 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Chain Estimation with In-Context Learning
Aug 05, 2025We investigate the capacity of transformers to learn algorithms involving their context while solely being trained using next token prediction. We set up Markov chains with random transition matrices and we train transformers to predict the next token. Matrices used during training and test are different and we show that there is a threshold in transformer size and in training set size above which the model is able to learn to estimate the transition probabilities from its context instead of memorizing the training patterns. Additionally, we show that more involved encoding of the states enables more robust prediction for Markov chains with structures different than those seen during training.
Scaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024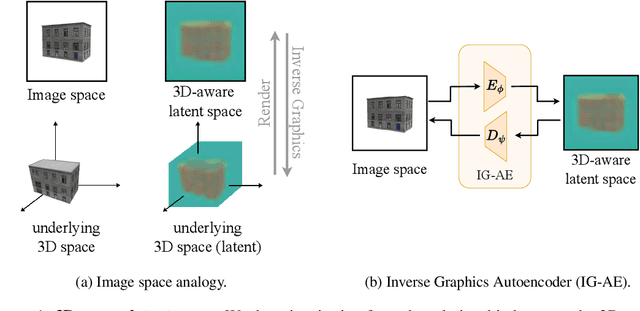
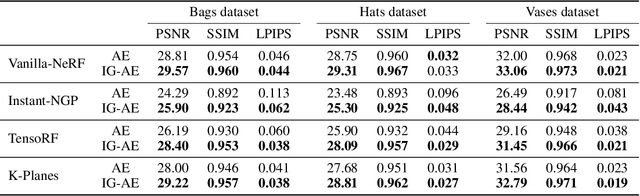


While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024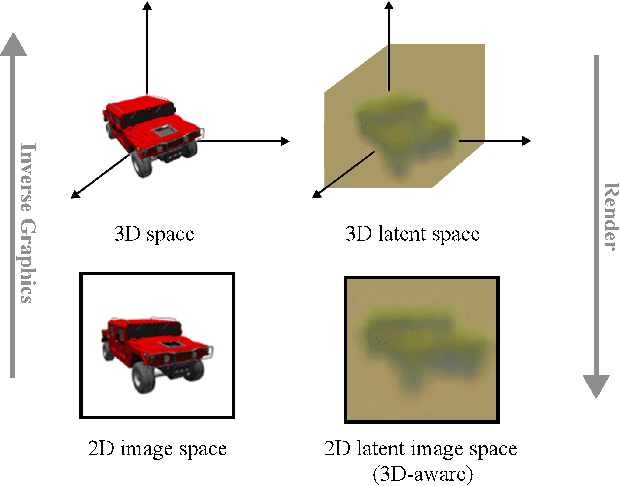
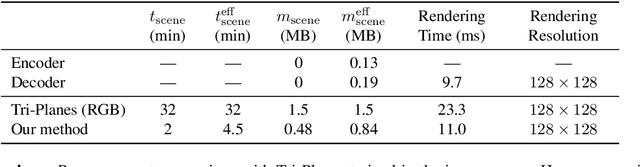
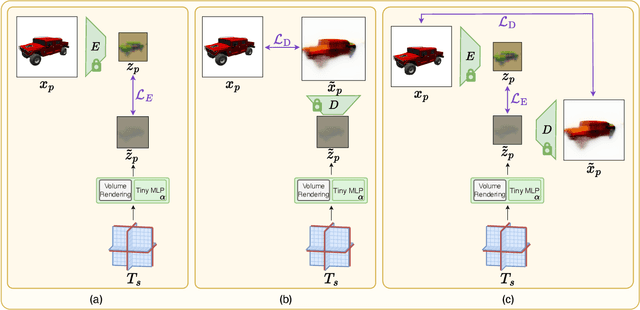

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
EvE: Exploiting Generative Priors for Radiance Field Enrichment
Dec 01, 2023



Modeling large-scale scenes from unconstrained image collections in-the-wild has proven to be a major challenge in computer vision. Existing methods tackling in-the-wild neural rendering operate in a closed-world setting, where knowledge is limited to a scene's captured images within a training set. We propose EvE, which is, to the best of our knowledge, the first method leveraging generative priors to improve in-the-wild scene modeling. We employ pre-trained generative networks to enrich K-Planes representations with extrinsic knowledge. To this end, we define an alternating training procedure to conduct optimization guidance of K-Planes trained on the training set. We carry out extensive experiments and verify the merit of our method on synthetic data as well as real tourism photo collections. EvE enhances rendered scenes with richer details and outperforms the state of the art on the task of novel view synthesis in-the-wild. Our project page can be found at https://eve-nvs.github.io .
Latent reweighting, an almost free improvement for GANs
Oct 19, 2021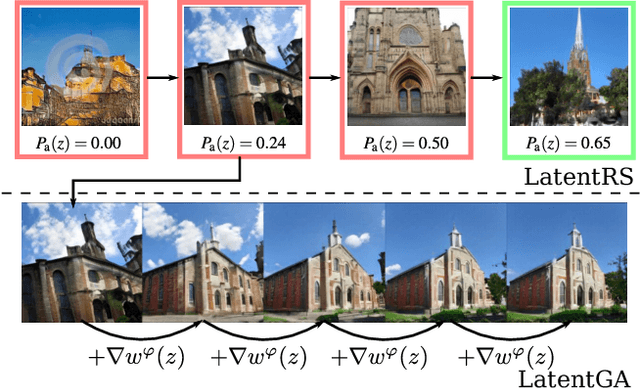
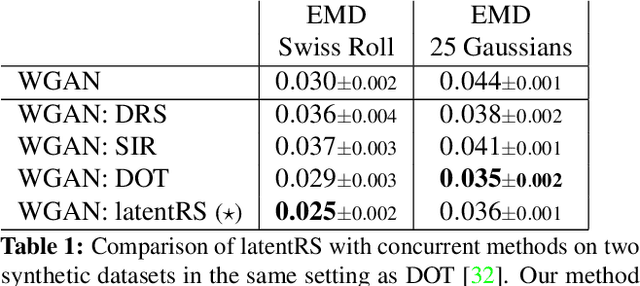
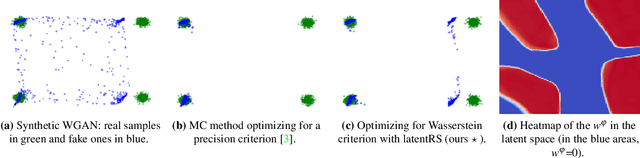
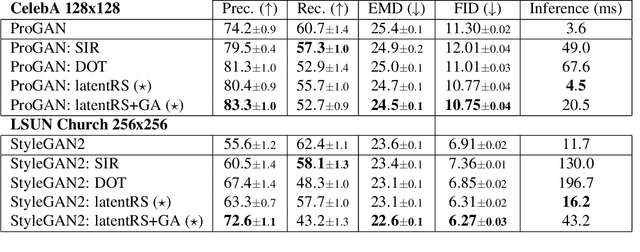
Standard formulations of GANs, where a continuous function deforms a connected latent space, have been shown to be misspecified when fitting different classes of images. In particular, the generator will necessarily sample some low-quality images in between the classes. Rather than modifying the architecture, a line of works aims at improving the sampling quality from pre-trained generators at the expense of increased computational cost. Building on this, we introduce an additional network to predict latent importance weights and two associated sampling methods to avoid the poorest samples. This idea has several advantages: 1) it provides a way to inject disconnectedness into any GAN architecture, 2) since the rejection happens in the latent space, it avoids going through both the generator and the discriminator, saving computation time, 3) this importance weights formulation provides a principled way to reduce the Wasserstein's distance to the target distribution. We demonstrate the effectiveness of our method on several datasets, both synthetic and high-dimensional.
Learning disconnected manifolds: a no GANs land
Jun 22, 2020
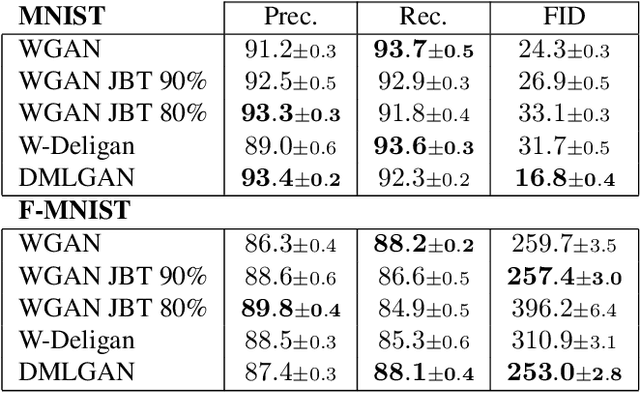
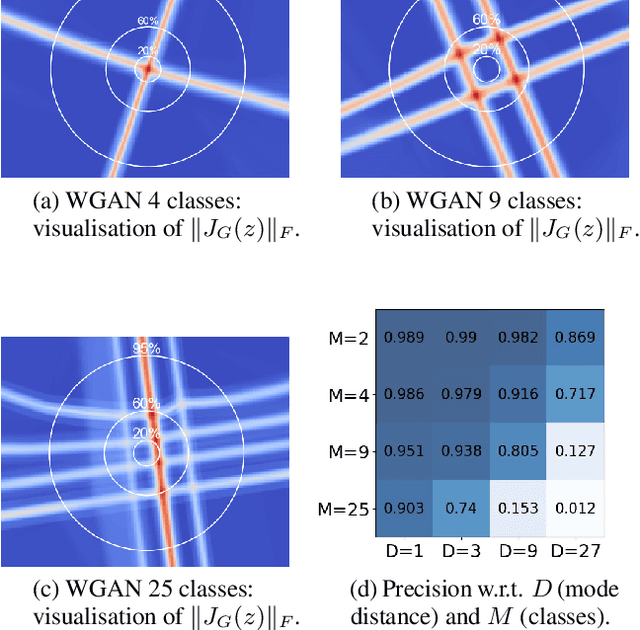
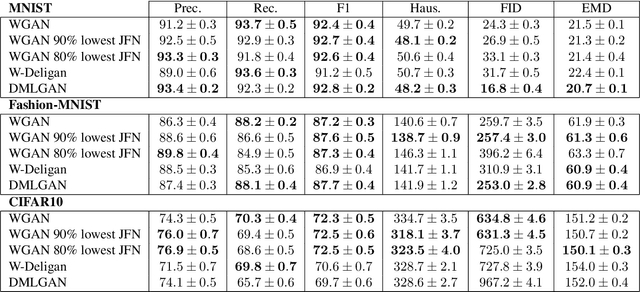
Typical architectures of Generative AdversarialNetworks make use of a unimodal latent distribution transformed by a continuous generator. Consequently, the modeled distribution always has connected support which is cumbersome when learning a disconnected set of manifolds. We formalize this problem by establishing a no free lunch theorem for the disconnected manifold learning stating an upper bound on the precision of the targeted distribution. This is done by building on the necessary existence of a low-quality region where the generator continuously samples data between two disconnected modes. Finally, we derive a rejection sampling method based on the norm of generators Jacobian and show its efficiency on several generators including BigGAN.
End-to-end optimization of goal-driven and visually grounded dialogue systems
Mar 15, 2017



End-to-end design of dialogue systems has recently become a popular research topic thanks to powerful tools such as encoder-decoder architectures for sequence-to-sequence learning. Yet, most current approaches cast human-machine dialogue management as a supervised learning problem, aiming at predicting the next utterance of a participant given the full history of the dialogue. This vision is too simplistic to render the intrinsic planning problem inherent to dialogue as well as its grounded nature, making the context of a dialogue larger than the sole history. This is why only chit-chat and question answering tasks have been addressed so far using end-to-end architectures. In this paper, we introduce a Deep Reinforcement Learning method to optimize visually grounded task-oriented dialogues, based on the policy gradient algorithm. This approach is tested on a dataset of 120k dialogues collected through Mechanical Turk and provides encouraging results at solving both the problem of generating natural dialogues and the task of discovering a specific object in a complex picture.
Hybrid Collaborative Filtering with Autoencoders
Jul 19, 2016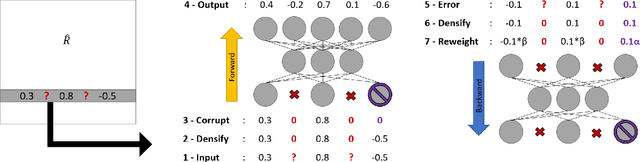
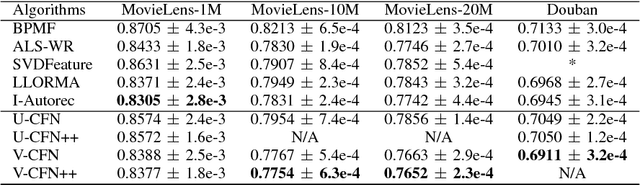
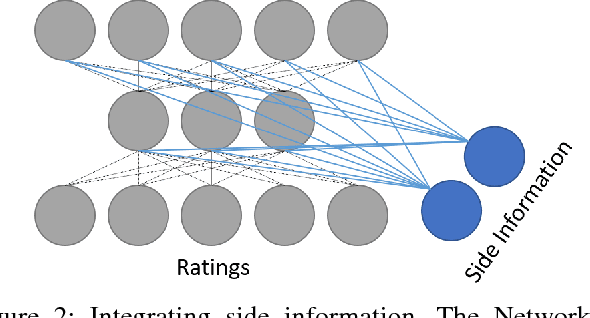

Collaborative Filtering aims at exploiting the feedback of users to provide personalised recommendations. Such algorithms look for latent variables in a large sparse matrix of ratings. They can be enhanced by adding side information to tackle the well-known cold start problem. While Neu-ral Networks have tremendous success in image and speech recognition, they have received less attention in Collaborative Filtering. This is all the more surprising that Neural Networks are able to discover latent variables in large and heterogeneous datasets. In this paper, we introduce a Collaborative Filtering Neural network architecture aka CFN which computes a non-linear Matrix Factorization from sparse rating inputs and side information. We show experimentally on the MovieLens and Douban dataset that CFN outper-forms the state of the art and benefits from side information. We provide an implementation of the algorithm as a reusable plugin for Torch, a popular Neural Network framework.