 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Language Model Alignment from Online AI Feedback
Feb 07, 2024



Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate reward model. However, the preference datasets used in DAP methods are usually collected ahead of training and never updated, thus the feedback is purely offline. Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy. In this study, we posit that online feedback is key and improves DAP methods. Our method, online AI feedback (OAIF), uses an LLM as annotator: on each training iteration, we sample two responses from the current model and prompt the LLM annotator to choose which one is preferred, thus providing online feedback. Despite its simplicity, we demonstrate via human evaluation in several tasks that OAIF outperforms both offline DAP and RLHF methods. We further show that the feedback leveraged in OAIF is easily controllable, via instruction prompts to the LLM annotator.
Beyond Task Performance: Evaluating and Reducing the Flaws of Large Multimodal Models with In-Context Learning
Oct 01, 2023Following the success of Large Language Models (LLMs), Large Multimodal Models (LMMs), such as the Flamingo model and its subsequent competitors, have started to emerge as natural steps towards generalist agents. However, interacting with recent LMMs reveals major limitations that are hardly captured by the current evaluation benchmarks. Indeed, task performances (e.g., VQA accuracy) alone do not provide enough clues to understand their real capabilities, limitations, and to which extent such models are aligned to human expectations. To refine our understanding of those flaws, we deviate from the current evaluation paradigm and propose the EvALign-ICL framework, in which we (1) evaluate 8 recent open-source LMMs (based on the Flamingo architecture such as OpenFlamingo and IDEFICS) on 5 different axes; hallucinations, abstention, compositionality, explainability and instruction following. Our evaluation on these axes reveals major flaws in LMMs. To efficiently address these problems, and inspired by the success of in-context learning (ICL) in LLMs, (2) we explore ICL as a solution and study how it affects these limitations. Based on our ICL study, (3) we push ICL further and propose new multimodal ICL approaches such as; Multitask-ICL, Chain-of-Hindsight-ICL, and Self-Correcting-ICL. Our findings are as follows; (1) Despite their success, LMMs have flaws that remain unsolved with scaling alone. (2) The effect of ICL on LMMs flaws is nuanced; despite its effectiveness for improved explainability, abstention, and instruction following, ICL does not improve compositional abilities, and actually even amplifies hallucinations. (3) The proposed ICL variants are promising as post-hoc approaches to efficiently tackle some of those flaws. The code is available here: https://evalign-icl.github.io/
Unified Model for Image, Video, Audio and Language Tasks
Jul 30, 2023Large Language Models (LLMs) have made the ambitious quest for generalist agents significantly far from being a fantasy. A key hurdle for building such general models is the diversity and heterogeneity of tasks and modalities. A promising solution is unification, allowing the support of a myriad of tasks and modalities within one unified framework. While few large models (e.g., Flamingo (Alayrac et al., 2022), trained on massive datasets, can support more than two modalities, current small to mid-scale unified models are still limited to 2 modalities, usually image-text or video-text. The question that we ask is: is it possible to build efficiently a unified model that can support all modalities? To answer this, we propose UnIVAL, a step further towards this ambitious goal. Without relying on fancy datasets sizes or models with billions of parameters, the ~ 0.25B parameter UnIVAL model goes beyond two modalities and unifies text, images, video, and audio into a single model. Our model is efficiently pretrained on many tasks, based on task balancing and multimodal curriculum learning. UnIVAL shows competitive performance to existing state-of-the-art approaches, across image and video-text tasks. The feature representations learned from image and video-text modalities, allows the model to achieve competitive performance when finetuned on audio-text tasks, despite not being pretrained on audio. Thanks to the unified model, we propose a novel study on multimodal model merging via weight interpolation of models trained on different multimodal tasks, showing their benefits in particular for out-of-distribution generalization. Finally, we motivate unification by showing the synergy between tasks. The model weights and code are released here: https://github.com/mshukor/UnIVAL.
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
Jun 07, 2023



Foundation models are first pre-trained on vast unsupervised datasets and then fine-tuned on labeled data. Reinforcement learning, notably from human feedback (RLHF), can further align the network with the intended usage. Yet the imperfections in the proxy reward may hinder the training and lead to suboptimal results; the diversity of objectives in real-world tasks and human opinions exacerbate the issue. This paper proposes embracing the heterogeneity of diverse rewards by following a multi-policy strategy. Rather than focusing on a single a priori reward, we aim for Pareto-optimal generalization across the entire space of preferences. To this end, we propose rewarded soup, first specializing multiple networks independently (one for each proxy reward) and then interpolating their weights linearly. This succeeds empirically because we show that the weights remain linearly connected when fine-tuned on diverse rewards from a shared pre-trained initialization. We demonstrate the effectiveness of our approach for text-to-text (summarization, Q&A, helpful assistant, review), text-image (image captioning, text-to-image generation, visual grounding, VQA), and control (locomotion) tasks. We hope to enhance the alignment of deep models, and how they interact with the world in all its diversity.
Diverse Weight Averaging for Out-of-Distribution Generalization
May 19, 2022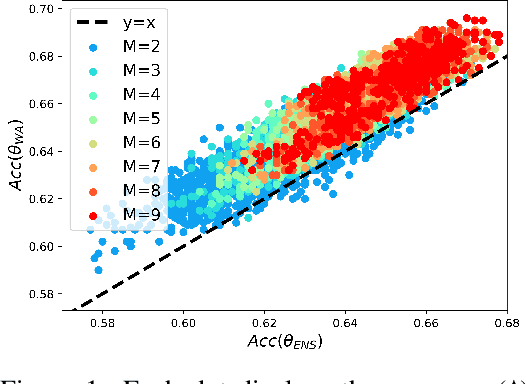



Standard neural networks struggle to generalize under distribution shifts. For out-of-distribution generalization in computer vision, the best current approach averages the weights along a training run. In this paper, we propose Diverse Weight Averaging (DiWA) that makes a simple change to this strategy: DiWA averages the weights obtained from several independent training runs rather than from a single run. Perhaps surprisingly, averaging these weights performs well under soft constraints despite the network's nonlinearities. The main motivation behind DiWA is to increase the functional diversity across averaged models. Indeed, models obtained from different runs are more diverse than those collected along a single run thanks to differences in hyperparameters and training procedures. We motivate the need for diversity by a new bias-variance-covariance-locality decomposition of the expected error, exploiting similarities between DiWA and standard functional ensembling. Moreover, this decomposition highlights that DiWA succeeds when the variance term dominates, which we show happens when the marginal distribution changes at test time. Experimentally, DiWA consistently improves the state of the art on the competitive DomainBed benchmark without inference overhead.
Fishr: Invariant Gradient Variances for Out-of-distribution Generalization
Sep 07, 2021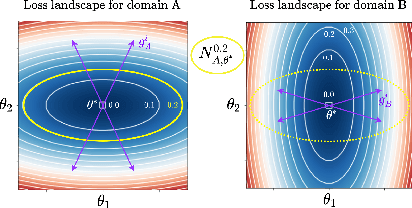

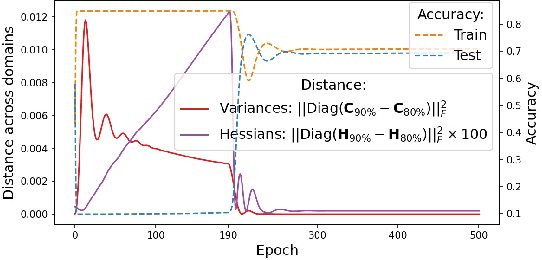

Learning robust models that generalize well under changes in the data distribution is critical for real-world applications. To this end, there has been a growing surge of interest to learn simultaneously from multiple training domains - while enforcing different types of invariance across those domains. Yet, all existing approaches fail to show systematic benefits under fair evaluation protocols. In this paper, we propose a new learning scheme to enforce domain invariance in the space of the gradients of the loss function: specifically, we introduce a regularization term that matches the domain-level variances of gradients across training domains. Critically, our strategy, named Fishr, exhibits close relations with the Fisher Information and the Hessian of the loss. We show that forcing domain-level gradient covariances to be similar during the learning procedure eventually aligns the domain-level loss landscapes locally around the final weights. Extensive experiments demonstrate the effectiveness of Fishr for out-of-distribution generalization. In particular, Fishr improves the state of the art on the DomainBed benchmark and performs significantly better than Empirical Risk Minimization. The code is released at https://github.com/alexrame/fishr.
MixMo: Mixing Multiple Inputs for Multiple Outputs via Deep Subnetworks
Mar 18, 2021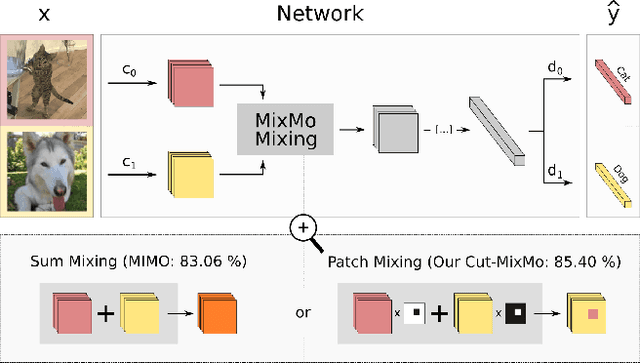



Recent strategies achieved ensembling "for free" by fitting concurrently diverse subnetworks inside a single base network. The main idea during training is that each subnetwork learns to classify only one of the multiple inputs simultaneously provided. However, the question of how to best mix these multiple inputs has not been studied so far. In this paper, we introduce MixMo, a new generalized framework for learning multi-input multi-output deep subnetworks. Our key motivation is to replace the suboptimal summing operation hidden in previous approaches by a more appropriate mixing mechanism. For that purpose, we draw inspiration from successful mixed sample data augmentations. We show that binary mixing in features - particularly with rectangular patches from CutMix - enhances results by making subnetworks stronger and more diverse. We improve state of the art for image classification on CIFAR-100 and Tiny ImageNet datasets. Our easy to implement models notably outperform data augmented deep ensembles, without the inference and memory overheads. As we operate in features and simply better leverage the expressiveness of large networks, we open a new line of research complementary to previous works.
DICE: Diversity in Deep Ensembles via Conditional Redundancy Adversarial Estimation
Jan 14, 2021
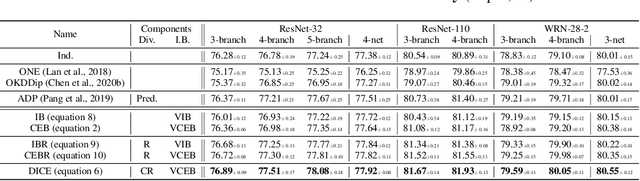


Deep ensembles perform better than a single network thanks to the diversity among their members. Recent approaches regularize predictions to increase diversity; however, they also drastically decrease individual members' performances. In this paper, we argue that learning strategies for deep ensembles need to tackle the trade-off between ensemble diversity and individual accuracies. Motivated by arguments from information theory and leveraging recent advances in neural estimation of conditional mutual information, we introduce a novel training criterion called DICE: it increases diversity by reducing spurious correlations among features. The main idea is that features extracted from pairs of members should only share information useful for target class prediction without being conditionally redundant. Therefore, besides the classification loss with information bottleneck, we adversarially prevent features from being conditionally predictable from each other. We manage to reduce simultaneous errors while protecting class information. We obtain state-of-the-art accuracy results on CIFAR-10/100: for example, an ensemble of 5 networks trained with DICE matches an ensemble of 7 networks trained independently. We further analyze the consequences on calibration, uncertainty estimation, out-of-distribution detection and online co-distillation.
CORE: Color Regression for Multiple Colors Fashion Garments
Oct 06, 2020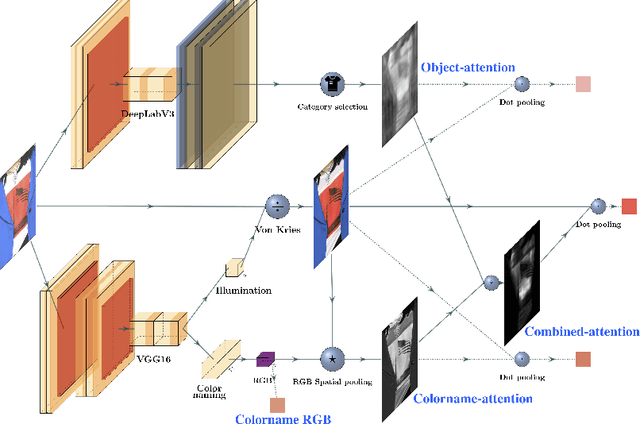

Among all fashion attributes, color is challenging to detect due to its subjective perception. Existing classification approaches can not go beyond the predefined list of discrete color names. In this paper, we argue that color detection is a regression problem. Thus, we propose a new architecture, based on attention modules and in two-stages. The first stage corrects the image illumination while detecting the main discrete color name. The second stage combines a colorname-attention (dependent of the detected color) with an object-attention (dependent of the clothing category) and finally weights a spatial pooling over the image pixels' RGB values. We further expand our work for multiple colors garments. We collect a dataset where each fashion item is labeled with a continuous color palette: we empirically show the benefits of our approach.
OMNIA Faster R-CNN: Detection in the wild through dataset merging and soft distillation
Dec 06, 2018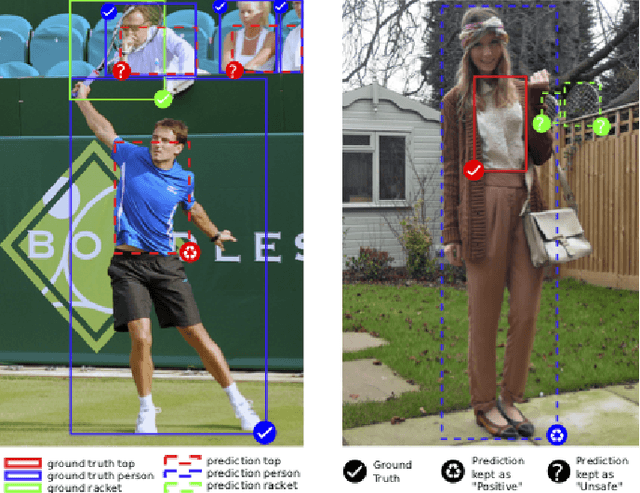

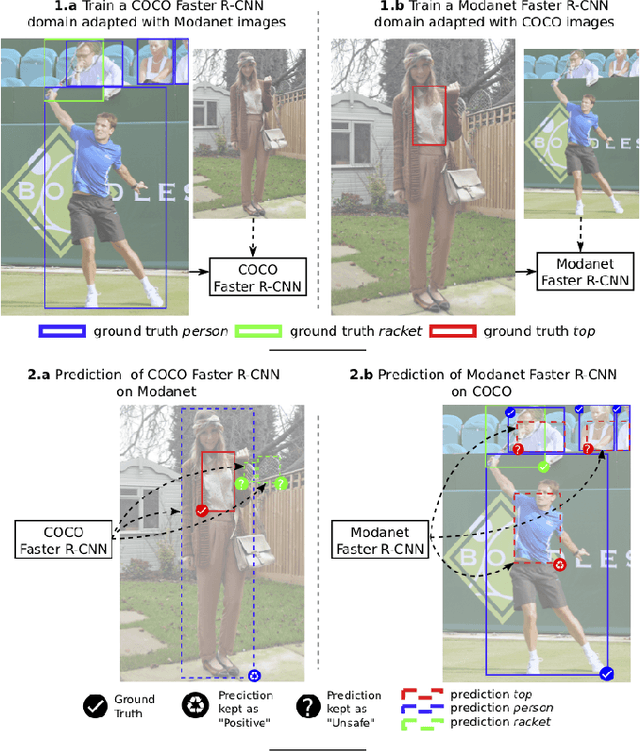

Object detectors tend to perform poorly in new or open domains, and require exhaustive yet costly annotations from fully labeled datasets. We aim at benefiting from several datasets with different categories but without additional labelling, not only to increase the number of categories detected, but also to take advantage from transfer learning and to enhance domain independence. Our dataset merging procedure starts with training several initial Faster R-CNN on the different datasets while considering the complementary datasets' images for domain adaptation. Similarly to self-training methods, the predictions of these initial detectors mitigate the missing annotations on the complementary datasets. The final OMNIA Faster R-CNN is trained with all categories on the union of the datasets enriched by predictions. The joint training handles unsafe targets with a new classification loss called SoftSig in a softly supervised way. Experimental results show that in the case of fashion detection for images in the wild, merging Modanet with COCO increases the final performance from 45.5% to 57.4%. Applying our soft distillation to the task of detection with domain shift on Cityscapes enables to beat the state-of-the-art by 5.3 points. We hope that our methodology could unlock object detection for real-world applications without immense datasets.