 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Preference Optimization as Probabilistic Inference
Oct 05, 2024
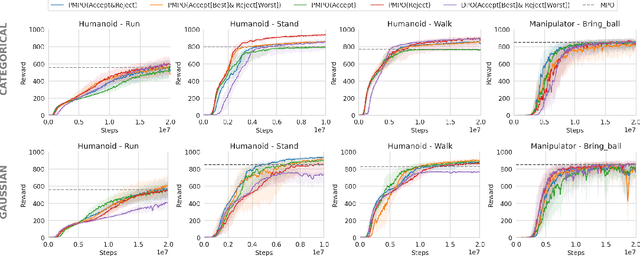
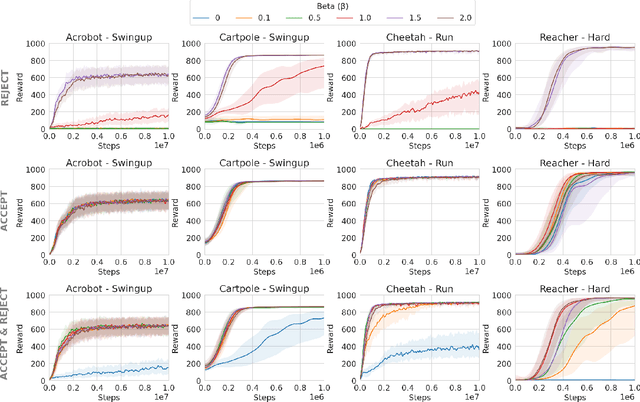
Existing preference optimization methods are mainly designed for directly learning from human feedback with the assumption that paired examples (preferred vs. dis-preferred) are available. In contrast, we propose a method that can leverage unpaired preferred or dis-preferred examples, and works even when only one type of feedback (positive or negative) is available. This flexibility allows us to apply it in scenarios with varying forms of feedback and models, including training generative language models based on human feedback as well as training policies for sequential decision-making problems, where learned (value) functions are available. Our approach builds upon the probabilistic framework introduced in (Dayan and Hinton, 1997), which proposes to use expectation-maximization (EM) to directly optimize the probability of preferred outcomes (as opposed to classic expected reward maximization). To obtain a practical algorithm, we identify and address a key limitation in current EM-based methods: when applied to preference optimization, they solely maximize the likelihood of preferred examples, while neglecting dis-preferred samples. We show how one can extend EM algorithms to explicitly incorporate dis-preferred outcomes, leading to a novel, theoretically grounded, preference optimization algorithm that offers an intuitive and versatile way to learn from both positive and negative feedback.
Building Math Agents with Multi-Turn Iterative Preference Learning
Sep 04, 2024



Recent studies have shown that large language models' (LLMs) mathematical problem-solving capabilities can be enhanced by integrating external tools, such as code interpreters, and employing multi-turn Chain-of-Thought (CoT) reasoning. While current methods focus on synthetic data generation and Supervised Fine-Tuning (SFT), this paper studies the complementary direct preference learning approach to further improve model performance. However, existing direct preference learning algorithms are originally designed for the single-turn chat task, and do not fully address the complexities of multi-turn reasoning and external tool integration required for tool-integrated mathematical reasoning tasks. To fill in this gap, we introduce a multi-turn direct preference learning framework, tailored for this context, that leverages feedback from code interpreters and optimizes trajectory-level preferences. This framework includes multi-turn DPO and multi-turn KTO as specific implementations. The effectiveness of our framework is validated through training of various language models using an augmented prompt set from the GSM8K and MATH datasets. Our results demonstrate substantial improvements: a supervised fine-tuned Gemma-1.1-it-7B model's performance increased from 77.5% to 83.9% on GSM8K and from 46.1% to 51.2% on MATH. Similarly, a Gemma-2-it-9B model improved from 84.1% to 86.3% on GSM8K and from 51.0% to 54.5% on MATH.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Multi-turn Reinforcement Learning from Preference Human Feedback
May 23, 2024



Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Human Alignment of Large Language Models through Online Preference Optimisation
Mar 13, 2024



Ensuring alignment of language models' outputs with human preferences is critical to guarantee a useful, safe, and pleasant user experience. Thus, human alignment has been extensively studied recently and several methods such as Reinforcement Learning from Human Feedback (RLHF), Direct Policy Optimisation (DPO) and Sequence Likelihood Calibration (SLiC) have emerged. In this paper, our contribution is two-fold. First, we show the equivalence between two recent alignment methods, namely Identity Policy Optimisation (IPO) and Nash Mirror Descent (Nash-MD). Second, we introduce a generalisation of IPO, named IPO-MD, that leverages the regularised sampling approach proposed by Nash-MD. This equivalence may seem surprising at first sight, since IPO is an offline method whereas Nash-MD is an online method using a preference model. However, this equivalence can be proven when we consider the online version of IPO, that is when both generations are sampled by the online policy and annotated by a trained preference model. Optimising the IPO loss with such a stream of data becomes then equivalent to finding the Nash equilibrium of the preference model through self-play. Building on this equivalence, we introduce the IPO-MD algorithm that generates data with a mixture policy (between the online and reference policy) similarly as the general Nash-MD algorithm. We compare online-IPO and IPO-MD to different online versions of existing losses on preference data such as DPO and SLiC on a summarisation task.
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Feb 08, 2024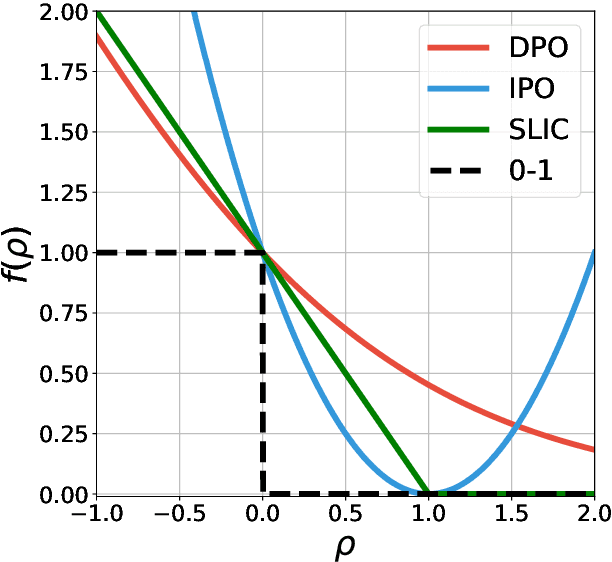
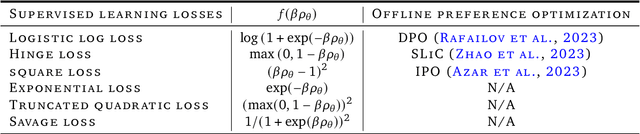
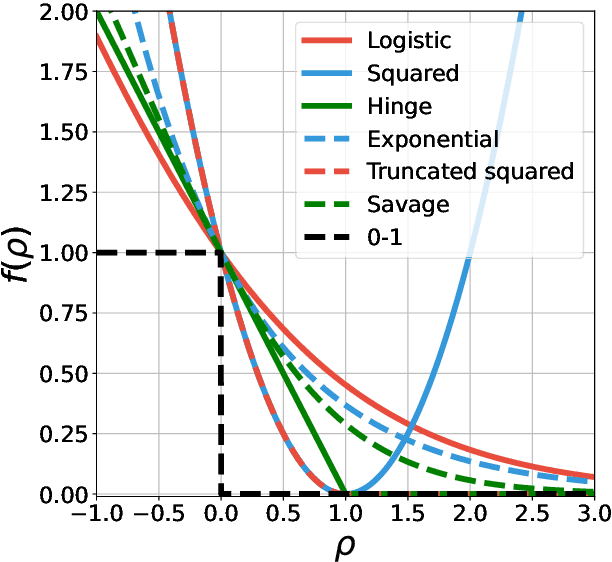
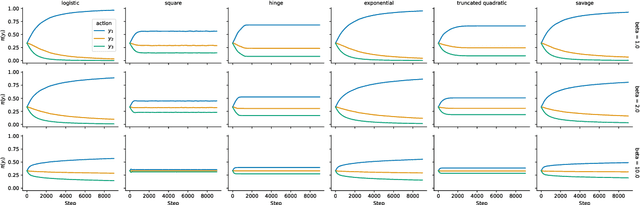
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
Direct Language Model Alignment from Online AI Feedback
Feb 07, 2024



Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate reward model. However, the preference datasets used in DAP methods are usually collected ahead of training and never updated, thus the feedback is purely offline. Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy. In this study, we posit that online feedback is key and improves DAP methods. Our method, online AI feedback (OAIF), uses an LLM as annotator: on each training iteration, we sample two responses from the current model and prompt the LLM annotator to choose which one is preferred, thus providing online feedback. Despite its simplicity, we demonstrate via human evaluation in several tasks that OAIF outperforms both offline DAP and RLHF methods. We further show that the feedback leveraged in OAIF is easily controllable, via instruction prompts to the LLM annotator.
Nash Learning from Human Feedback
Dec 06, 2023



Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.