 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Optimization for Amortized Discrete Sampling
Jun 14, 2026This paper explores policy gradient algorithms for training stochastic policies to sample from structured discrete probability distributions under the Generative Flow Network (GFlowNet) framework. Building on extensive theoretical connections between GFlowNets and entropy-regularized reinforcement learning, we derive equivalents of standard policy gradient algorithms for training GFlowNets, as well as experimentally explore their various methodological aspects, including baseline training and advantage estimation. Most importantly, our work is the first to derive and successfully apply proximal policy optimization to GFlowNets, showing its improved convergence speed and data efficiency compared to standard GFlowNet training objectives on benchmarks ranging from synthetic energies to molecular graph generation.
Refined Analysis of Entropy-Regularized Actor-Critic
May 23, 2026In this paper, we study the role of the critic in actor--critic for entropy-regularized, finite, discounted environments. We establish that, when the critic is exact, using the latter as a baseline is a variance-reduction method in a strong sense. In this case, actor--critic with stochastic gradients matches the sample complexity of deterministic policy gradient, reaching an $ε$-optimal regularized value with $\tilde{O}(\log(1/ε))$ samples. In practice, the critic is learned alongside the actor: the variance of the actor update is then influenced by the critic's variance and bias. Specifically, when the critic has a sufficiently small error, the variance reduction and rapid convergence are preserved. This suggests to learn the critic first, keeping it up to date after each actor update, underscoring the crucial role of accurate critic estimation in actor--critic methods.
Learning Shortest Paths with Generative Flow Networks
Mar 02, 2026In this paper, we present a novel learning framework for finding shortest paths in graphs utilizing Generative Flow Networks (GFlowNets). First, we examine theoretical properties of GFlowNets in non-acyclic environments in relation to shortest paths. We prove that, if the total flow is minimized, forward and backward policies traverse the environment graph exclusively along shortest paths between the initial and terminal states. Building on this result, we show that the pathfinding problem in an arbitrary graph can be solved by training a non-acyclic GFlowNet with flow regularization. We experimentally demonstrate the performance of our method in pathfinding in permutation environments and in solving Rubik's Cubes. For the latter problem, our approach shows competitive results with state-of-the-art machine learning approaches designed specifically for this task in terms of the solution length, while requiring smaller search budget at test-time.
Beyond Softmax and Entropy: Improving Convergence Guarantees of Policy Gradients by f-SoftArgmax Parameterization with Coupled Regularization
Jan 18, 2026Policy gradient methods are known to be highly sensitive to the choice of policy parameterization. In particular, the widely used softmax parameterization can induce ill-conditioned optimization landscapes and lead to exponentially slow convergence. Although this can be mitigated by preconditioning, this solution is often computationally expensive. Instead, we propose replacing the softmax with an alternative family of policy parameterizations based on the generalized f-softargmax. We further advocate coupling this parameterization with a regularizer induced by the same f-divergence, which improves the optimization landscape and ensures that the resulting regularized objective satisfies a Polyak-Lojasiewicz inequality. Leveraging this structure, we establish the first explicit non-asymptotic last-iterate convergence guarantees for stochastic policy gradient methods for finite MDPs without any form of preconditioning. We also derive sample-complexity bounds for the unregularized problem and show that f-PG, with Tsallis divergences achieves polynomial sample complexity in contrast to the exponential complexity incurred by the standard softmax parameterization.
On Global Convergence Rates for Federated Policy Gradient under Heterogeneous Environment
May 29, 2025



Ensuring convergence of policy gradient methods in federated reinforcement learning (FRL) under environment heterogeneity remains a major challenge. In this work, we first establish that heterogeneity, perhaps counter-intuitively, can necessitate optimal policies to be non-deterministic or even time-varying, even in tabular environments. Subsequently, we prove global convergence results for federated policy gradient (FedPG) algorithms employing local updates, under a {\L}ojasiewicz condition that holds only for each individual agent, in both entropy-regularized and non-regularized scenarios. Crucially, our theoretical analysis shows that FedPG attains linear speed-up with respect to the number of agents, a property central to efficient federated learning. Leveraging insights from our theoretical findings, we introduce b-RS-FedPG, a novel policy gradient method that employs a carefully constructed softmax-inspired parameterization coupled with an appropriate regularization scheme. We further demonstrate explicit convergence rates for b-RS-FedPG toward near-optimal stationary policies. Finally, we demonstrate that empirically both FedPG and b-RS-FedPG consistently outperform federated Q-learning on heterogeneous settings.
Finite-Sample Convergence Bounds for Trust Region Policy Optimization in Mean-Field Games
May 28, 2025We introduce Mean-Field Trust Region Policy Optimization (MF-TRPO), a novel algorithm designed to compute approximate Nash equilibria for ergodic Mean-Field Games (MFG) in finite state-action spaces. Building on the well-established performance of TRPO in the reinforcement learning (RL) setting, we extend its methodology to the MFG framework, leveraging its stability and robustness in policy optimization. Under standard assumptions in the MFG literature, we provide a rigorous analysis of MF-TRPO, establishing theoretical guarantees on its convergence. Our results cover both the exact formulation of the algorithm and its sample-based counterpart, where we derive high-probability guarantees and finite sample complexity. This work advances MFG optimization by bridging RL techniques with mean-field decision-making, offering a theoretically grounded approach to solving complex multi-agent problems.
Accelerating Nash Learning from Human Feedback via Mirror Prox
May 26, 2025Traditional Reinforcement Learning from Human Feedback (RLHF) often relies on reward models, frequently assuming preference structures like the Bradley-Terry model, which may not accurately capture the complexities of real human preferences (e.g., intransitivity). Nash Learning from Human Feedback (NLHF) offers a more direct alternative by framing the problem as finding a Nash equilibrium of a game defined by these preferences. In this work, we introduce Nash Mirror Prox ($\mathtt{Nash-MP}$), an online NLHF algorithm that leverages the Mirror Prox optimization scheme to achieve fast and stable convergence to the Nash equilibrium. Our theoretical analysis establishes that Nash-MP exhibits last-iterate linear convergence towards the $\beta$-regularized Nash equilibrium. Specifically, we prove that the KL-divergence to the optimal policy decreases at a rate of order $(1+2\beta)^{-N/2}$, where $N$ is a number of preference queries. We further demonstrate last-iterate linear convergence for the exploitability gap and uniformly for the span semi-norm of log-probabilities, with all these rates being independent of the size of the action space. Furthermore, we propose and analyze an approximate version of Nash-MP where proximal steps are estimated using stochastic policy gradients, making the algorithm closer to applications. Finally, we detail a practical implementation strategy for fine-tuning large language models and present experiments that demonstrate its competitive performance and compatibility with existing methods.
Revisiting Non-Acyclic GFlowNets in Discrete Environments
Feb 11, 2025

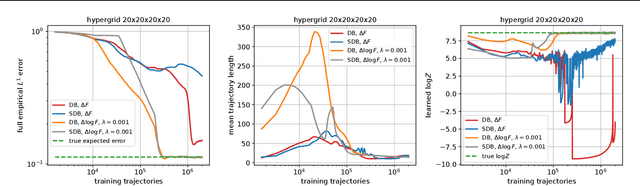

Generative Flow Networks (GFlowNets) are a family of generative models that learn to sample objects from a given probability distribution, potentially known up to a normalizing constant. Instead of working in the object space, GFlowNets proceed by sampling trajectories in an appropriately constructed directed acyclic graph environment, greatly relying on the acyclicity of the graph. In our paper, we revisit the theory that relaxes the acyclicity assumption and present a simpler theoretical framework for non-acyclic GFlowNets in discrete environments. Moreover, we provide various novel theoretical insights related to training with fixed backward policies, the nature of flow functions, and connections between entropy-regularized RL and non-acyclic GFlowNets, which naturally generalize the respective concepts and theoretical results from the acyclic setting. In addition, we experimentally re-examine the concept of loss stability in non-acyclic GFlowNet training, as well as validate our own theoretical findings.
On Teacher Hacking in Language Model Distillation
Feb 04, 2025



Post-training of language models (LMs) increasingly relies on the following two stages: (i) knowledge distillation, where the LM is trained to imitate a larger teacher LM, and (ii) reinforcement learning from human feedback (RLHF), where the LM is aligned by optimizing a reward model. In the second RLHF stage, a well-known challenge is reward hacking, where the LM over-optimizes the reward model. Such phenomenon is in line with Goodhart's law and can lead to degraded performance on the true objective. In this paper, we investigate whether a similar phenomenon, that we call teacher hacking, can occur during knowledge distillation. This could arise because the teacher LM is itself an imperfect approximation of the true distribution. To study this, we propose a controlled experimental setup involving: (i) an oracle LM representing the ground-truth distribution, (ii) a teacher LM distilled from the oracle, and (iii) a student LM distilled from the teacher. Our experiments reveal the following insights. When using a fixed offline dataset for distillation, teacher hacking occurs; moreover, we can detect it by observing when the optimization process deviates from polynomial convergence laws. In contrast, employing online data generation techniques effectively mitigates teacher hacking. More precisely, we identify data diversity as the key factor in preventing hacking. Overall, our findings provide a deeper understanding of the benefits and limitations of distillation for building robust and efficient LMs.
Federated UCBVI: Communication-Efficient Federated Regret Minimization with Heterogeneous Agents
Oct 30, 2024


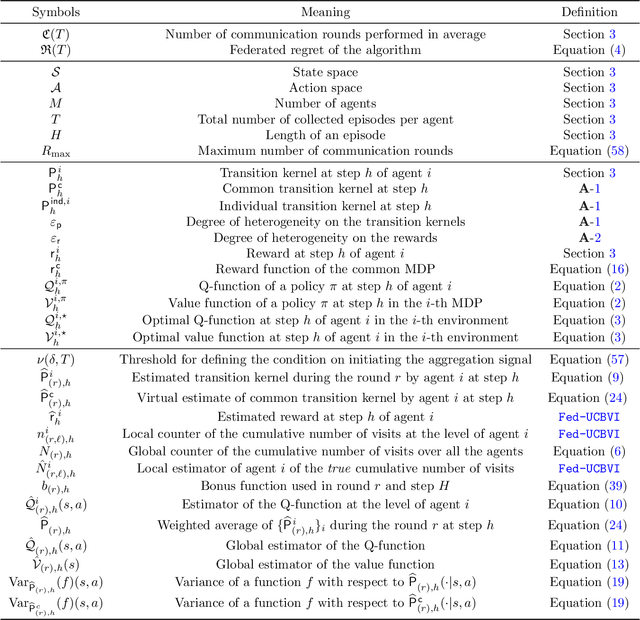
In this paper, we present the Federated Upper Confidence Bound Value Iteration algorithm ($\texttt{Fed-UCBVI}$), a novel extension of the $\texttt{UCBVI}$ algorithm (Azar et al., 2017) tailored for the federated learning framework. We prove that the regret of $\texttt{Fed-UCBVI}$ scales as $\tilde{\mathcal{O}}(\sqrt{H^3 |\mathcal{S}| |\mathcal{A}| T / M})$, with a small additional term due to heterogeneity, where $|\mathcal{S}|$ is the number of states, $|\mathcal{A}|$ is the number of actions, $H$ is the episode length, $M$ is the number of agents, and $T$ is the number of episodes. Notably, in the single-agent setting, this upper bound matches the minimax lower bound up to polylogarithmic factors, while in the multi-agent scenario, $\texttt{Fed-UCBVI}$ has linear speed-up. To conduct our analysis, we introduce a new measure of heterogeneity, which may hold independent theoretical interest. Furthermore, we show that, unlike existing federated reinforcement learning approaches, $\texttt{Fed-UCBVI}$'s communication complexity only marginally increases with the number of agents.