 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLast layer state space model for representation learning and uncertainty quantification
Jul 04, 2023


As sequential neural architectures become deeper and more complex, uncertainty estimation is more and more challenging. Efforts in quantifying uncertainty often rely on specific training procedures, and bear additional computational costs due to the dimensionality of such models. In this paper, we propose to decompose a classification or regression task in two steps: a representation learning stage to learn low-dimensional states, and a state space model for uncertainty estimation. This approach allows to separate representation learning and design of generative models. We demonstrate how predictive distributions can be estimated on top of an existing and trained neural network, by adding a state space-based last layer whose parameters are estimated with Sequential Monte Carlo methods. We apply our proposed methodology to the hourly estimation of Electricity Transformer Oil temperature, a publicly benchmarked dataset. Our model accounts for the noisy data structure, due to unknown or unavailable variables, and is able to provide confidence intervals on predictions.
Variational Latent Discrete Representation for Time Series Modelling
Jun 28, 2023

Discrete latent space models have recently achieved performance on par with their continuous counterparts in deep variational inference. While they still face various implementation challenges, these models offer the opportunity for a better interpretation of latent spaces, as well as a more direct representation of naturally discrete phenomena. Most recent approaches propose to train separately very high-dimensional prior models on the discrete latent data which is a challenging task on its own. In this paper, we introduce a latent data model where the discrete state is a Markov chain, which allows fast end-to-end training. The performance of our generative model is assessed on a building management dataset and on the publicly available Electricity Transformer Dataset.
Diffusion bridges vector quantized Variational AutoEncoders
Feb 10, 2022



Vector Quantised-Variational AutoEncoders (VQ-VAE) are generative models based on discrete latent representations of the data, where inputs are mapped to a finite set of learned embeddings.To generate new samples, an autoregressive prior distribution over the discrete states must be trained separately. This prior is generally very complex and leads to very slow generation. In this work, we propose a new model to train the prior and the encoder/decoder networks simultaneously. We build a diffusion bridge between a continuous coded vector and a non-informative prior distribution. The latent discrete states are then given as random functions of these continuous vectors. We show that our model is competitive with the autoregressive prior on the mini-Imagenet dataset and is very efficient in both optimization and sampling. Our framework also extends the standard VQ-VAE and enables end-to-end training.
End-to-end deep metamodeling to calibrate and optimize energy loads
Jun 19, 2020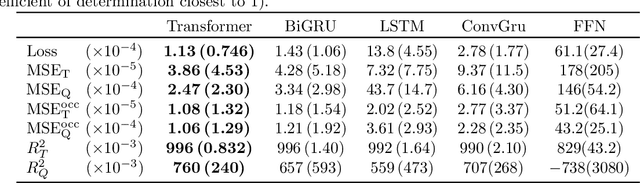
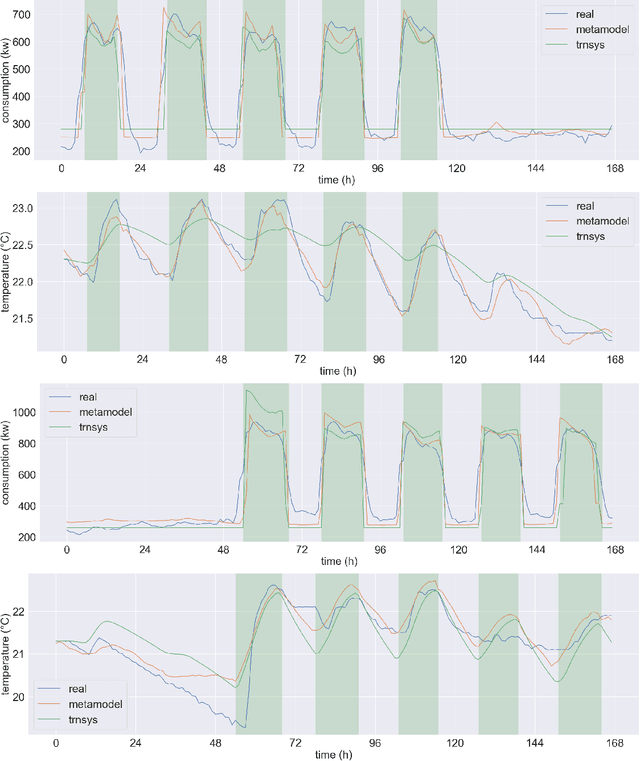
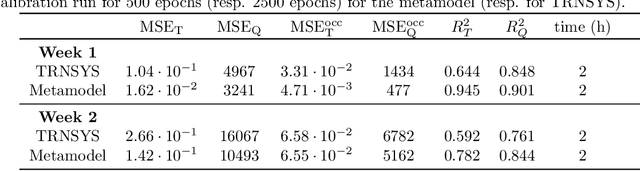
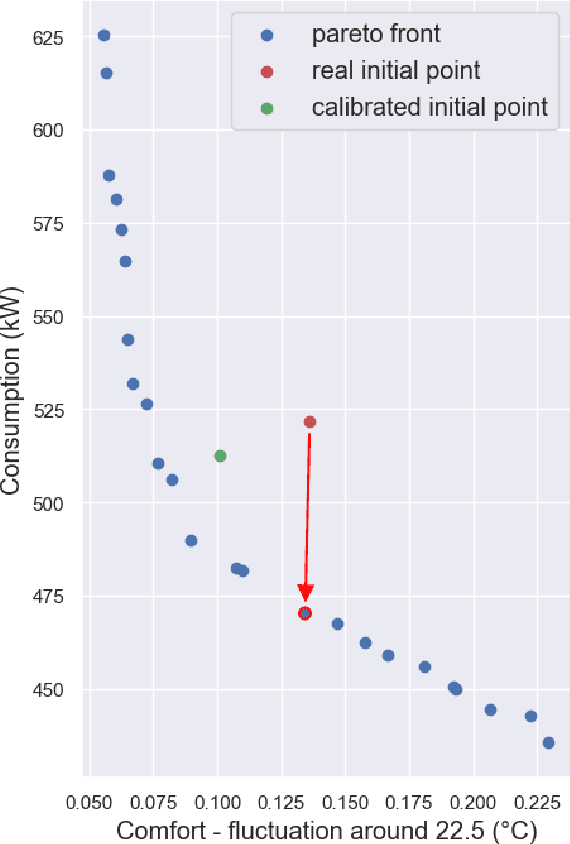
In this paper, we propose a new end-to-end methodology to optimize the energy performance and the comfort, air quality and hygiene of large buildings. A metamodel based on a Transformer network is introduced and trained using a dataset sampled with a simulation program. Then, a few physical parameters and the building management system settings of this metamodel are calibrated using the CMA-ES optimization algorithm and real data obtained from sensors. Finally, the optimal settings to minimize the energy loads while maintaining a target thermal comfort and air quality are obtained using a multi-objective optimization procedure. The numerical experiments illustrate how this metamodel ensures a significant gain in energy efficiency while being computationally much more appealing than models requiring a huge number of physical parameters to be estimated.