 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Forgetting and Stability of Score-based Generative models
Jan 29, 2026Understanding the stability and long-time behavior of generative models is a fundamental problem in modern machine learning. This paper provides quantitative bounds on the sampling error of score-based generative models by leveraging stability and forgetting properties of the Markov chain associated with the reverse-time dynamics. Under weak assumptions, we provide the two structural properties to ensure the propagation of initialization and discretization errors of the backward process: a Lyapunov drift condition and a Doeblin-type minorization condition. A practical consequence is quantitative stability of the sampling procedure, as the reverse diffusion dynamics induces a contraction mechanism along the sampling trajectory. Our results clarify the role of stochastic dynamics in score-based models and provide a principled framework for analyzing propagation of errors in such approaches.
Finite-Sample Convergence Bounds for Trust Region Policy Optimization in Mean-Field Games
May 28, 2025We introduce Mean-Field Trust Region Policy Optimization (MF-TRPO), a novel algorithm designed to compute approximate Nash equilibria for ergodic Mean-Field Games (MFG) in finite state-action spaces. Building on the well-established performance of TRPO in the reinforcement learning (RL) setting, we extend its methodology to the MFG framework, leveraging its stability and robustness in policy optimization. Under standard assumptions in the MFG literature, we provide a rigorous analysis of MF-TRPO, establishing theoretical guarantees on its convergence. Our results cover both the exact formulation of the algorithm and its sample-based counterpart, where we derive high-probability guarantees and finite sample complexity. This work advances MFG optimization by bridging RL techniques with mean-field decision-making, offering a theoretically grounded approach to solving complex multi-agent problems.
Discrete Markov Probabilistic Models
Feb 11, 2025



This paper introduces the Discrete Markov Probabilistic Model (DMPM), a novel algorithm for discrete data generation. The algorithm operates in the space of bits $\{0,1\}^d$, where the noising process is a continuous-time Markov chain that can be sampled exactly via a Poissonian clock that flips labels uniformly at random. The time-reversal process, like the forward noise process, is a jump process, with its intensity governed by a discrete analogue of the classical score function. Crucially, this intensity is proven to be the conditional expectation of a function of the forward process, strengthening its theoretical alignment with score-based generative models while ensuring robustness and efficiency. We further establish convergence bounds for the algorithm under minimal assumptions and demonstrate its effectiveness through experiments on low-dimensional Bernoulli-distributed datasets and high-dimensional binary MNIST data. The results highlight its strong performance in generating discrete structures. This work bridges theoretical foundations and practical applications, advancing the development of effective and theoretically grounded discrete generative modeling.
Beyond Log-Concavity and Score Regularity: Improved Convergence Bounds for Score-Based Generative Models in W2-distance
Jan 04, 2025Score-based Generative Models (SGMs) aim to sample from a target distribution by learning score functions using samples perturbed by Gaussian noise. Existing convergence bounds for SGMs in the $\mathcal{W}_2$-distance rely on stringent assumptions about the data distribution. In this work, we present a novel framework for analyzing $\mathcal{W}_2$-convergence in SGMs, significantly relaxing traditional assumptions such as log-concavity and score regularity. Leveraging the regularization properties of the Ornstein-Uhlenbeck (OU) process, we show that weak log-concavity of the data distribution evolves into log-concavity over time. This transition is rigorously quantified through a PDE-based analysis of the Hamilton-Jacobi-Bellman equation governing the log-density of the forward process. Moreover, we establish that the drift of the time-reversed OU process alternates between contractive and non-contractive regimes, reflecting the dynamics of concavity. Our approach circumvents the need for stringent regularity conditions on the score function and its estimators, relying instead on milder, more practical assumptions. We demonstrate the wide applicability of this framework through explicit computations on Gaussian mixture models, illustrating its versatility and potential for broader classes of data distributions.
An analysis of the noise schedule for score-based generative models
Feb 07, 2024
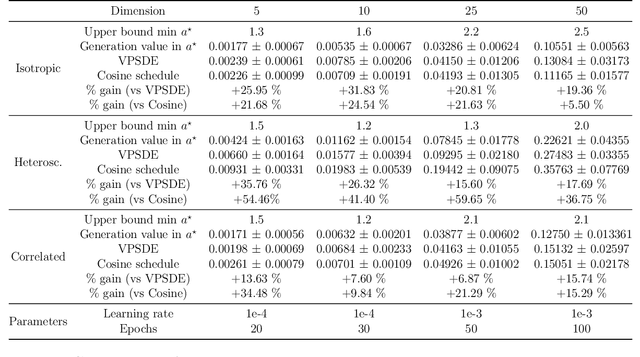
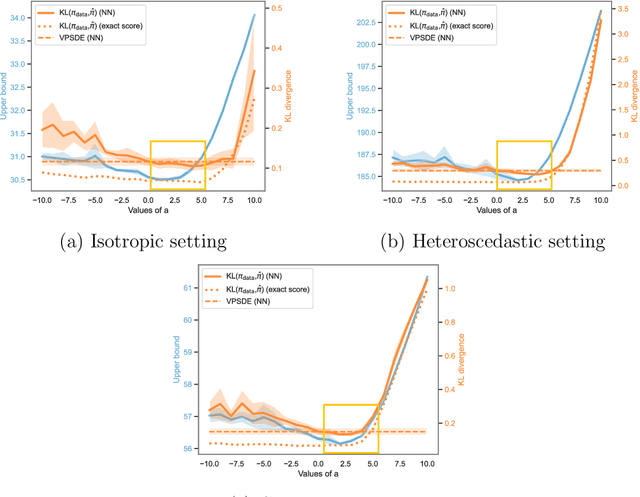
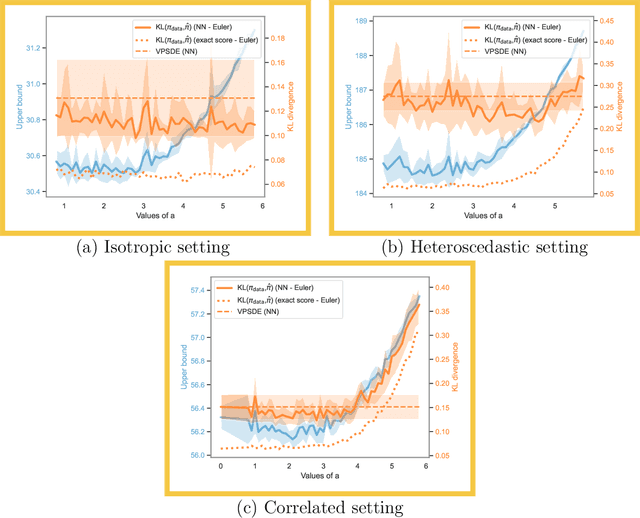
Score-based generative models (SGMs) aim at estimating a target data distribution by learning score functions using only noise-perturbed samples from the target. Recent literature has focused extensively on assessing the error between the target and estimated distributions, gauging the generative quality through the Kullback-Leibler (KL) divergence and Wasserstein distances. All existing results have been obtained so far for time-homogeneous speed of the noise schedule. Under mild assumptions on the data distribution, we establish an upper bound for the KL divergence between the target and the estimated distributions, explicitly depending on any time-dependent noise schedule. Assuming that the score is Lipschitz continuous, we provide an improved error bound in Wasserstein distance, taking advantage of favourable underlying contraction mechanisms. We also propose an algorithm to automatically tune the noise schedule using the proposed upper bound. We illustrate empirically the performance of the noise schedule optimization in comparison to standard choices in the literature.