 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Shortest Paths with Generative Flow Networks
Mar 02, 2026In this paper, we present a novel learning framework for finding shortest paths in graphs utilizing Generative Flow Networks (GFlowNets). First, we examine theoretical properties of GFlowNets in non-acyclic environments in relation to shortest paths. We prove that, if the total flow is minimized, forward and backward policies traverse the environment graph exclusively along shortest paths between the initial and terminal states. Building on this result, we show that the pathfinding problem in an arbitrary graph can be solved by training a non-acyclic GFlowNet with flow regularization. We experimentally demonstrate the performance of our method in pathfinding in permutation environments and in solving Rubik's Cubes. For the latter problem, our approach shows competitive results with state-of-the-art machine learning approaches designed specifically for this task in terms of the solution length, while requiring smaller search budget at test-time.
Revisiting Non-Acyclic GFlowNets in Discrete Environments
Feb 11, 2025


Generative Flow Networks (GFlowNets) are a family of generative models that learn to sample objects from a given probability distribution, potentially known up to a normalizing constant. Instead of working in the object space, GFlowNets proceed by sampling trajectories in an appropriately constructed directed acyclic graph environment, greatly relying on the acyclicity of the graph. In our paper, we revisit the theory that relaxes the acyclicity assumption and present a simpler theoretical framework for non-acyclic GFlowNets in discrete environments. Moreover, we provide various novel theoretical insights related to training with fixed backward policies, the nature of flow functions, and connections between entropy-regularized RL and non-acyclic GFlowNets, which naturally generalize the respective concepts and theoretical results from the acyclic setting. In addition, we experimentally re-examine the concept of loss stability in non-acyclic GFlowNet training, as well as validate our own theoretical findings.
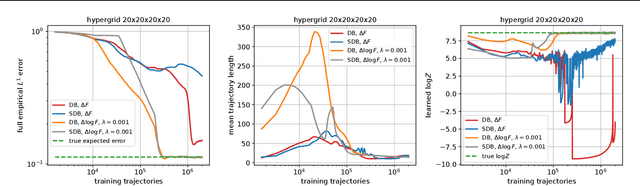
Optimizing Backward Policies in GFlowNets via Trajectory Likelihood Maximization
Oct 20, 2024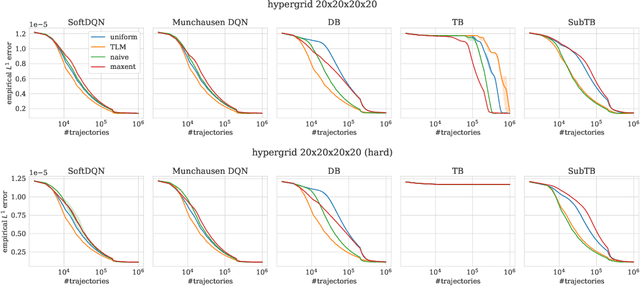
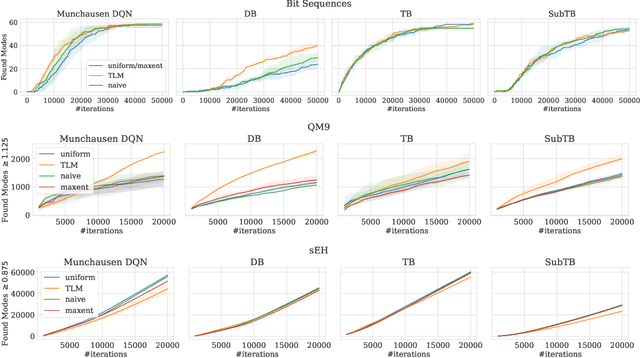
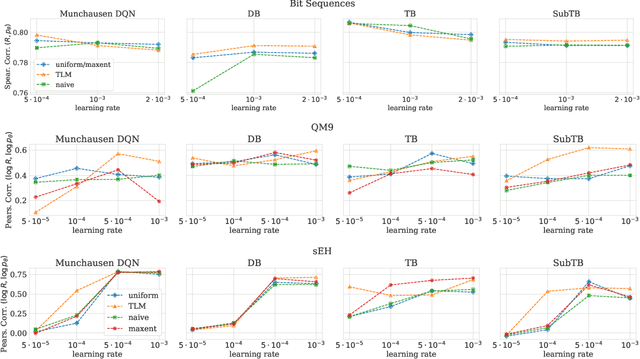
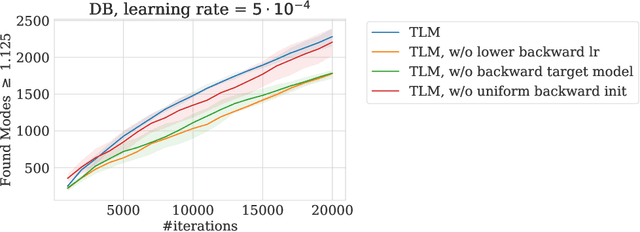
Generative Flow Networks (GFlowNets) are a family of generative models that learn to sample objects with probabilities proportional to a given reward function. The key concept behind GFlowNets is the use of two stochastic policies: a forward policy, which incrementally constructs compositional objects, and a backward policy, which sequentially deconstructs them. Recent results show a close relationship between GFlowNet training and entropy-regularized reinforcement learning (RL) problems with a particular reward design. However, this connection applies only in the setting of a fixed backward policy, which might be a significant limitation. As a remedy to this problem, we introduce a simple backward policy optimization algorithm that involves direct maximization of the value function in an entropy-regularized Markov Decision Process (MDP) over intermediate rewards. We provide an extensive experimental evaluation of the proposed approach across various benchmarks in combination with both RL and GFlowNet algorithms and demonstrate its faster convergence and mode discovery in complex environments.
Improving GFlowNets with Monte Carlo Tree Search
Jun 19, 2024Generative Flow Networks (GFlowNets) treat sampling from distributions over compositional discrete spaces as a sequential decision-making problem, training a stochastic policy to construct objects step by step. Recent studies have revealed strong connections between GFlowNets and entropy-regularized reinforcement learning. Building on these insights, we propose to enhance planning capabilities of GFlowNets by applying Monte Carlo Tree Search (MCTS). Specifically, we show how the MENTS algorithm (Xiao et al., 2019) can be adapted for GFlowNets and used during both training and inference. Our experiments demonstrate that this approach improves the sample efficiency of GFlowNet training and the generation fidelity of pre-trained GFlowNet models.
Generative Flow Networks as Entropy-Regularized RL
Oct 23, 2023



The recently proposed generative flow networks (GFlowNets) are a method of training a policy to sample compositional discrete objects with probabilities proportional to a given reward via a sequence of actions. GFlowNets exploit the sequential nature of the problem, drawing parallels with reinforcement learning (RL). Our work extends the connection between RL and GFlowNets to a general case. We demonstrate how the task of learning a generative flow network can be efficiently redefined as an entropy-regularized RL problem with a specific reward and regularizer structure. Furthermore, we illustrate the practical efficiency of this reformulation by applying standard soft RL algorithms to GFlowNet training across several probabilistic modeling tasks. Contrary to previously reported results, we show that entropic RL approaches can be competitive against established GFlowNet training methods. This perspective opens a direct path for integrating reinforcement learning principles into the realm of generative flow networks.
Weight Averaging Improves Knowledge Distillation under Domain Shift
Sep 20, 2023Knowledge distillation (KD) is a powerful model compression technique broadly used in practical deep learning applications. It is focused on training a small student network to mimic a larger teacher network. While it is widely known that KD can offer an improvement to student generalization in i.i.d setting, its performance under domain shift, i.e. the performance of student networks on data from domains unseen during training, has received little attention in the literature. In this paper we make a step towards bridging the research fields of knowledge distillation and domain generalization. We show that weight averaging techniques proposed in domain generalization literature, such as SWAD and SMA, also improve the performance of knowledge distillation under domain shift. In addition, we propose a simplistic weight averaging strategy that does not require evaluation on validation data during training and show that it performs on par with SWAD and SMA when applied to KD. We name our final distillation approach Weight-Averaged Knowledge Distillation (WAKD).
Differentiable Rendering with Reparameterized Volume Sampling
Feb 21, 2023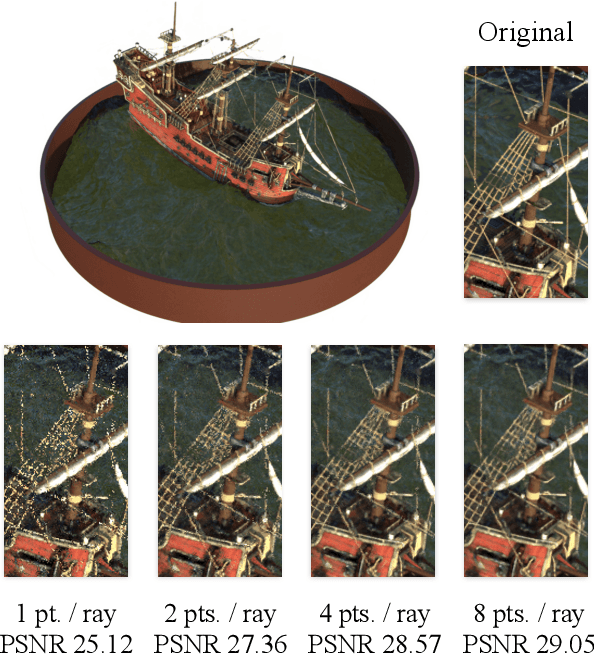
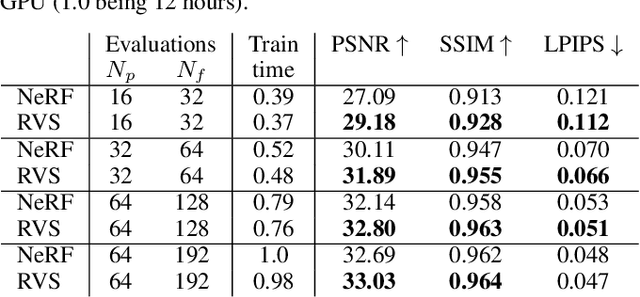
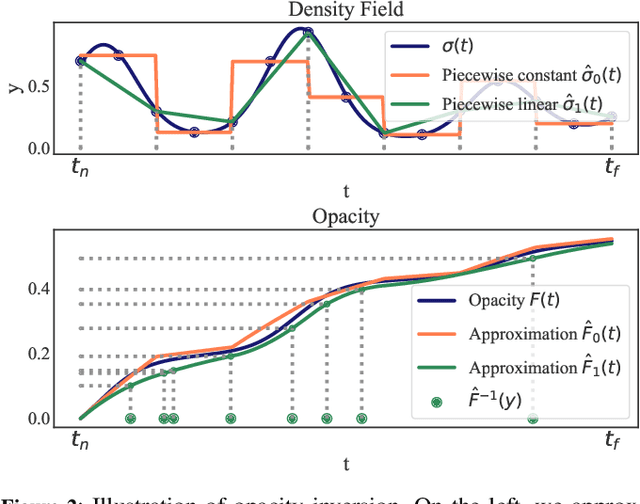
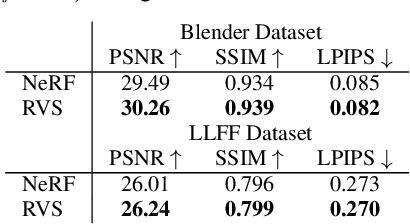
In view synthesis, a neural radiance field approximates underlying density and radiance fields based on a sparse set of scene pictures. To generate a pixel of a novel view, it marches a ray through the pixel and computes a weighted sum of radiance emitted from a dense set of ray points. This rendering algorithm is fully differentiable and facilitates gradient-based optimization of the fields. However, in practice, only a tiny opaque portion of the ray contributes most of the radiance to the sum. We propose an end-to-end differentiable sampling algorithm based on inverse transform sampling. It generates samples according to the probability distribution induced by the density field and picks non-transparent points on the ray. We utilize the algorithm in two ways. First, we propose a novel rendering approach based on Monte Carlo estimates. Such a rendering algorithm allows for optimizing a neural radiance field with just a few radiance field evaluations per ray. Second, we use the sampling algorithm to modify the hierarchical scheme used in the original work on neural radiance fields. In this setup, we were able to train the proposal network end-to-end without any auxiliary losses and improved the baseline performance.