 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast 3D point clouds retrieval for Large-scale 3D Place Recognition
Feb 28, 2025Retrieval in 3D point clouds is a challenging task that consists in retrieving the most similar point clouds to a given query within a reference of 3D points. Current methods focus on comparing descriptors of point clouds in order to identify similar ones. Due to the complexity of this latter step, here we focus on the acceleration of the retrieval by adapting the Differentiable Search Index (DSI), a transformer-based approach initially designed for text information retrieval, for 3D point clouds retrieval. Our approach generates 1D identifiers based on the point descriptors, enabling direct retrieval in constant time. To adapt DSI to 3D data, we integrate Vision Transformers to map descriptors to these identifiers while incorporating positional and semantic encoding. The approach is evaluated for place recognition on a public benchmark comparing its retrieval capabilities against state-of-the-art methods, in terms of quality and speed of returned point clouds.
Scaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024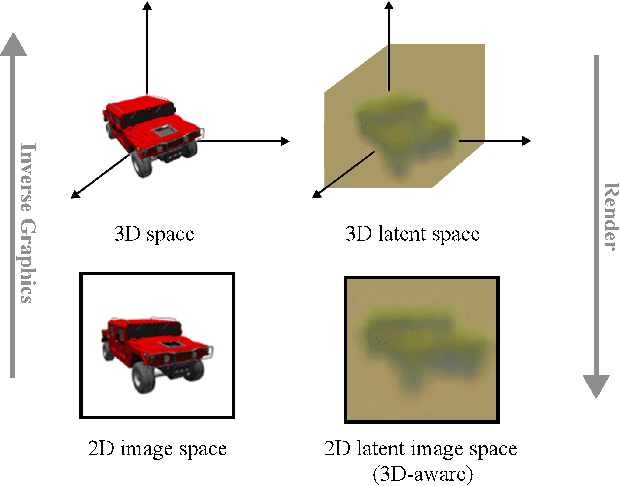
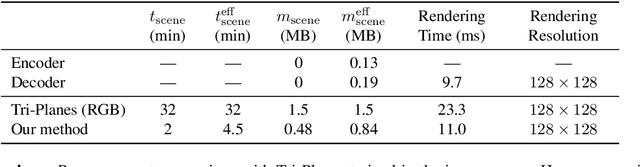
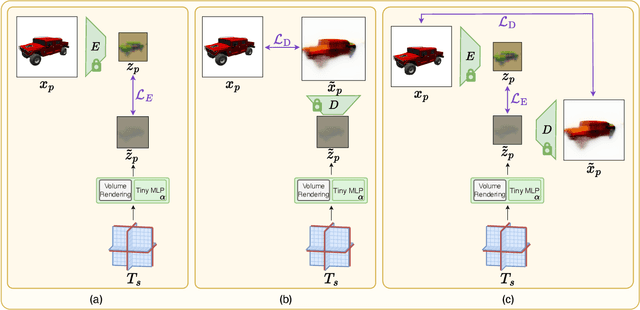

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
EvE: Exploiting Generative Priors for Radiance Field Enrichment
Dec 01, 2023



Modeling large-scale scenes from unconstrained image collections in-the-wild has proven to be a major challenge in computer vision. Existing methods tackling in-the-wild neural rendering operate in a closed-world setting, where knowledge is limited to a scene's captured images within a training set. We propose EvE, which is, to the best of our knowledge, the first method leveraging generative priors to improve in-the-wild scene modeling. We employ pre-trained generative networks to enrich K-Planes representations with extrinsic knowledge. To this end, we define an alternating training procedure to conduct optimization guidance of K-Planes trained on the training set. We carry out extensive experiments and verify the merit of our method on synthetic data as well as real tourism photo collections. EvE enhances rendered scenes with richer details and outperforms the state of the art on the task of novel view synthesis in-the-wild. Our project page can be found at https://eve-nvs.github.io .
Connecting Images through Time and Sources: Introducing Low-data, Heterogeneous Instance Retrieval
Mar 19, 2021
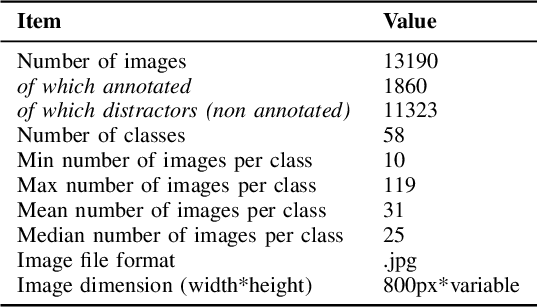

With impressive results in applications relying on feature learning, deep learning has also blurred the line between algorithm and data. Pick a training dataset, pick a backbone network for feature extraction, and voil\`a ; this usually works for a variety of use cases. But the underlying hypothesis that there exists a training dataset matching the use case is not always met. Moreover, the demand for interconnections regardless of the variations of the content calls for increasing generalization and robustness in features. An interesting application characterized by these problematics is the connection of historical and cultural databases of images. Through the seemingly simple task of instance retrieval, we propose to show that it is not trivial to pick features responding well to a panel of variations and semantic content. Introducing a new enhanced version of the Alegoria benchmark, we compare descriptors using the detailed annotations. We further give insights about the core problems in instance retrieval, testing four state-of-the-art additional techniques to increase performance.
Unifying Remote Sensing Image Retrieval and Classification with Robust Fine-tuning
Feb 26, 2021

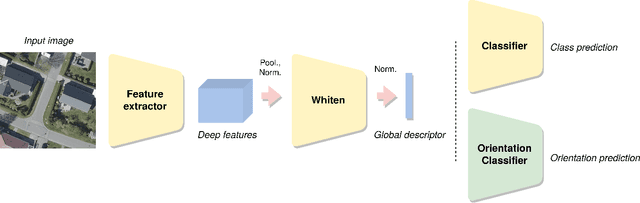
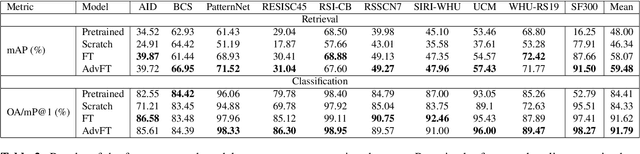
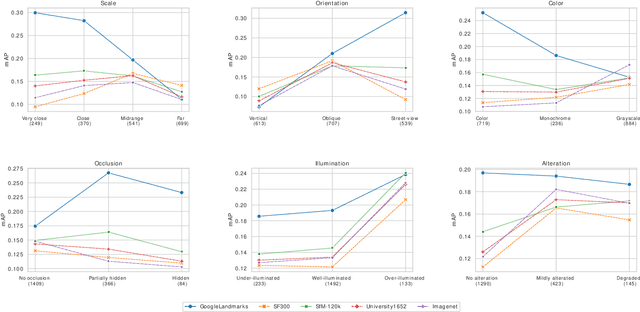
Advances in high resolution remote sensing image analysis are currently hampered by the difficulty of gathering enough annotated data for training deep learning methods, giving rise to a variety of small datasets and associated dataset-specific methods. Moreover, typical tasks such as classification and retrieval lack a systematic evaluation on standard benchmarks and training datasets, which make it hard to identify durable and generalizable scientific contributions. We aim at unifying remote sensing image retrieval and classification with a new large-scale training and testing dataset, SF300, including both vertical and oblique aerial images and made available to the research community, and an associated fine-tuning method. We additionally propose a new adversarial fine-tuning method for global descriptors. We show that our framework systematically achieves a boost of retrieval and classification performance on nine different datasets compared to an ImageNet pretrained baseline, with currently no other method to compare to.
Challenging deep image descriptors for retrieval in heterogeneous iconographic collections
Sep 19, 2019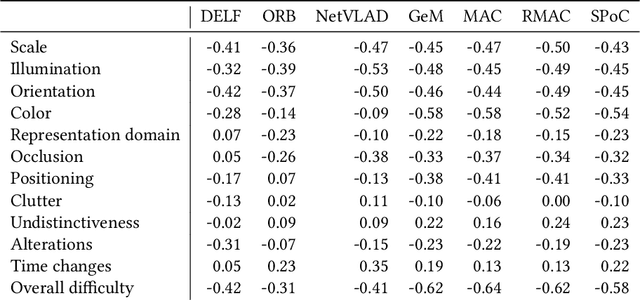
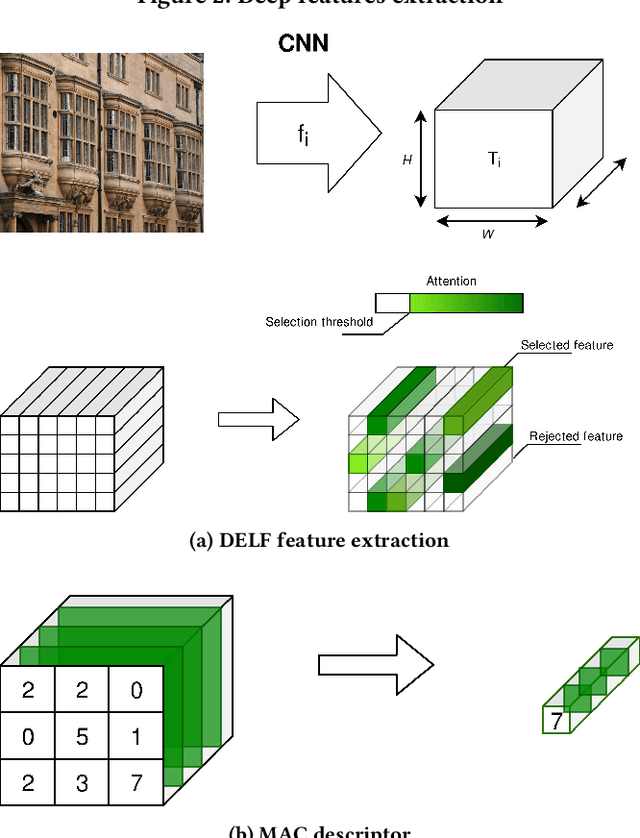

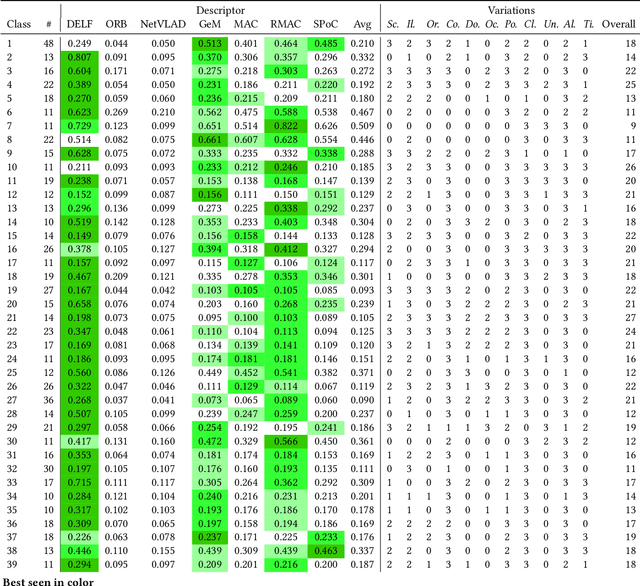
This article proposes to study the behavior of recent and efficient state-of-the-art deep-learning based image descriptors for content-based image retrieval, facing a panel of complex variations appearing in heterogeneous image datasets, in particular in cultural collections that may involve multi-source, multi-date and multi-view Permission to make digital