 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Variational Estimation via Monte Carlo Sampling
Feb 06, 2026This article addresses online variational estimation in parametric state-space models. We propose a new procedure for efficiently computing the evidence lower bound and its gradient in a streaming-data setting, where observations arrive sequentially. The algorithm allows for the simultaneous training of the model parameters and the distribution of the latent states given the observations. It is based on i.i.d. Monte Carlo sampling, coupled with a well-chosen deep architecture, enabling both computational efficiency and flexibility. The performance of the method is illustrated on both synthetic data and real-world air-quality data. The proposed approach is theoretically motivated by the existence of an asymptotic contrast function and the ergodicity of the underlying Markov chain, and applies more generally to the computation of additive expectations under posterior distributions in state-space models.
Entropic Mirror Monte Carlo
Feb 03, 2026Importance sampling is a Monte Carlo method which designs estimators of expectations under a target distribution using weighted samples from a proposal distribution. When the target distribution is complex, such as multimodal distributions in highdimensional spaces, the efficiency of importance sampling critically depends on the choice of the proposal distribution. In this paper, we propose a novel adaptive scheme for the construction of efficient proposal distributions. Our algorithm promotes efficient exploration of the target distribution by combining global sampling mechanisms with a delayed weighting procedure. The proposed weighting mechanism plays a key role by enabling rapid resampling in regions where the proposal distribution is poorly adapted to the target. Our sampling algorithm is shown to be geometrically convergent under mild assumptions and is illustrated through various numerical experiments.
On Forgetting and Stability of Score-based Generative models
Jan 29, 2026Understanding the stability and long-time behavior of generative models is a fundamental problem in modern machine learning. This paper provides quantitative bounds on the sampling error of score-based generative models by leveraging stability and forgetting properties of the Markov chain associated with the reverse-time dynamics. Under weak assumptions, we provide the two structural properties to ensure the propagation of initialization and discretization errors of the backward process: a Lyapunov drift condition and a Doeblin-type minorization condition. A practical consequence is quantitative stability of the sampling procedure, as the reverse diffusion dynamics induces a contraction mechanism along the sampling trajectory. Our results clarify the role of stochastic dynamics in score-based models and provide a principled framework for analyzing propagation of errors in such approaches.
Independent Component Discovery in Temporal Count Data
Jan 29, 2026Advances in data collection are producing growing volumes of temporal count observations, making adapted modeling increasingly necessary. In this work, we introduce a generative framework for independent component analysis of temporal count data, combining regime-adaptive dynamics with Poisson log-normal emissions. The model identifies disentangled components with regime-dependent contributions, enabling representation learning and perturbations analysis. Notably, we establish the identifiability of the model, supporting principled interpretation. To learn the parameters, we propose an efficient amortized variational inference procedure. Experiments on simulated data evaluate recovery of the mixing function and latent sources across diverse settings, while an in vivo longitudinal gut microbiome study reveals microbial co-variation patterns and regime shifts consistent with clinical perturbations.
Theoretical Convergence Guarantees for Variational Autoencoders
Oct 22, 2024



Variational Autoencoders (VAE) are popular generative models used to sample from complex data distributions. Despite their empirical success in various machine learning tasks, significant gaps remain in understanding their theoretical properties, particularly regarding convergence guarantees. This paper aims to bridge that gap by providing non-asymptotic convergence guarantees for VAE trained using both Stochastic Gradient Descent and Adam algorithms.We derive a convergence rate of $\mathcal{O}(\log n / \sqrt{n})$, where $n$ is the number of iterations of the optimization algorithm, with explicit dependencies on the batch size, the number of variational samples, and other key hyperparameters. Our theoretical analysis applies to both Linear VAE and Deep Gaussian VAE, as well as several VAE variants, including $\beta$-VAE and IWAE. Additionally, we empirically illustrate the impact of hyperparameters on convergence, offering new insights into the theoretical understanding of VAE training.
Tree-based variational inference for Poisson log-normal models
Jun 25, 2024When studying ecosystems, hierarchical trees are often used to organize entities based on proximity criteria, such as the taxonomy in microbiology, social classes in geography, or product types in retail businesses, offering valuable insights into entity relationships. Despite their significance, current count-data models do not leverage this structured information. In particular, the widely used Poisson log-normal (PLN) model, known for its ability to model interactions between entities from count data, lacks the possibility to incorporate such hierarchical tree structures, limiting its applicability in domains characterized by such complexities. To address this matter, we introduce the PLN-Tree model as an extension of the PLN model, specifically designed for modeling hierarchical count data. By integrating structured variational inference techniques, we propose an adapted training procedure and establish identifiability results, enhancisng both theoretical foundations and practical interpretability. Additionally, we extend our framework to classification tasks as a preprocessing pipeline, showcasing its versatility. Experimental evaluations on synthetic datasets as well as real-world microbiome data demonstrate the superior performance of the PLN-Tree model in capturing hierarchical dependencies and providing valuable insights into complex data structures, showing the practical interest of knowledge graphs like the taxonomy in ecosystems modeling.
Variational quantization for state space models
Apr 17, 2024



Forecasting tasks using large datasets gathering thousands of heterogeneous time series is a crucial statistical problem in numerous sectors. The main challenge is to model a rich variety of time series, leverage any available external signals and provide sharp predictions with statistical guarantees. In this work, we propose a new forecasting model that combines discrete state space hidden Markov models with recent neural network architectures and training procedures inspired by vector quantized variational autoencoders. We introduce a variational discrete posterior distribution of the latent states given the observations and a two-stage training procedure to alternatively train the parameters of the latent states and of the emission distributions. By learning a collection of emission laws and temporarily activating them depending on the hidden process dynamics, the proposed method allows to explore large datasets and leverage available external signals. We assess the performance of the proposed method using several datasets and show that it outperforms other state-of-the-art solutions.
Diffusion posterior sampling for simulation-based inference in tall data settings
Apr 11, 2024Determining which parameters of a non-linear model could best describe a set of experimental data is a fundamental problem in science and it has gained much traction lately with the rise of complex large-scale simulators (a.k.a. black-box simulators). The likelihood of such models is typically intractable, which is why classical MCMC methods can not be used. Simulation-based inference (SBI) stands out in this context by only requiring a dataset of simulations to train deep generative models capable of approximating the posterior distribution that relates input parameters to a given observation. In this work, we consider a tall data extension in which multiple observations are available and one wishes to leverage their shared information to better infer the parameters of the model. The method we propose is built upon recent developments from the flourishing score-based diffusion literature and allows us to estimate the tall data posterior distribution simply using information from the score network trained on individual observations. We compare our method to recently proposed competing approaches on various numerical experiments and demonstrate its superiority in terms of numerical stability and computational cost.
An analysis of the noise schedule for score-based generative models
Feb 07, 2024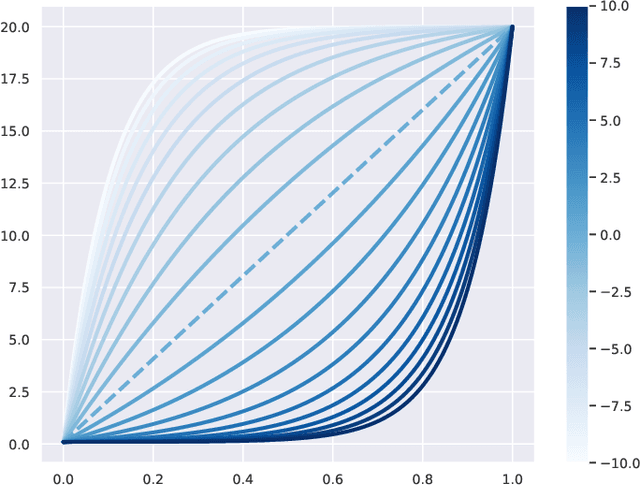
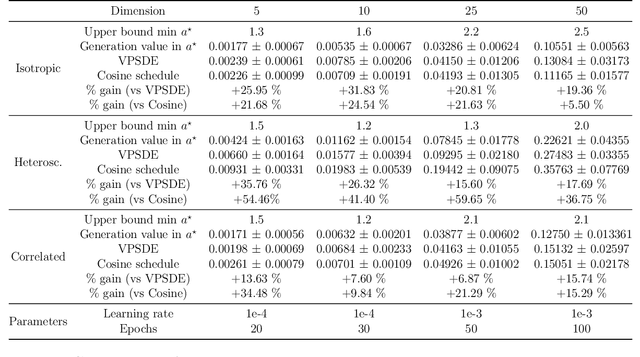
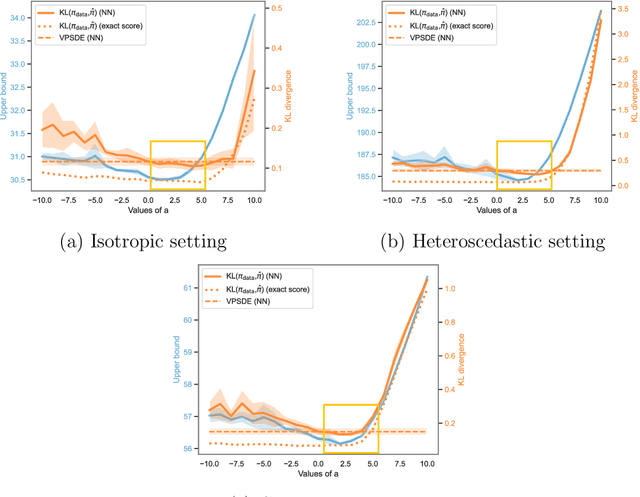
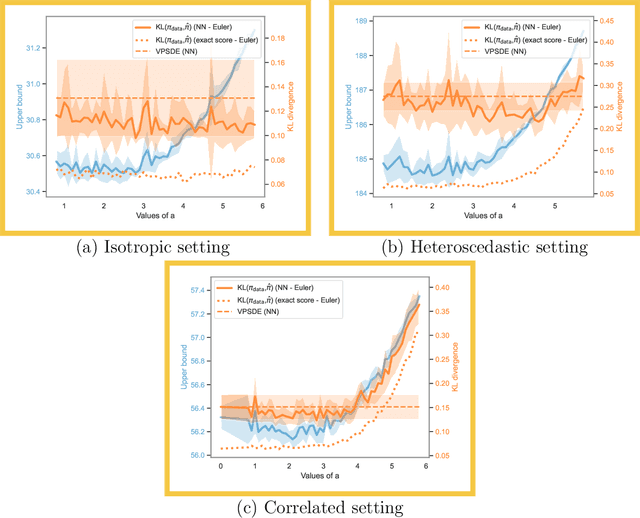
Score-based generative models (SGMs) aim at estimating a target data distribution by learning score functions using only noise-perturbed samples from the target. Recent literature has focused extensively on assessing the error between the target and estimated distributions, gauging the generative quality through the Kullback-Leibler (KL) divergence and Wasserstein distances. All existing results have been obtained so far for time-homogeneous speed of the noise schedule. Under mild assumptions on the data distribution, we establish an upper bound for the KL divergence between the target and the estimated distributions, explicitly depending on any time-dependent noise schedule. Assuming that the score is Lipschitz continuous, we provide an improved error bound in Wasserstein distance, taking advantage of favourable underlying contraction mechanisms. We also propose an algorithm to automatically tune the noise schedule using the proposed upper bound. We illustrate empirically the performance of the noise schedule optimization in comparison to standard choices in the literature.
Importance sampling for online variational learning
Feb 05, 2024This article addresses online variational estimation in state-space models. We focus on learning the smoothing distribution, i.e. the joint distribution of the latent states given the observations, using a variational approach together with Monte Carlo importance sampling. We propose an efficient algorithm for computing the gradient of the evidence lower bound (ELBO) in the context of streaming data, where observations arrive sequentially. Our contributions include a computationally efficient online ELBO estimator, demonstrated performance in offline and true online settings, and adaptability for computing general expectations under joint smoothing distributions.