 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBench-MFG: A Benchmark Suite for Learning in Stationary Mean Field Games
Feb 13, 2026The intersection of Mean Field Games (MFGs) and Reinforcement Learning (RL) has fostered a growing family of algorithms designed to solve large-scale multi-agent systems. However, the field currently lacks a standardized evaluation protocol, forcing researchers to rely on bespoke, isolated, and often simplistic environments. This fragmentation makes it difficult to assess the robustness, generalization, and failure modes of emerging methods. To address this gap, we propose a comprehensive benchmark suite for MFGs (Bench-MFG), focusing on the discrete-time, discrete-space, stationary setting for the sake of clarity. We introduce a taxonomy of problem classes, ranging from no-interaction and monotone games to potential and dynamics-coupled games, and provide prototypical environments for each. Furthermore, we propose MF-Garnets, a method for generating random MFG instances to facilitate rigorous statistical testing. We benchmark a variety of learning algorithms across these environments, including a novel black-box approach (MF-PSO) for exploitability minimization. Based on our extensive empirical results, we propose guidelines to standardize future experimental comparisons. Code available at \href{https://github.com/lorenzomagnino/Bench-MFG}{https://github.com/lorenzomagnino/Bench-MFG}.
Operator Learning for Families of Finite-State Mean-Field Games
Feb 13, 2026Finite-state mean-field games (MFGs) arise as limits of large interacting particle systems and are governed by an MFG system, a coupled forward-backward differential equation consisting of a forward Kolmogorov-Fokker-Planck (KFP) equation describing the population distribution and a backward Hamilton-Jacobi-Bellman (HJB) equation defining the value function. Solving MFG systems efficiently is challenging, with the structure of each system depending on an initial distribution of players and the terminal cost of the game. We propose an operator learning framework that solves parametric families of MFGs, enabling generalization without retraining for new initial distributions and terminal costs. We provide theoretical guarantees on the approximation error, parametric complexity, and generalization performance of our method, based on a novel regularity result for an appropriately defined flow map corresponding to an MFG system. We demonstrate empirically that our framework achieves accurate approximation for two representative instances of MFGs: a cybersecurity example and a high-dimensional quadratic model commonly used as a benchmark for numerical methods for MFGs.
Controlling Exploration-Exploitation in GFlowNets via Markov Chain Perspectives
Feb 03, 2026Generative Flow Network (GFlowNet) objectives implicitly fix an equal mixing of forward and backward policies, potentially constraining the exploration-exploitation trade-off during training. By further exploring the link between GFlowNets and Markov chains, we establish an equivalence between GFlowNet objectives and Markov chain reversibility, thereby revealing the origin of such constraints, and provide a framework for adapting Markov chain properties to GFlowNets. Building on these theoretical findings, we propose $α$-GFNs, which generalize the mixing via a tunable parameter $α$. This generalization enables direct control over exploration-exploitation dynamics to enhance mode discovery capabilities, while ensuring convergence to unique flows. Across various benchmarks, including Set, Bit Sequence, and Molecule Generation, $α$-GFN objectives consistently outperform previous GFlowNet objectives, achieving up to a $10 \times$ increase in the number of discovered modes.
Clustering in Deep Stochastic Transformers
Jan 29, 2026Transformers have revolutionized deep learning across various domains but understanding the precise token dynamics remains a theoretical challenge. Existing theories of deep Transformers with layer normalization typically predict that tokens cluster to a single point; however, these results rely on deterministic weight assumptions, which fail to capture the standard initialization scheme in Transformers. In this work, we show that accounting for the intrinsic stochasticity of random initialization alters this picture. More precisely, we analyze deep Transformers where noise arises from the random initialization of value matrices. Under diffusion scaling and token-wise RMS normalization, we prove that, as the number of Transformer layers goes to infinity, the discrete token dynamics converge to an interacting-particle system on the sphere where tokens are driven by a \emph{common} matrix-valued Brownian noise. In this limit, we show that initialization noise prevents the collapse to a single cluster predicted by deterministic models. For two tokens, we prove a phase transition governed by the interaction strength and the token dimension: unlike deterministic attention flows, antipodal configurations become attracting with positive probability. Numerical experiments confirm the predicted transition, reveal that antipodal formations persist for more than two tokens, and demonstrate that suppressing the intrinsic noise degrades accuracy.
Deep Learning for the Multiple Optimal Stopping Problem
Dec 28, 2025This paper presents a novel deep learning framework for solving multiple optimal stopping problems in high dimensions. While deep learning has recently shown promise for single stopping problems, the multiple exercise case involves complex recursive dependencies that remain challenging. We address this by combining the Dynamic Programming Principle with neural network approximation of the value function. Unlike policy-search methods, our algorithm explicitly learns the value surface. We first consider the discrete-time problem and analyze neural network training error. We then turn to continuous problems and analyze the additional error due to the discretization of the underlying stochastic processes. Numerical experiments on high-dimensional American basket options and nonlinear utility maximization demonstrate that our method provides an efficient and scalable method for the multiple optimal stopping problem.
Convergence of Actor-Critic Learning for Mean Field Games and Mean Field Control in Continuous Spaces
Nov 10, 2025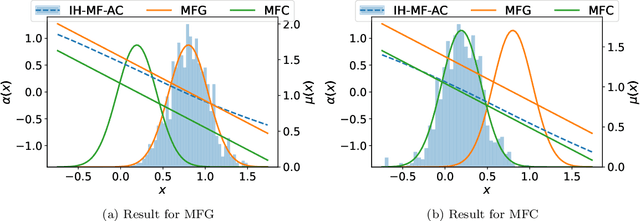



We establish the convergence of the deep actor-critic reinforcement learning algorithm presented in [Angiuli et al., 2023a] in the setting of continuous state and action spaces with an infinite discrete-time horizon. This algorithm provides solutions to Mean Field Game (MFG) or Mean Field Control (MFC) problems depending on the ratio between two learning rates: one for the value function and the other for the mean field term. In the MFC case, to rigorously identify the limit, we introduce a discretization of the state and action spaces, following the approach used in the finite-space case in [Angiuli et al., 2023b]. The convergence proofs rely on a generalization of the two-timescale framework introduced in [Borkar, 1997]. We further extend our convergence results to Mean Field Control Games, which involve locally cooperative and globally competitive populations. Finally, we present numerical experiments for linear-quadratic problems in one and two dimensions, for which explicit solutions are available.
Finite-Sample Convergence Bounds for Trust Region Policy Optimization in Mean-Field Games
May 28, 2025We introduce Mean-Field Trust Region Policy Optimization (MF-TRPO), a novel algorithm designed to compute approximate Nash equilibria for ergodic Mean-Field Games (MFG) in finite state-action spaces. Building on the well-established performance of TRPO in the reinforcement learning (RL) setting, we extend its methodology to the MFG framework, leveraging its stability and robustness in policy optimization. Under standard assumptions in the MFG literature, we provide a rigorous analysis of MF-TRPO, establishing theoretical guarantees on its convergence. Our results cover both the exact formulation of the algorithm and its sample-based counterpart, where we derive high-probability guarantees and finite sample complexity. This work advances MFG optimization by bridging RL techniques with mean-field decision-making, offering a theoretically grounded approach to solving complex multi-agent problems.
Deep Learning Algorithms for Mean Field Optimal Stopping in Finite Space and Discrete Time
Oct 11, 2024Optimal stopping is a fundamental problem in optimization that has found applications in risk management, finance, economics, and recently in the fields of computer science. We extend the standard framework to a multi-agent setting, named multi-agent optimal stopping (MAOS), where a group of agents cooperatively solves finite-space, discrete-time optimal stopping problems. Solving the finite-agent case is computationally prohibitive when the number of agents is very large, so this work studies the mean field optimal stopping (MFOS) problem, obtained as the number of agents approaches infinity. We prove that MFOS provides a good approximate solution to MAOS. We also prove a dynamic programming principle (DPP), based on the theory of mean field control. We then propose two deep learning methods: one simulates full trajectories to learn optimal decisions, whereas the other leverages DPP with backward induction; both methods train neural networks for the optimal stopping decisions. We demonstrate the effectiveness of these approaches through numerical experiments on 6 different problems in spatial dimension up to 300. To the best of our knowledge, this is the first work to study MFOS in finite space and discrete time, and to propose efficient and scalable computational methods for this type of problem.
Reinforcement Learning for Finite Space Mean-Field Type Games
Sep 25, 2024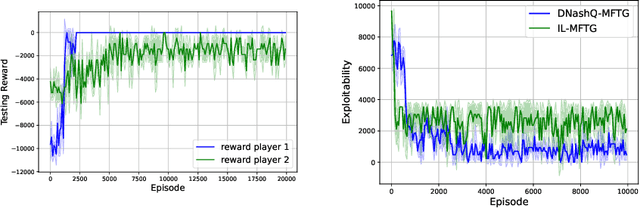

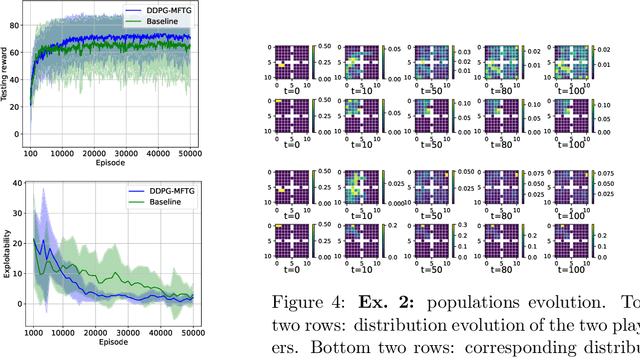
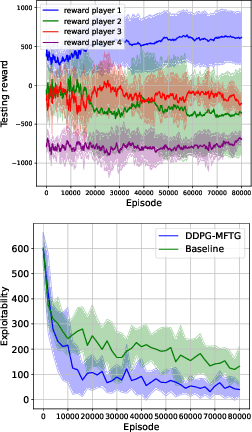
Mean field type games (MFTGs) describe Nash equilibria between large coalitions: each coalition consists of a continuum of cooperative agents who maximize the average reward of their coalition while interacting non-cooperatively with a finite number of other coalitions. Although the theory has been extensively developed, we are still lacking efficient and scalable computational methods. Here, we develop reinforcement learning methods for such games in a finite space setting with general dynamics and reward functions. We start by proving that MFTG solution yields approximate Nash equilibria in finite-size coalition games. We then propose two algorithms. The first is based on quantization of the mean-field spaces and Nash Q-learning. We provide convergence and stability analysis. We then propose an deep reinforcement learning algorithm, which can scale to larger spaces. Numerical examples on 5 environments show the scalability and the efficiency of the proposed method.
Global Solutions to Master Equations for Continuous Time Heterogeneous Agent Macroeconomic Models
Jun 19, 2024



We propose and compare new global solution algorithms for continuous time heterogeneous agent economies with aggregate shocks. First, we approximate the agent distribution so that equilibrium in the economy can be characterized by a high, but finite, dimensional non-linear partial differential equation. We consider different approximations: discretizing the number of agents, discretizing the agent state variables, and projecting the distribution onto a finite set of basis functions. Second, we represent the value function using a neural network and train it to solve the differential equation using deep learning tools. We refer to the solution as an Economic Model Informed Neural Network (EMINN). The main advantage of this technique is that it allows us to find global solutions to high dimensional, non-linear problems. We demonstrate our algorithm by solving important models in the macroeconomics and spatial literatures (e.g. Krusell and Smith (1998), Khan and Thomas (2007), Bilal (2023)).