 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based PCA
May 18, 2026We study attention mechanisms through the lens of a canonical unsupervised problem: principal component analysis (PCA). We show that, when trained on Gaussian data, both softmax and linear attention layers learn parameters that align with the principal eigenvectors of the covariance matrix, thereby establishing a direct and explicit connection with PCA. Our analysis covers both finite and infinite prompt regimes. In the infinite-prompt limit, we prove convergence to globally optimal solutions aligned with the leading spectral direction, while in the finiteprompt setting we show that the same behavior emerges up to sampling effects. We further extend the analysis to an in-context setting with spiked Wishart covariances, where attention successfully recovers the underlying signal direction. These results demonstrate that attention inherently performs PCA-like computations under unsupervised objectives, providing a theoretical foundation for its representation-learning capabilities.
Convergence Rates for Distribution Matching with Sliced Optimal Transport
Feb 11, 2026We study the slice-matching scheme, an efficient iterative method for distribution matching based on sliced optimal transport. We investigate convergence to the target distribution and derive quantitative non-asymptotic rates. To this end, we establish __ojasiewicz-type inequalities for the Sliced-Wasserstein objective. A key challenge is to control along the trajectory the constants in these inequalities. We show that this becomes tractable for Gaussian distributions. Specifically, eigenvalues are controlled when matching along random orthonormal bases at each iteration. We complement our theory with numerical experiments and illustrate the predicted dependence on dimension and step-size, as well as the stabilizing effect of orthonormal-basis sampling.
Softmax as Linear Attention in the Large-Prompt Regime: a Measure-based Perspective
Dec 12, 2025Softmax attention is a central component of transformer architectures, yet its nonlinear structure poses significant challenges for theoretical analysis. We develop a unified, measure-based framework for studying single-layer softmax attention under both finite and infinite prompts. For i.i.d. Gaussian inputs, we lean on the fact that the softmax operator converges in the infinite-prompt limit to a linear operator acting on the underlying input-token measure. Building on this insight, we establish non-asymptotic concentration bounds for the output and gradient of softmax attention, quantifying how rapidly the finite-prompt model approaches its infinite-prompt counterpart, and prove that this concentration remains stable along the entire training trajectory in general in-context learning settings with sub-Gaussian tokens. In the case of in-context linear regression, we use the tractable infinite-prompt dynamics to analyze training at finite prompt length. Our results allow optimization analyses developed for linear attention to transfer directly to softmax attention when prompts are sufficiently long, showing that large-prompt softmax attention inherits the analytical structure of its linear counterpart. This, in turn, provides a principled and broadly applicable toolkit for studying the training dynamics and statistical behavior of softmax attention layers in large prompt regimes.
Attention-based clustering
May 19, 2025Transformers have emerged as a powerful neural network architecture capable of tackling a wide range of learning tasks. In this work, we provide a theoretical analysis of their ability to automatically extract structure from data in an unsupervised setting. In particular, we demonstrate their suitability for clustering when the input data is generated from a Gaussian mixture model. To this end, we study a simplified two-head attention layer and define a population risk whose minimization with unlabeled data drives the head parameters to align with the true mixture centroids.
Taking a Big Step: Large Learning Rates in Denoising Score Matching Prevent Memorization
Feb 05, 2025



Denoising score matching plays a pivotal role in the performance of diffusion-based generative models. However, the empirical optimal score--the exact solution to the denoising score matching--leads to memorization, where generated samples replicate the training data. Yet, in practice, only a moderate degree of memorization is observed, even without explicit regularization. In this paper, we investigate this phenomenon by uncovering an implicit regularization mechanism driven by large learning rates. Specifically, we show that in the small-noise regime, the empirical optimal score exhibits high irregularity. We then prove that, when trained by stochastic gradient descent with a large enough learning rate, neural networks cannot stably converge to a local minimum with arbitrarily small excess risk. Consequently, the learned score cannot be arbitrarily close to the empirical optimal score, thereby mitigating memorization. To make the analysis tractable, we consider one-dimensional data and two-layer neural networks. Experiments validate the crucial role of the learning rate in preventing memorization, even beyond the one-dimensional setting.
Optimal Transport-based Conformal Prediction
Jan 31, 2025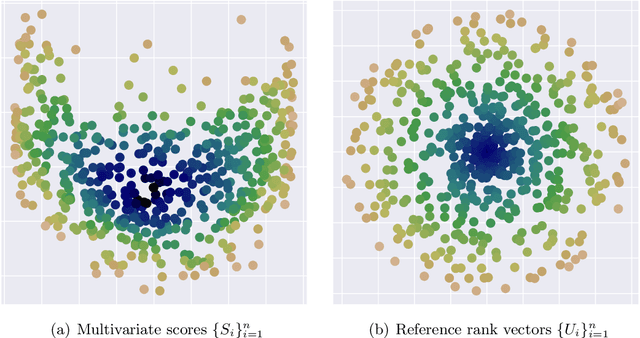
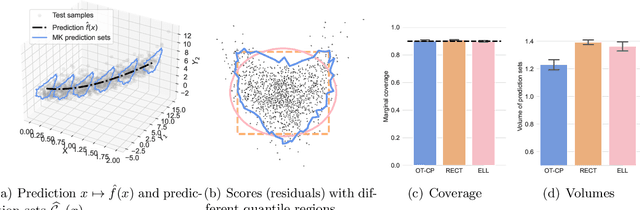
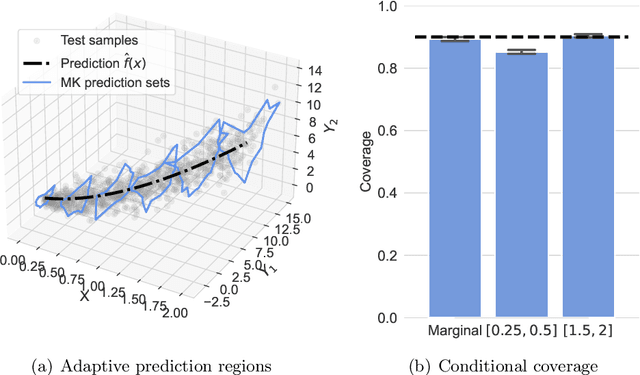
Conformal Prediction (CP) is a principled framework for quantifying uncertainty in blackbox learning models, by constructing prediction sets with finite-sample coverage guarantees. Traditional approaches rely on scalar nonconformity scores, which fail to fully exploit the geometric structure of multivariate outputs, such as in multi-output regression or multiclass classification. Recent methods addressing this limitation impose predefined convex shapes for the prediction sets, potentially misaligning with the intrinsic data geometry. We introduce a novel CP procedure handling multivariate score functions through the lens of optimal transport. Specifically, we leverage Monge-Kantorovich vector ranks and quantiles to construct prediction region with flexible, potentially non-convex shapes, better suited to the complex uncertainty patterns encountered in multivariate learning tasks. We prove that our approach ensures finite-sample, distribution-free coverage properties, similar to typical CP methods. We then adapt our method for multi-output regression and multiclass classification, and also propose simple adjustments to generate adaptive prediction regions with asymptotic conditional coverage guarantees. Finally, we evaluate our method on practical regression and classification problems, illustrating its advantages in terms of (conditional) coverage and efficiency.
Attention layers provably solve single-location regression
Oct 02, 2024

Attention-based models, such as Transformer, excel across various tasks but lack a comprehensive theoretical understanding, especially regarding token-wise sparsity and internal linear representations. To address this gap, we introduce the single-location regression task, where only one token in a sequence determines the output, and its position is a latent random variable, retrievable via a linear projection of the input. To solve this task, we propose a dedicated predictor, which turns out to be a simplified version of a non-linear self-attention layer. We study its theoretical properties, by showing its asymptotic Bayes optimality and analyzing its training dynamics. In particular, despite the non-convex nature of the problem, the predictor effectively learns the underlying structure. This work highlights the capacity of attention mechanisms to handle sparse token information and internal linear structures.
Physics-informed machine learning as a kernel method
Feb 12, 2024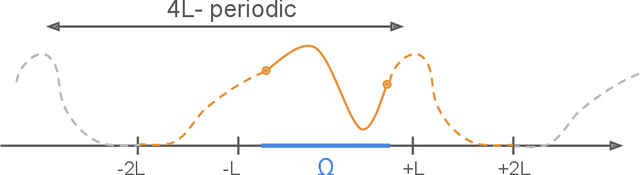
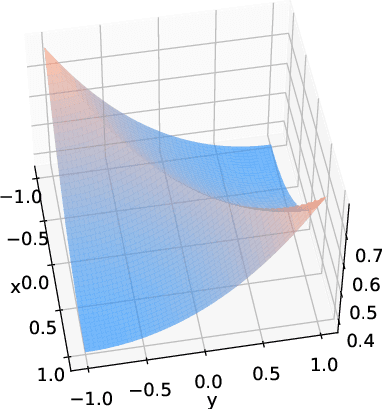
Physics-informed machine learning combines the expressiveness of data-based approaches with the interpretability of physical models. In this context, we consider a general regression problem where the empirical risk is regularized by a partial differential equation that quantifies the physical inconsistency. We prove that for linear differential priors, the problem can be formulated as a kernel regression task. Taking advantage of kernel theory, we derive convergence rates for the minimizer of the regularized risk and show that it converges at least at the Sobolev minimax rate. However, faster rates can be achieved, depending on the physical error. This principle is illustrated with a one-dimensional example, supporting the claim that regularizing the empirical risk with physical information can be beneficial to the statistical performance of estimators.
An analysis of the noise schedule for score-based generative models
Feb 07, 2024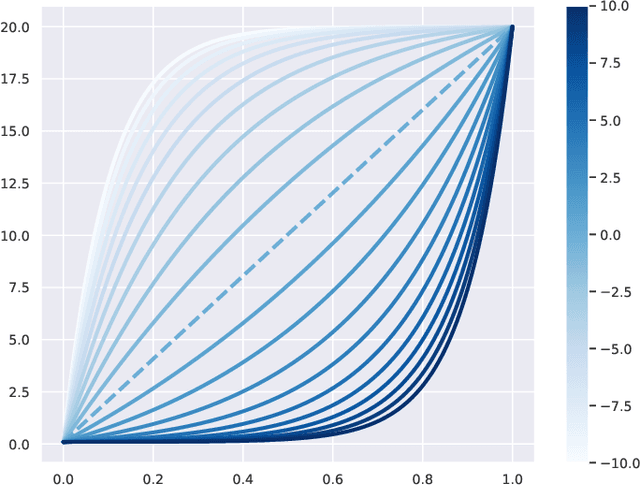
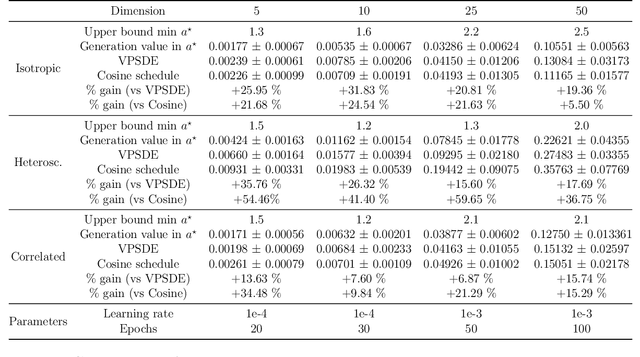
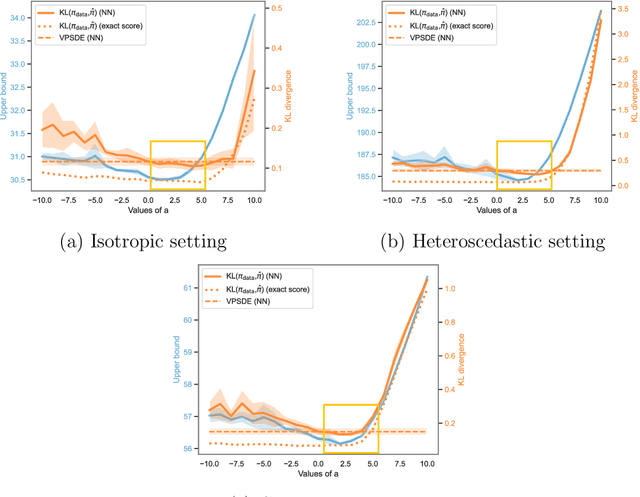
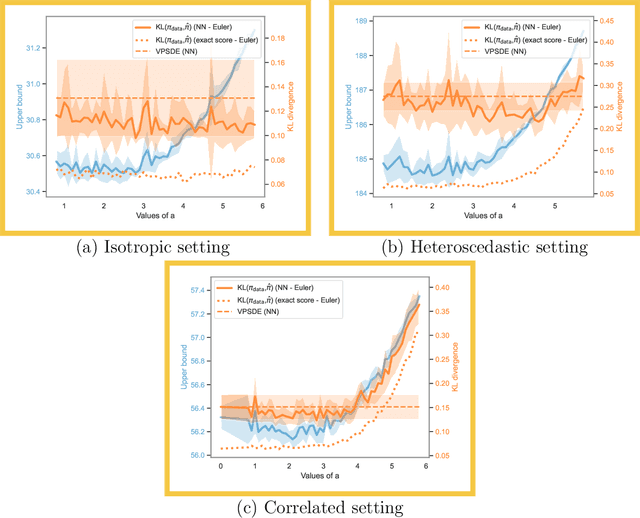
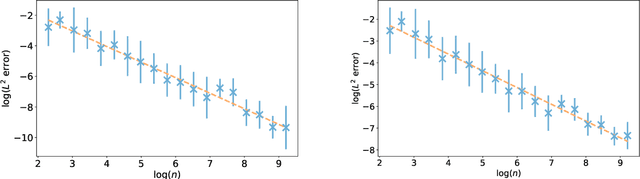
Score-based generative models (SGMs) aim at estimating a target data distribution by learning score functions using only noise-perturbed samples from the target. Recent literature has focused extensively on assessing the error between the target and estimated distributions, gauging the generative quality through the Kullback-Leibler (KL) divergence and Wasserstein distances. All existing results have been obtained so far for time-homogeneous speed of the noise schedule. Under mild assumptions on the data distribution, we establish an upper bound for the KL divergence between the target and the estimated distributions, explicitly depending on any time-dependent noise schedule. Assuming that the score is Lipschitz continuous, we provide an improved error bound in Wasserstein distance, taking advantage of favourable underlying contraction mechanisms. We also propose an algorithm to automatically tune the noise schedule using the proposed upper bound. We illustrate empirically the performance of the noise schedule optimization in comparison to standard choices in the literature.
Random features models: a way to study the success of naive imputation
Feb 06, 2024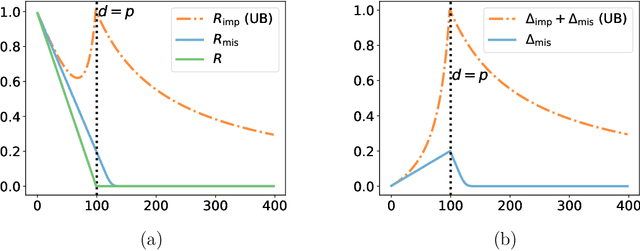

Constant (naive) imputation is still widely used in practice as this is a first easy-to-use technique to deal with missing data. Yet, this simple method could be expected to induce a large bias for prediction purposes, as the imputed input may strongly differ from the true underlying data. However, recent works suggest that this bias is low in the context of high-dimensional linear predictors when data is supposed to be missing completely at random (MCAR). This paper completes the picture for linear predictors by confirming the intuition that the bias is negligible and that surprisingly naive imputation also remains relevant in very low dimension.To this aim, we consider a unique underlying random features model, which offers a rigorous framework for studying predictive performances, whilst the dimension of the observed features varies.Building on these theoretical results, we establish finite-sample bounds on stochastic gradient (SGD) predictors applied to zero-imputed data, a strategy particularly well suited for large-scale learning.If the MCAR assumption appears to be strong, we show that similar favorable behaviors occur for more complex missing data scenarios.