 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion bridges vector quantized Variational AutoEncoders
Feb 10, 2022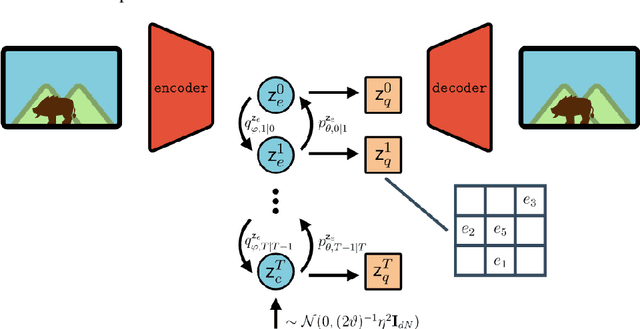



Vector Quantised-Variational AutoEncoders (VQ-VAE) are generative models based on discrete latent representations of the data, where inputs are mapped to a finite set of learned embeddings.To generate new samples, an autoregressive prior distribution over the discrete states must be trained separately. This prior is generally very complex and leads to very slow generation. In this work, we propose a new model to train the prior and the encoder/decoder networks simultaneously. We build a diffusion bridge between a continuous coded vector and a non-informative prior distribution. The latent discrete states are then given as random functions of these continuous vectors. We show that our model is competitive with the autoregressive prior on the mini-Imagenet dataset and is very efficient in both optimization and sampling. Our framework also extends the standard VQ-VAE and enables end-to-end training.
Learning Natural Language Generation from Scratch
Sep 20, 2021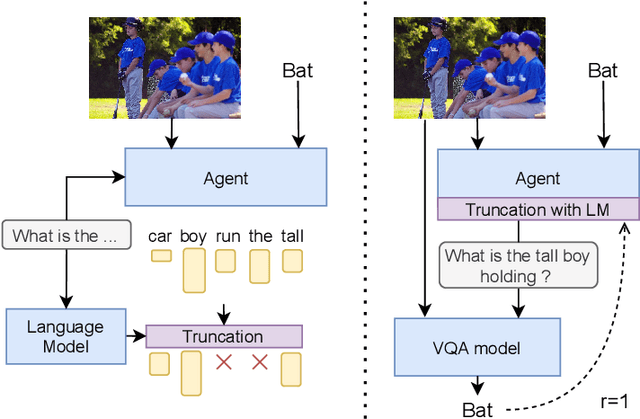
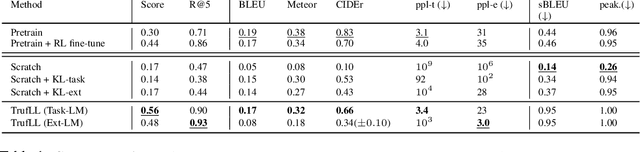

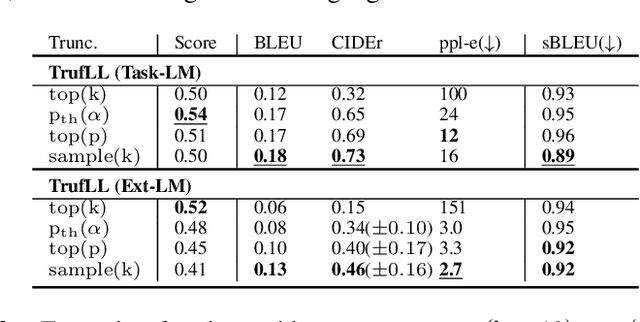
This paper introduces TRUncated ReinForcement Learning for Language (TrufLL), an original ap-proach to train conditional language models from scratch by only using reinforcement learning (RL). AsRL methods unsuccessfully scale to large action spaces, we dynamically truncate the vocabulary spaceusing a generic language model. TrufLL thus enables to train a language agent by solely interacting withits environment without any task-specific prior knowledge; it is only guided with a task-agnostic languagemodel. Interestingly, this approach avoids the dependency to labelled datasets and inherently reduces pre-trained policy flaws such as language or exposure biases. We evaluate TrufLL on two visual questiongeneration tasks, for which we report positive results over performance and language metrics, which wethen corroborate with a human evaluation. To our knowledge, it is the first approach that successfullylearns a language generation policy (almost) from scratch.
Invertible Flow Non Equilibrium sampling
Mar 17, 2021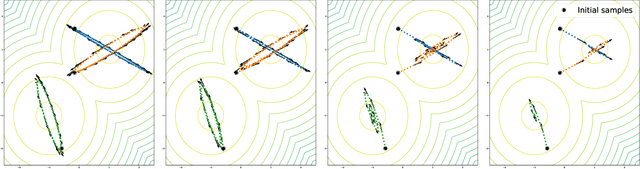
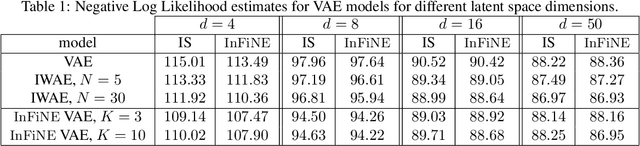
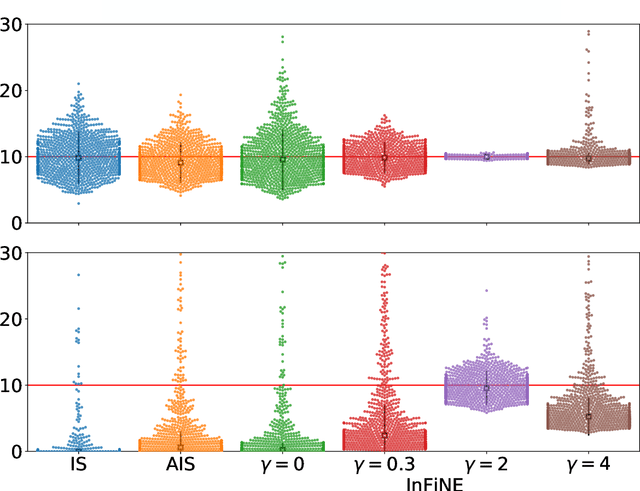
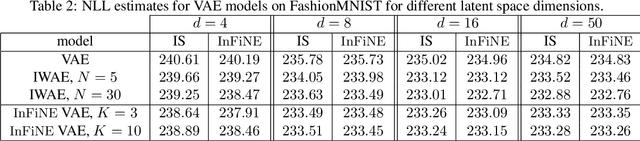
Simultaneously sampling from a complex distribution with intractable normalizing constant and approximating expectations under this distribution is a notoriously challenging problem. We introduce a novel scheme, Invertible Flow Non Equilibrium Sampling (InFine), which departs from classical Sequential Monte Carlo (SMC) and Markov chain Monte Carlo (MCMC) approaches. InFine constructs unbiased estimators of expectations and in particular of normalizing constants by combining the orbits of a deterministic transform started from random initializations.When this transform is chosen as an appropriate integrator of a conformal Hamiltonian system, these orbits are optimization paths. InFine is also naturally suited to design new MCMC sampling schemes by selecting samples on the optimization paths.Additionally, InFine can be used to construct an Evidence Lower Bound (ELBO) leading to a new class of Variational AutoEncoders (VAE).
Joint self-supervised blind denoising and noise estimation
Feb 16, 2021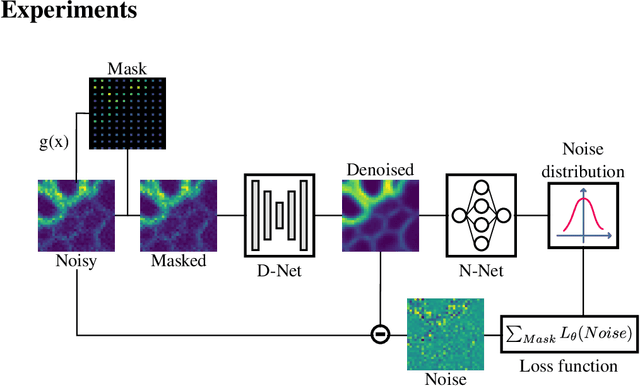



We propose a novel self-supervised image blind denoising approach in which two neural networks jointly predict the clean signal and infer the noise distribution. Assuming that the noisy observations are independent conditionally to the signal, the networks can be jointly trained without clean training data. Therefore, our approach is particularly relevant for biomedical image denoising where the noise is difficult to model precisely and clean training data are usually unavailable. Our method significantly outperforms current state-of-the-art self-supervised blind denoising algorithms, on six publicly available biomedical image datasets. We also show empirically with synthetic noisy data that our model captures the noise distribution efficiently. Finally, the described framework is simple, lightweight and computationally efficient, making it useful in practical cases.
CORE: Color Regression for Multiple Colors Fashion Garments
Oct 06, 2020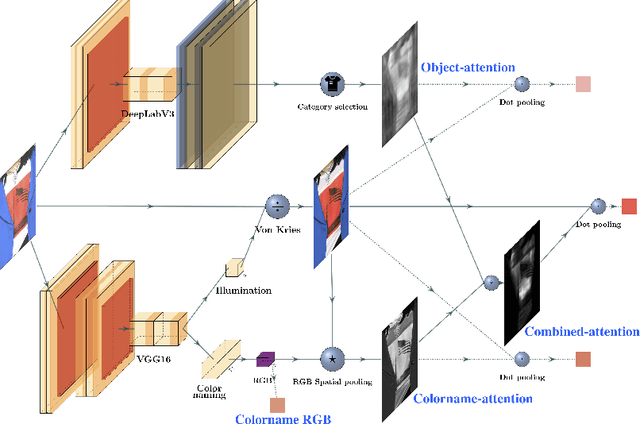

Among all fashion attributes, color is challenging to detect due to its subjective perception. Existing classification approaches can not go beyond the predefined list of discrete color names. In this paper, we argue that color detection is a regression problem. Thus, we propose a new architecture, based on attention modules and in two-stages. The first stage corrects the image illumination while detecting the main discrete color name. The second stage combines a colorname-attention (dependent of the detected color) with an object-attention (dependent of the clothing category) and finally weights a spatial pooling over the image pixels' RGB values. We further expand our work for multiple colors garments. We collect a dataset where each fashion item is labeled with a continuous color palette: we empirically show the benefits of our approach.
The Monte Carlo Transformer: a stochastic self-attention model for sequence prediction
Jul 15, 2020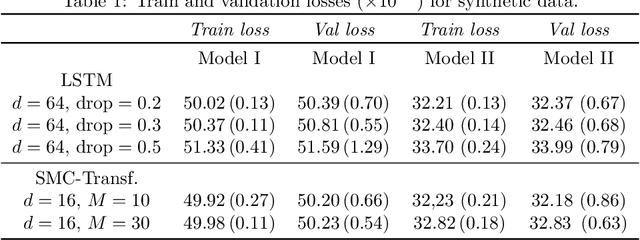
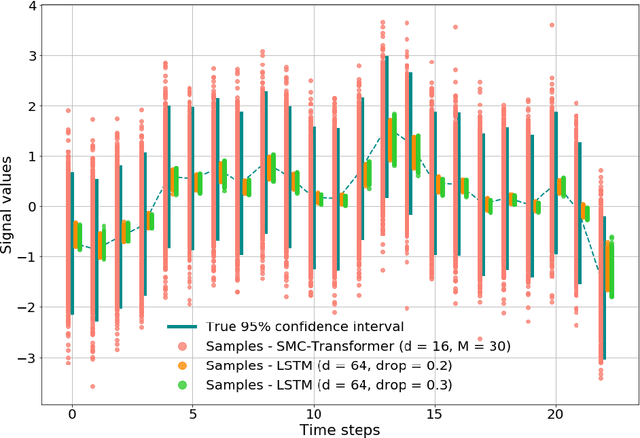
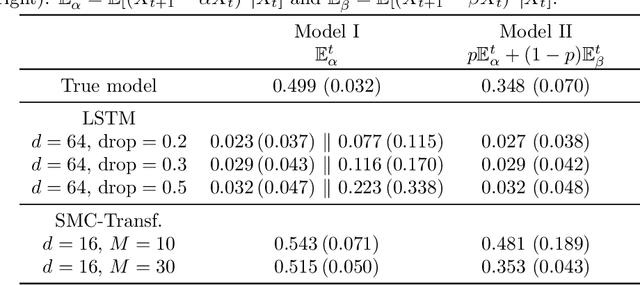
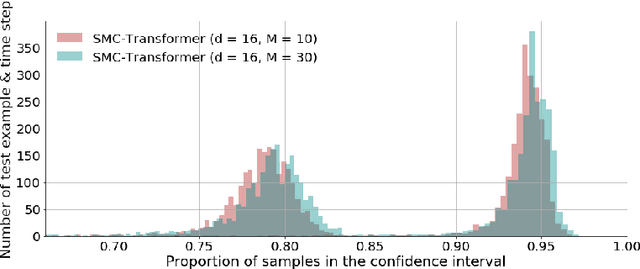
This paper introduces the Sequential Monte Carlo Transformer, an original approach that naturally captures the observations distribution in a recurrent architecture. The keys, queries, values and attention vectors of the network are considered as the unobserved stochastic states of its hidden structure. This generative model is such that at each time step the received observation is a random function of these past states in a given attention window. In this general state-space setting, we use Sequential Monte Carlo methods to approximate the posterior distributions of the states given the observations, and then to estimate the gradient of the log-likelihood. We thus propose a generative model providing a predictive distribution, instead of a single-point estimate.
Insights from the Future for Continual Learning
Jun 24, 2020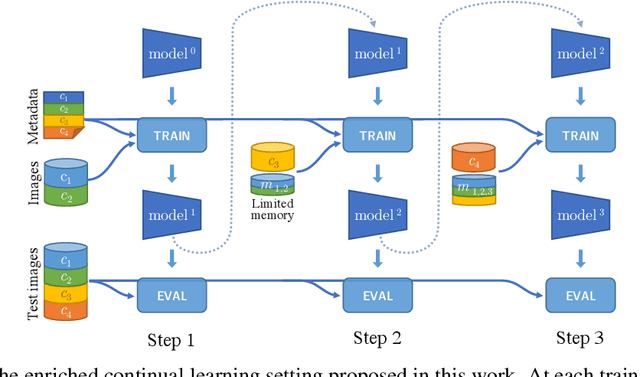
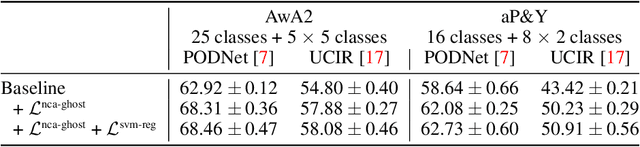

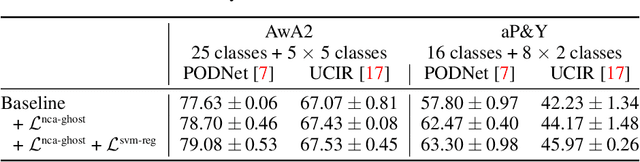
Continual learning aims to learn tasks sequentially, with (often severe) constraints on the storage of old learning samples, without suffering from catastrophic forgetting. In this work, we propose prescient continual learning, a novel experimental setting, to incorporate existing information about the classes, prior to any training data. Usually, each task in a traditional continual learning setting evaluates the model on present and past classes, the latter with a limited number of training samples. Our setting adds future classes, with no training samples at all. We introduce Ghost Model, a representation-learning-based model for continual learning using ideas from zero-shot learning. A generative model of the representation space in concert with a careful adjustment of the losses allows us to exploit insights from future classes to constraint the spatial arrangement of the past and current classes. Quantitative results on the AwA2 and aP\&Y datasets and detailed visualizations showcase the interest of this new setting and the method we propose to address it.
Small-Task Incremental Learning
Apr 28, 2020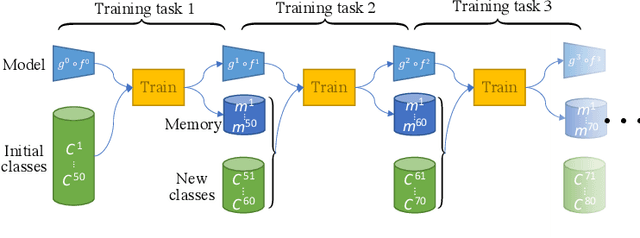
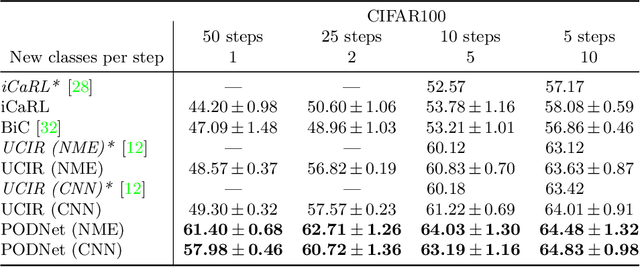

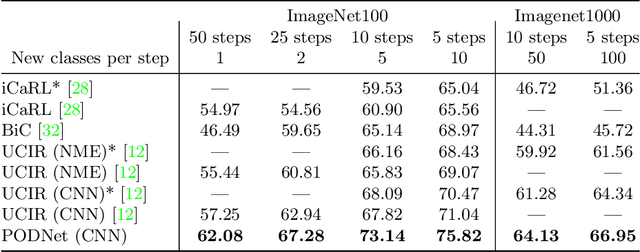
Lifelong learning has attracted much attention, but existing works still struggle to fight catastrophic forgetting and accumulate knowledge over long stretches of incremental learning. In this work, we propose PODNet, a model inspired by representation learning. By carefully balancing the compromise between remembering the old classes and learning new ones, PODNet fights catastrophic forgetting, even over very long runs of small incremental tasks-- a setting so far unexplored by current works. PODNet innovates on existing art with an efficient spatial-based distillation-loss applied throughout the model and a representation comprising multiple proxy vectors for each class. We validate those innovations thoroughly, comparing PODNet with three state-of-the-art models on three datasets: CIFAR100, ImageNet100, and ImageNet1000. Our results showcase a significant advantage of PODNet over existing art, with accuracy gains of 12.10, 4.83, and 2.85 percentage points, respectively. Code will be released at this address: https://github.com/arthurdouillard/incremental_learning.pytorch.
DistNet: Deep Tracking by displacement regression: application to bacteria growing in the Mother Machine
Mar 17, 2020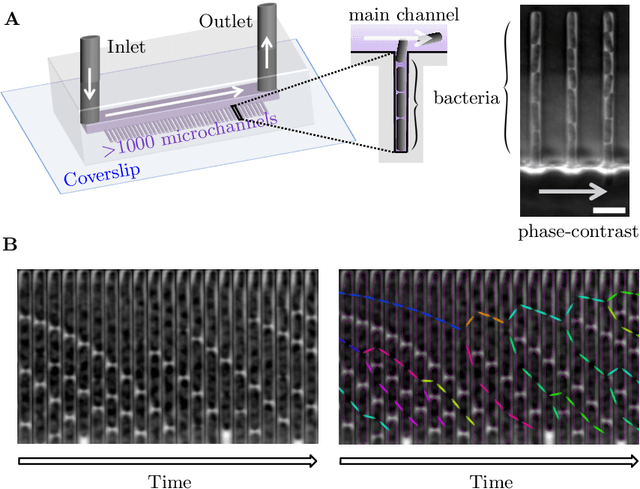
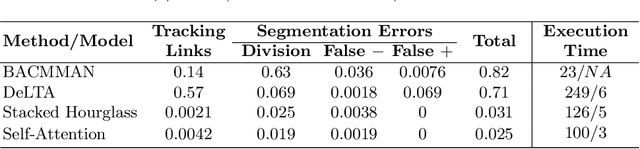
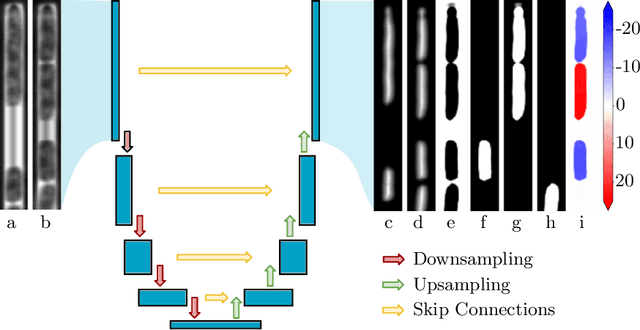
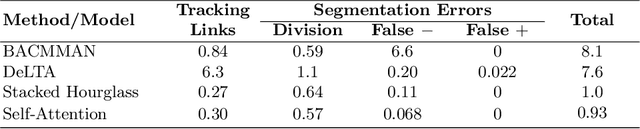
The mother machine is a popular microfluidic device that allows long-term time-lapse imaging of thousands of cells in parallel by microscopy. It has become a valuable tool for single-cell level quantitative analysis and characterization of many cellular processes such as gene expression and regulation, mutagenesis or response to antibiotics. The automated and quantitative analysis of the massive amount of data generated by such experiments is now the limiting step. In particular the segmentation and tracking of bacteria cells imaged in phase-contrast microscopy---with error rates compatible with high-throughput data---is a challenging problem. In this work, we describe a novel formulation of the multi-object tracking problem, in which tracking is performed by a regression of the bacteria's displacement, allowing simultaneous tracking of multiple bacteria, despite their growth and division over time. Our method performs jointly segmentation and tracking, leveraging sequential information to increase segmentation accuracy. We introduce a Deep Neural Network architecture taking advantage of a self-attention mechanism which yields less than 0.005% tracking error rate and less than 0.03% segmentation error rate. We demonstrate superior performance and speed compared to state-of-the-art methods. While this method is particularly well suited for mother machine microscopy data, its general joint tracking and segmentation formulation could be applied to many other problems with different geometries.
OMNIA Faster R-CNN: Detection in the wild through dataset merging and soft distillation
Dec 06, 2018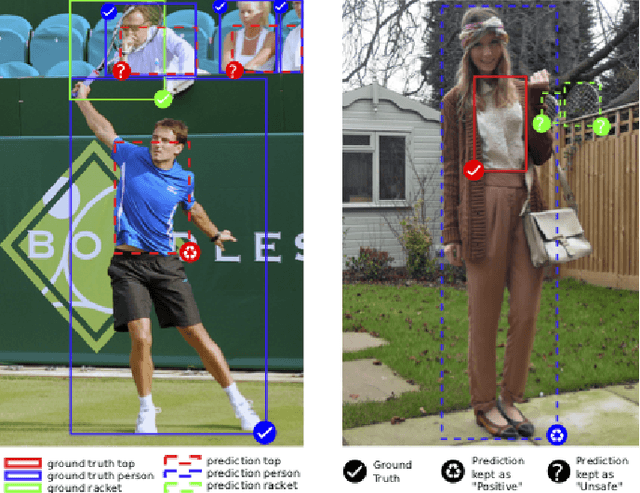

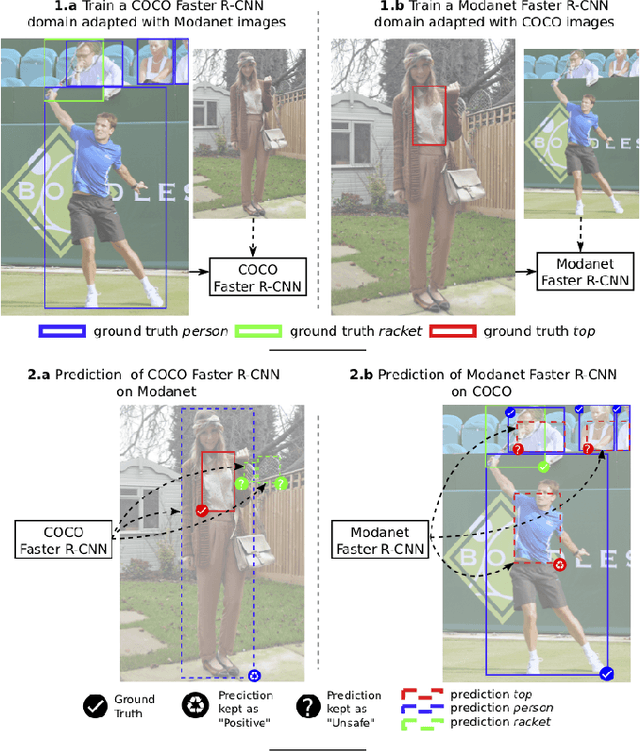

Object detectors tend to perform poorly in new or open domains, and require exhaustive yet costly annotations from fully labeled datasets. We aim at benefiting from several datasets with different categories but without additional labelling, not only to increase the number of categories detected, but also to take advantage from transfer learning and to enhance domain independence. Our dataset merging procedure starts with training several initial Faster R-CNN on the different datasets while considering the complementary datasets' images for domain adaptation. Similarly to self-training methods, the predictions of these initial detectors mitigate the missing annotations on the complementary datasets. The final OMNIA Faster R-CNN is trained with all categories on the union of the datasets enriched by predictions. The joint training handles unsafe targets with a new classification loss called SoftSig in a softly supervised way. Experimental results show that in the case of fashion detection for images in the wild, merging Modanet with COCO increases the final performance from 45.5% to 57.4%. Applying our soft distillation to the task of detection with domain shift on Cityscapes enables to beat the state-of-the-art by 5.3 points. We hope that our methodology could unlock object detection for real-world applications without immense datasets.