 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Learning to Reason Works Because It Is More Pessimistic Than You Think
May 27, 2026Large scale reinforcement learning has become a central tool for improving reasoning in large language models. At this scale, generation is often lagged or asynchronous, so updates are performed on data collected by older policies. This makes learning inherently off-policy. Most existing approaches nevertheless remain rooted in PPO-style trust-region objectives, treating training as approximately on-policy and using importance weights to correct distribution mismatch. These corrections can introduce high variance, destabilize optimization, and accelerate entropy collapse. Recent work suggests an alternative: rather than correcting the mismatch, one can embrace off-policy data and remove importance weights, often yielding stronger algorithms. In this paper, we provide an intuitive construction of off-policy objectives that include successful off-policy objectives and show that their effectiveness can be understood through implicit pessimism: they optimize toward target policies that are more conservative than their nominal objectives suggest. This perspective explains why some particular implementation choices improve stability: they implicitly control the effective target distribution. We then propose a principled modification that stabilize this induced distribution and improve off-policy learning.
SphericalDreamer: Generating Navigable Immersive 3D Worlds with Panorama Fusion
May 19, 2026The generation of immersive and navigable 3D environments is increasingly prevalent with the growing adoption of virtual reality and 3D content. However, recent methods face a fundamental limitation: they cannot produce 3D worlds that simultaneously (i) are navigable over long-range spatial extents and (ii) cover the complete omnidirectional field of view ($360^\circ$ horizontally and $180^\circ$ vertically). To address this challenge, we introduce SphericalDreamer, a method for generating fully immersive and long-range 3D outdoor environments from textual prompts. Our approach is built on the generation of multiple panoramic images, which are subsequently lifted into 3D and fused together while maintaining visual and geometric consistency. SphericalDreamer produces highly detailed, fully immersive 3D environments, while substantially improving scale and navigability compared to prior approaches.
Scaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024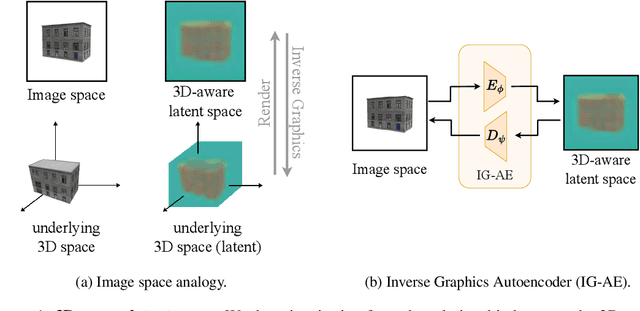
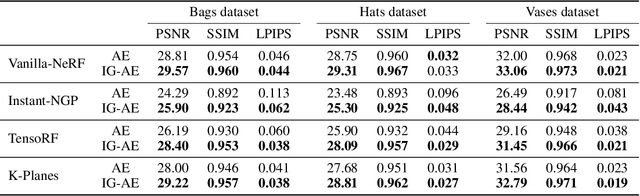


While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024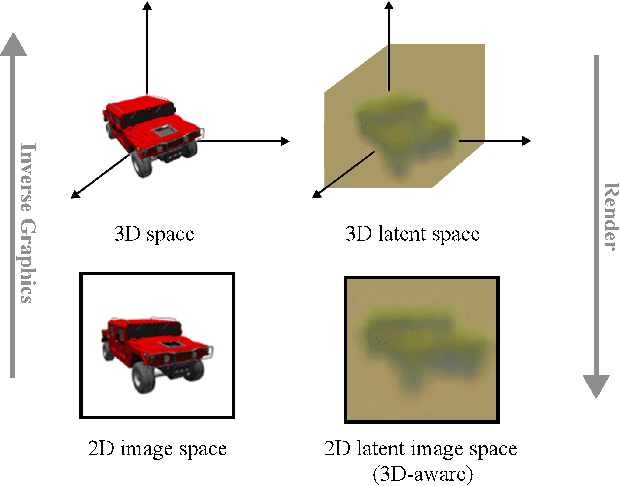
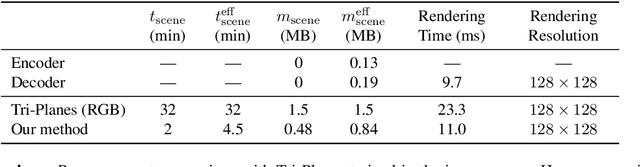
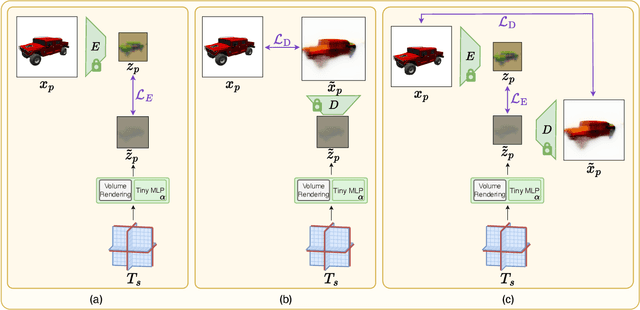

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
3DGEN: A GAN-based approach for generating novel 3D models from image data
Dec 13, 2023



The recent advances in text and image synthesis show a great promise for the future of generative models in creative fields. However, a less explored area is the one of 3D model generation, with a lot of potential applications to game design, video production, and physical product design. In our paper, we present 3DGEN, a model that leverages the recent work on both Neural Radiance Fields for object reconstruction and GAN-based image generation. We show that the proposed architecture can generate plausible meshes for objects of the same category as the training images and compare the resulting meshes with the state-of-the-art baselines, leading to visible uplifts in generation quality.
AdBooster: Personalized Ad Creative Generation using Stable Diffusion Outpainting
Sep 08, 2023

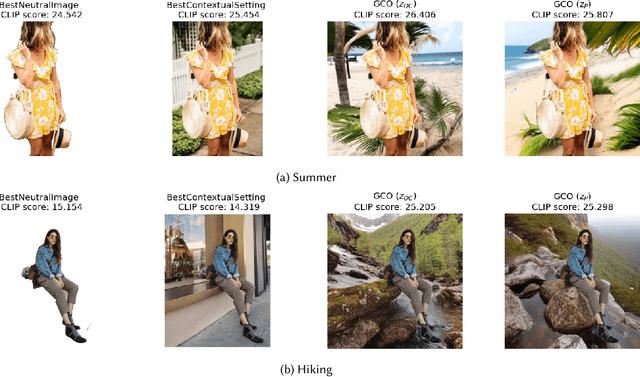
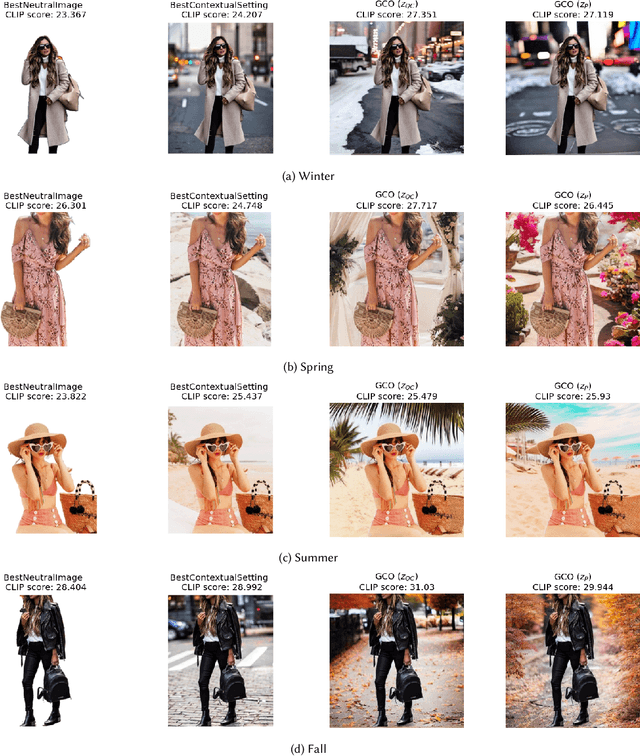
In digital advertising, the selection of the optimal item (recommendation) and its best creative presentation (creative optimization) have traditionally been considered separate disciplines. However, both contribute significantly to user satisfaction, underpinning our assumption that it relies on both an item's relevance and its presentation, particularly in the case of visual creatives. In response, we introduce the task of {\itshape Generative Creative Optimization (GCO)}, which proposes the use of generative models for creative generation that incorporate user interests, and {\itshape AdBooster}, a model for personalized ad creatives based on the Stable Diffusion outpainting architecture. This model uniquely incorporates user interests both during fine-tuning and at generation time. To further improve AdBooster's performance, we also introduce an automated data augmentation pipeline. Through our experiments on simulated data, we validate AdBooster's effectiveness in generating more relevant creatives than default product images, showing its potential of enhancing user engagement.
Offline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
A Scalable Probabilistic Model for Reward Optimizing Slate Recommendation
Aug 10, 2022
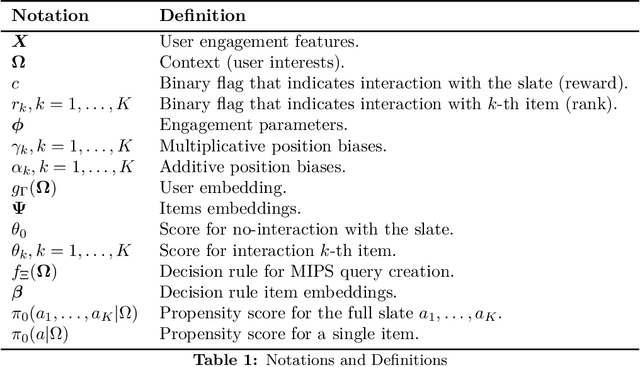
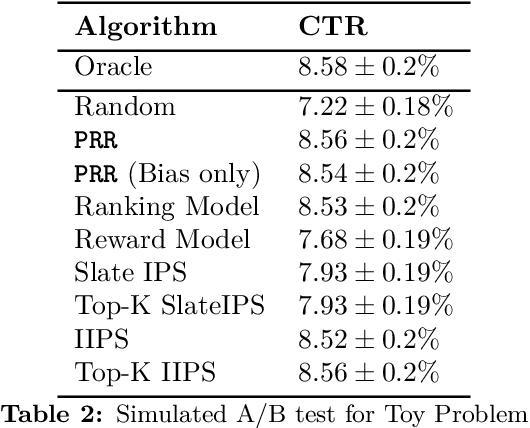
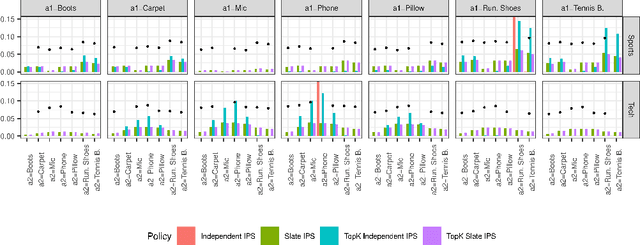
We introduce Probabilistic Rank and Reward model (PRR), a scalable probabilistic model for personalized slate recommendation. Our model allows state-of-the-art estimation of user interests in the following ubiquitous recommender system scenario: A user is shown a slate of K recommendations and the user chooses at most one of these K items. It is the goal of the recommender system to find the K items of most interest to a user in order to maximize the probability that the user interacts with the slate. Our contribution is to show that we can learn more effectively the probability of the recommendations being successful by combining the reward - whether the slate was clicked or not - and the rank - the item on the slate that was selected. Our method learns more efficiently than bandit methods that use only the reward, and user preference methods that use only the rank. It also provides similar or better estimation performance to independent inverse-propensity-score methods and is far more scalable. Our method is state of the art in terms of both speed and accuracy on massive datasets with up to 1 million items. Finally, our method allows fast delivery of recommendations powered by maximum inner product search (MIPS), making it suitable in extremely low latency domains such as computational advertising.
What Users Want? WARHOL: A Generative Model for Recommendation
Sep 02, 2021


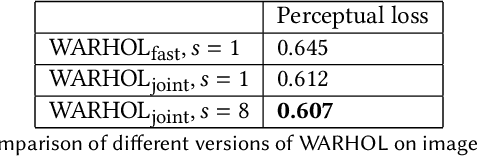
Current recommendation approaches help online merchants predict, for each visiting user, which subset of their existing products is the most relevant. However, besides being interested in matching users with existing products, merchants are also interested in understanding their users' underlying preferences. This could indeed help them produce or acquire better matching products in the future. We argue that existing recommendation models cannot directly be used to predict the optimal combination of features that will make new products serve better the needs of the target audience. To tackle this, we turn to generative models, which allow us to learn explicitly distributions over product feature combinations both in text and visual space. We develop WARHOL, a product generation and recommendation architecture that takes as input past user shopping activity and generates relevant textual and visual descriptions of novel products. We show that WARHOL can approach the performance of state-of-the-art recommendation models, while being able to generate entirely new products that are relevant to the given user profiles.