 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024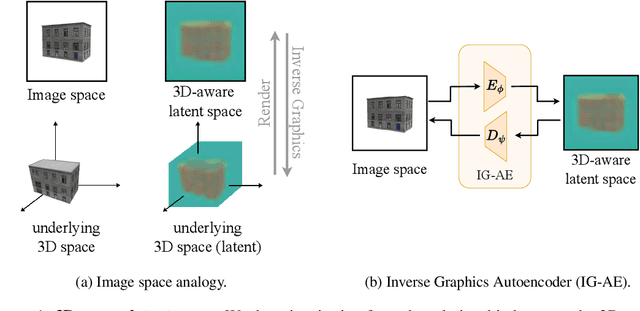
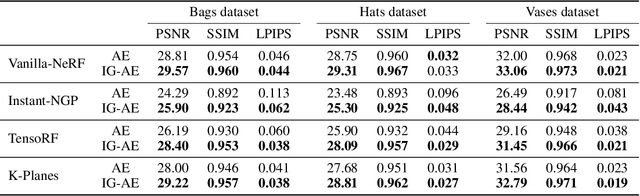


While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Location retrieval using visible landmarks based qualitative place signatures
Jul 26, 2022
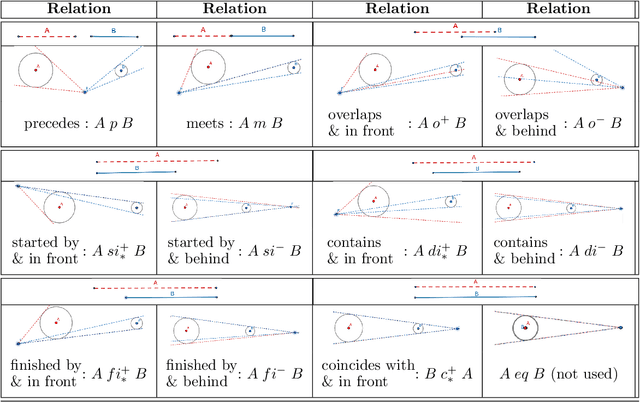
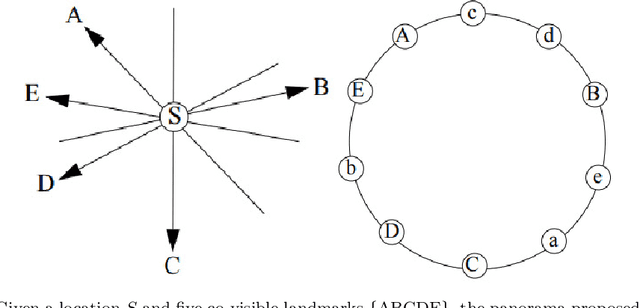
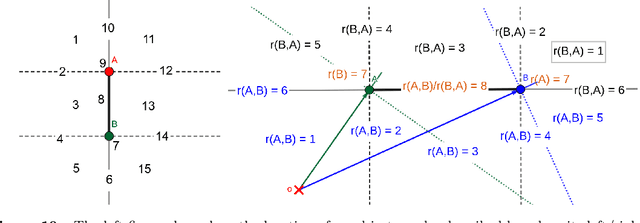
Location retrieval based on visual information is to retrieve the location of an agent (e.g. human, robot) or the area they see by comparing the observations with a certain form of representation of the environment. Existing methods generally require precise measurement and storage of the observed environment features, which may not always be robust due to the change of season, viewpoint, occlusion, etc. They are also challenging to scale up and may not be applicable for humans due to the lack of measuring/imaging devices. Considering that humans often use less precise but easily produced qualitative spatial language and high-level semantic landmarks when describing an environment, a qualitative location retrieval method is proposed in this work by describing locations/places using qualitative place signatures (QPS), defined as the perceived spatial relations between ordered pairs of co-visible landmarks from viewers' perspective. After dividing the space into place cells each with individual signatures attached, a coarse-to-fine location retrieval method is proposed to efficiently identify the possible location(s) of viewers based on their qualitative observations. The usability and effectiveness of the proposed method were evaluated using openly available landmark datasets, together with simulated observations by considering the possible perception error.
Semantic Signatures for Large-scale Visual Localization
May 07, 2020
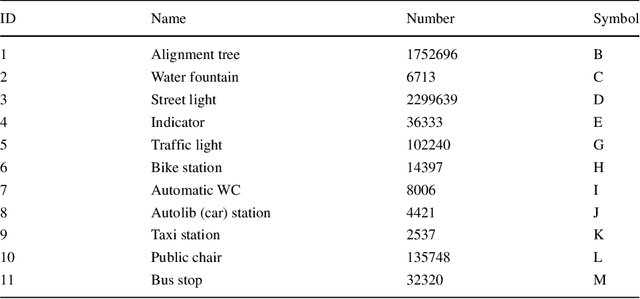
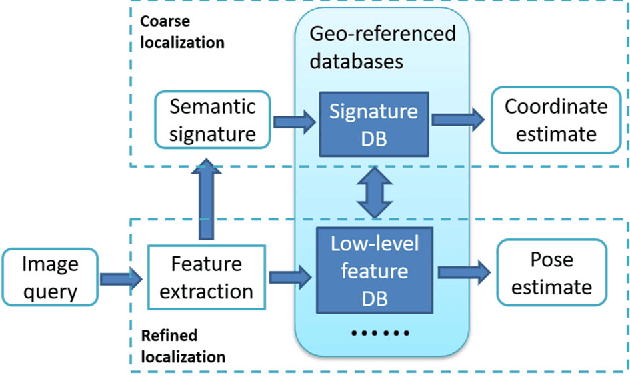
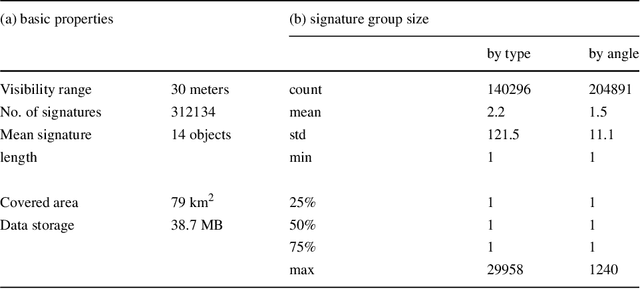
Visual localization is a useful alternative to standard localization techniques. It works by utilizing cameras. In a typical scenario, features are extracted from captured images and compared with geo-referenced databases. Location information is then inferred from the matching results. Conventional schemes mainly use low-level visual features. These approaches offer good accuracy but suffer from scalability issues. In order to assist localization in large urban areas, this work explores a different path by utilizing high-level semantic information. It is found that object information in a street view can facilitate localization. A novel descriptor scheme called "semantic signature" is proposed to summarize this information. A semantic signature consists of type and angle information of visible objects at a spatial location. Several metrics and protocols are proposed for signature comparison and retrieval. They illustrate different trade-offs between accuracy and complexity. Extensive simulation results confirm the potential of the proposed scheme in large-scale applications. This paper is an extended version of a conference paper in CBMI'18. A more efficient retrieval protocol is presented with additional experiment results.
* 12 pages, 22 figures, submitted to Multimedia Tools and Applications