 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion bridges vector quantized Variational AutoEncoders
Paper and Code
Feb 10, 2022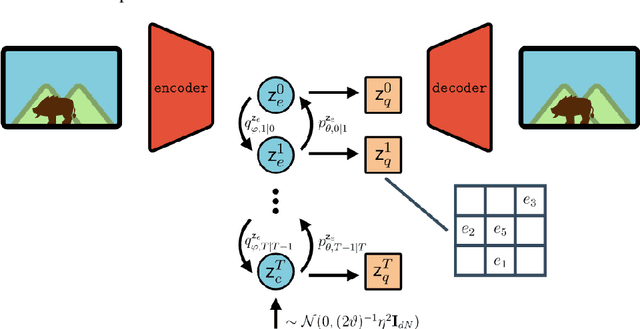



Vector Quantised-Variational AutoEncoders (VQ-VAE) are generative models based on discrete latent representations of the data, where inputs are mapped to a finite set of learned embeddings.To generate new samples, an autoregressive prior distribution over the discrete states must be trained separately. This prior is generally very complex and leads to very slow generation. In this work, we propose a new model to train the prior and the encoder/decoder networks simultaneously. We build a diffusion bridge between a continuous coded vector and a non-informative prior distribution. The latent discrete states are then given as random functions of these continuous vectors. We show that our model is competitive with the autoregressive prior on the mini-Imagenet dataset and is very efficient in both optimization and sampling. Our framework also extends the standard VQ-VAE and enables end-to-end training.