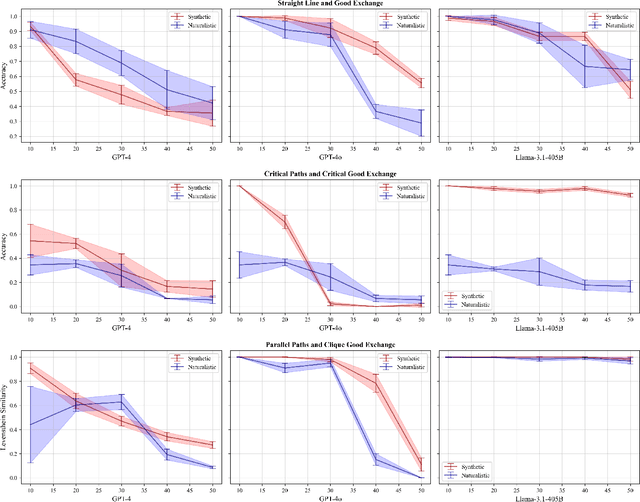
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.
A Notion of Complexity for Theory of Mind via Discrete World Models
Jun 16, 2024Theory of Mind (ToM) can be used to assess the capabilities of Large Language Models (LLMs) in complex scenarios where social reasoning is required. While the research community has proposed many ToM benchmarks, their hardness varies greatly, and their complexity is not well defined. This work proposes a framework to measure the complexity of ToM tasks. We quantify a problem's complexity as the number of states necessary to solve it correctly. Our complexity measure also accounts for spurious states of a ToM problem designed to make it apparently harder. We use our method to assess the complexity of five widely adopted ToM benchmarks. On top of this framework, we design a prompting technique that augments the information available to a model with a description of how the environment changes with the agents' interactions. We name this technique Discrete World Models (DWM) and show how it elicits superior performance on ToM tasks.
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
Feb 05, 2024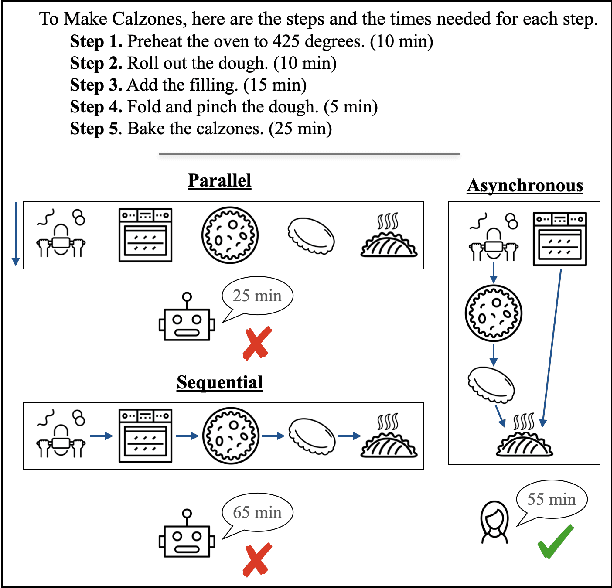



Reasoning about asynchronous plans is challenging since it requires sequential and parallel planning to optimize time costs. Can large language models (LLMs) succeed at this task? Here, we present the first large-scale study investigating this question. We find that a representative set of closed and open-source LLMs, including GPT-4 and LLaMA-2, behave poorly when not supplied with illustrations about the task-solving process in our benchmark AsyncHow. We propose a novel technique called Plan Like a Graph (PLaG) that combines graphs with natural language prompts and achieves state-of-the-art results. We show that although PLaG can boost model performance, LLMs still suffer from drastic degradation when task complexity increases, highlighting the limits of utilizing LLMs for simulating digital devices. We see our study as an exciting step towards using LLMs as efficient autonomous agents.
Code Simulation Challenges for Large Language Models
Jan 21, 2024



We investigate the extent to which Large Language Models (LLMs) can simulate the execution of computer code and algorithms. We begin by looking at straight line programs, and show that current LLMs demonstrate poor performance even with such simple programs -- performance rapidly degrades with the length of code. We then investigate the ability of LLMs to simulate programs that contain critical paths and redundant instructions. We also go beyond straight line program simulation with sorting algorithms and nested loops, and we show the computational complexity of a routine directly affects the ability of an LLM to simulate its execution. We observe that LLMs execute instructions sequentially and with a low error margin only for short programs or standard procedures. LLMs' code simulation is in tension with their pattern recognition and memorisation capabilities: on tasks where memorisation is detrimental, we propose a novel prompting method to simulate code execution line by line. Empirically, our new Chain of Simulation (CoSm) method improves on the standard Chain of Thought prompting approach by avoiding the pitfalls of memorisation.
Location retrieval using visible landmarks based qualitative place signatures
Jul 26, 2022
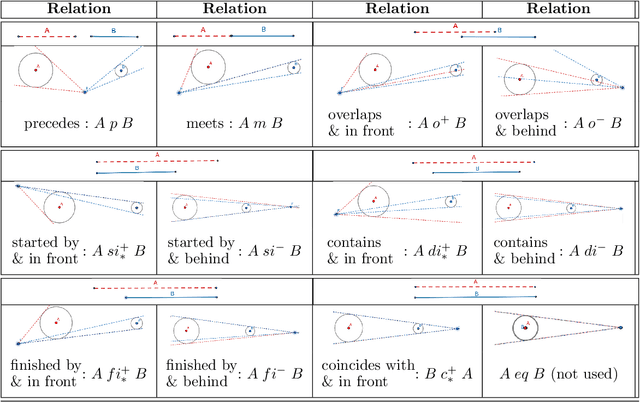
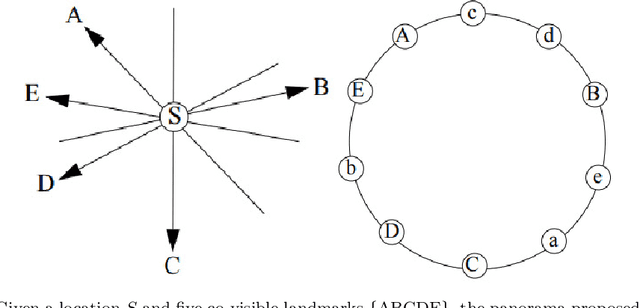
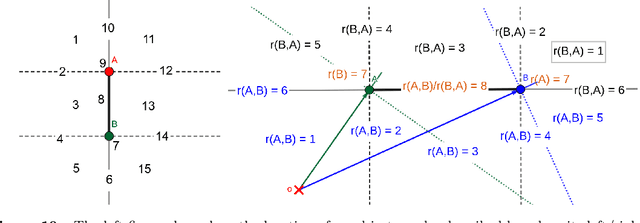
Location retrieval based on visual information is to retrieve the location of an agent (e.g. human, robot) or the area they see by comparing the observations with a certain form of representation of the environment. Existing methods generally require precise measurement and storage of the observed environment features, which may not always be robust due to the change of season, viewpoint, occlusion, etc. They are also challenging to scale up and may not be applicable for humans due to the lack of measuring/imaging devices. Considering that humans often use less precise but easily produced qualitative spatial language and high-level semantic landmarks when describing an environment, a qualitative location retrieval method is proposed in this work by describing locations/places using qualitative place signatures (QPS), defined as the perceived spatial relations between ordered pairs of co-visible landmarks from viewers' perspective. After dividing the space into place cells each with individual signatures attached, a coarse-to-fine location retrieval method is proposed to efficiently identify the possible location(s) of viewers based on their qualitative observations. The usability and effectiveness of the proposed method were evaluated using openly available landmark datasets, together with simulated observations by considering the possible perception error.