 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
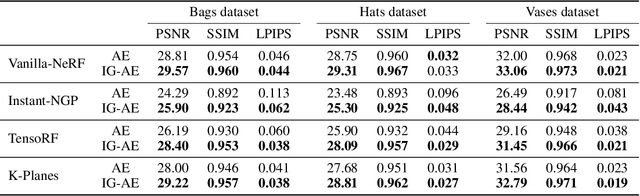
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024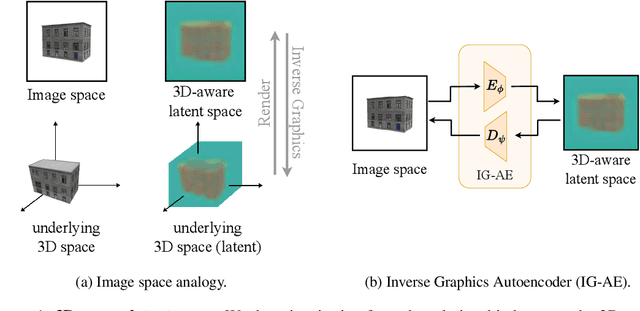


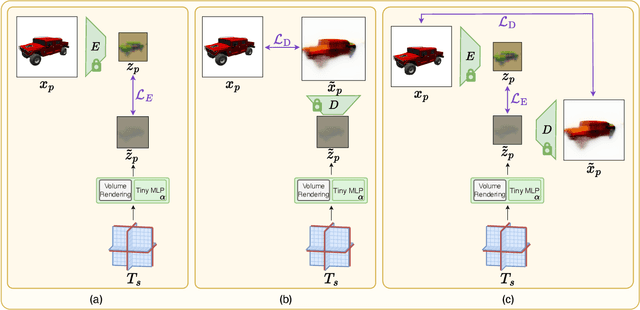
While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024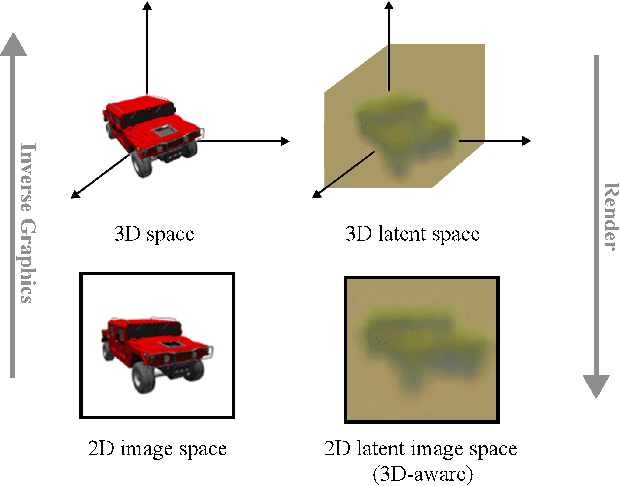
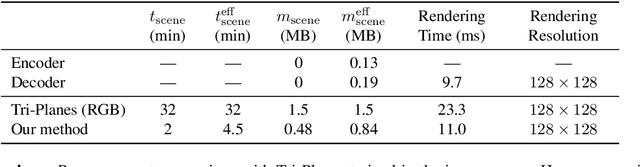

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
3DGEN: A GAN-based approach for generating novel 3D models from image data
Dec 13, 2023



The recent advances in text and image synthesis show a great promise for the future of generative models in creative fields. However, a less explored area is the one of 3D model generation, with a lot of potential applications to game design, video production, and physical product design. In our paper, we present 3DGEN, a model that leverages the recent work on both Neural Radiance Fields for object reconstruction and GAN-based image generation. We show that the proposed architecture can generate plausible meshes for objects of the same category as the training images and compare the resulting meshes with the state-of-the-art baselines, leading to visible uplifts in generation quality.
EvE: Exploiting Generative Priors for Radiance Field Enrichment
Dec 01, 2023



Modeling large-scale scenes from unconstrained image collections in-the-wild has proven to be a major challenge in computer vision. Existing methods tackling in-the-wild neural rendering operate in a closed-world setting, where knowledge is limited to a scene's captured images within a training set. We propose EvE, which is, to the best of our knowledge, the first method leveraging generative priors to improve in-the-wild scene modeling. We employ pre-trained generative networks to enrich K-Planes representations with extrinsic knowledge. To this end, we define an alternating training procedure to conduct optimization guidance of K-Planes trained on the training set. We carry out extensive experiments and verify the merit of our method on synthetic data as well as real tourism photo collections. EvE enhances rendered scenes with richer details and outperforms the state of the art on the task of novel view synthesis in-the-wild. Our project page can be found at https://eve-nvs.github.io .